 1188
1188 
Чем полезны новые фичи Apache Spark SQL, выпущенные в релизе 3.4. Разбираемся с псевдонимами столбцов и параметризованными SQL-запросами на простых примерах, запуская Spark-приложение в Google Colab.
Псевдонимы столбцов
Хотя с момента выхода Apache Spark 3.4 в апреле 2023 года, о чем мы писали здесь, прошло почти полгода, возможность ссылаться на псевдонимы столбцов при выполнении SQL-запросов, а также делать запросы параметризованными, до сих пор считаются новыми. Псевдонимы (алиасы) столбцов представляют собой простой прием, который ускоряет написание SQL-запроса. Объявить псевдоним можно как для таблицы, так и для столбца, используя ключевое слово AS, например:
SELECT column_name AS alias_name FROM table_name;
Напомним, псевдоним существует только на время выполнения SQL-запроса и представляет собой временное имя. Эта функция позволяет разработчикам писать запросы, которые ссылаются на псевдоним столбца в том же запросе сразу после его объявления, улучшая читаемость сложных SQL-запросов.
При реализации этой новой фичи разработчики Apache Spark вдохновлялись функцией lateral column alias references, которая есть в Amazon Redshift, чтобы писать SQL-запросы, не повторяя одни и те же выражения в SELECT. Например, определить псевдоним «вероятность» (probability) и использовать его в том же операторе SELECT:
SELECT clicks / impressions AS probability, round(100 * probability, 1) AS percentage FROM table_data;
При выполнении запроса Amazon Redshift просто встраивает ранее определенные псевдонимы. Если в предложении FROM определен столбец с тем же именем, что и у выражения с ранее заданным псевдонимом, столбец в предложении FROM имеет приоритет. Например, в приведенном выше запросе, если в таблице table_data есть столбец «вероятность» (probability) во втором выражении в целевом списке будет ссылаться на этот столбец, а не на псевдоним «вероятность» (probability).
Посмотрим, как это работает, создав датафрейм PySpark в интерактивной среде Google Colab. Сперва установим необходимые библиотеки и модули:
!pip install pyspark !pip install faker #импорт модулей from pyspark.sql import SparkSession import pyspark import sys import os import random os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64" # Импорт модуля faker from faker import Faker from faker.providers.address.ru_RU import Provider
Затем создадим приложение и датафрейм с данными о клиентах банка, сгенерированных с помощью библиотеки Faker:
# Создаем объект SparkSession и устанавливаем имя приложения
spark = SparkSession.builder.appName("MySparkApp").getOrCreate()
# Import and configure random data generator Faker
fake = Faker('ru_RU')
fake.add_provider(Provider)
# Create empty list to store generated data
data1 = []
# Generate data and add to list
for i in range(100):
k= random.randint(0, 1)
name = fake.name()
data1.append((i, name, random.randint(18, 100), random.randint(0, 100),random.randint(0, 100)))
#Create dataframe from data list
df = spark.createDataFrame(data1, schema=['id', 'Client', 'age', 'income', 'debt'])
Найдем самых закредитованных клиентов старше 50 лет, используя псевдонимы столбцов. Для этого сперва создадим временное представление своего датафрейма, чтобы оперировать с ним как с таблицей средствами Spark SQL. С помощью ключевого слова AS определен столбец с названием debt_to_income, на который можно ссылаться непосредственно в SQL-запросе.
try:
# Create temp view
df.createTempView('my_df')
except:
pass
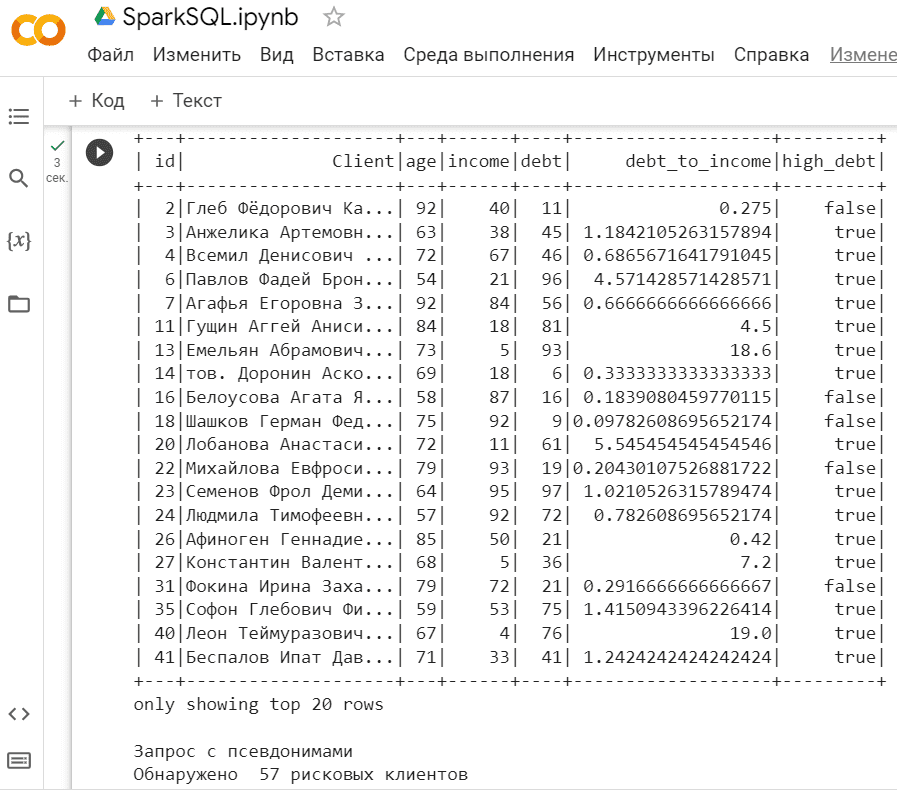
indebt_people = spark.sql("SELECT *, my_df.debt/my_df.income AS debt_to_income, debt_to_income > 0.3 AS high_debt FROM my_df WHERE my_df.age>50")
indebt_people.show()
print("Запрос с псевдонимами")
print("Обнаружено ", indebt_people.count(), "рисковых клиентов")
Результат выполнения SQL-запроса визуализируется в области вывода с помощью функции show()
Использовать псевдоним в условии WHERE нельзя, Spark не распознает его и приводит к ошибке, выдавая исключение
pyspark.errors.exceptions.captured.AnalysisException: [UNRESOLVED_COLUMN.WITH_SUGGESTION]
Параметризованные SQL-запросы в Apache Spark
Использование параметров в SQL-запросе позволяет указывать необязательные аргументы ключевого слова переменной длины в качестве дополнительных фильтров. Это полезно, когда надо создать запрос и использовать его многократно, но каждый раз с разными значениями. Для этого используются параметры запроса, т.е. заполнители для значений, которые предоставляется при запуске запроса с помощью спецсимвола.
Параметры можно использовать как метки-заполнители для литеральных значений — текстовых или числовых. Особенно часто параметры используются в качестве меток-заполнителей в условиях поиска отдельных строк или групп строк, т.е. в условиях WHERE и HAVING.
Параметр можно использовать в качестве меток-заполнителей в выражениях. Например, можно вычислять цены со скидками, предоставляя различное значение скидки при каждом запуске запроса. Будучи переменной SQL-оператора, параметр позволяет формировать его непосредственно во время выполнения приложения. Поскольку процесс компиляции и выполнения SQL-оператора происходит последовательно, достаточно откомпилировать SQL-оператор с параметрами вместо явного указания значений полей таблицы базы данных, а затем многократно выполнять этот оператор с различными значениями параметров.
Различают два типа параметров SQL-запроса: неименованные и именованные. Неименованный параметр представляет собой спецсимвол, который можно подставлять в любое место запроса, чтобы запросить соответствующее литеральное значение. В Apache Spark это фигурные скобки.
Можно также присвоить имя параметру, что упрощает понимание кода, когда в запросе используется несколько параметров. Название именованного параметра помечается специальным символом, например, в Apache Spark это знак двоеточия.
Сделаем аналогичный запрос по поиску самых закредитованных клиентов старше 50 лет с параметрами.
indebt_people_param = spark.sql("SELECT * FROM {df} WHERE age > {age} and (debt/income) >= {debt_to_income}", df=df, age=50, debt_to_income=0.3
Примечательно, что оба запроса выдают разные результаты после выполнения кода:
indebt_people = spark.sql("SELECT *, my_df.debt/my_df.income AS debt_to_income, debt_to_income > 0.3 AS high_debt FROM my_df WHERE my_df.age>50")
indebt_people.show()
print("Запрос с псевдонимами")
print("Обнаружено ", indebt_people.count(), "рисковых клиентов")
indebt_people_param = spark.sql("SELECT * FROM {df} WHERE age > {age} and (debt/income) >= {debt_to_income}", df=df, age=50, debt_to_income=0.3)
indebt_people_param.show()
print("Запрос с параметрами")
print("Обнаружено ", indebt_people_param.count(), "рисковых клиентов")
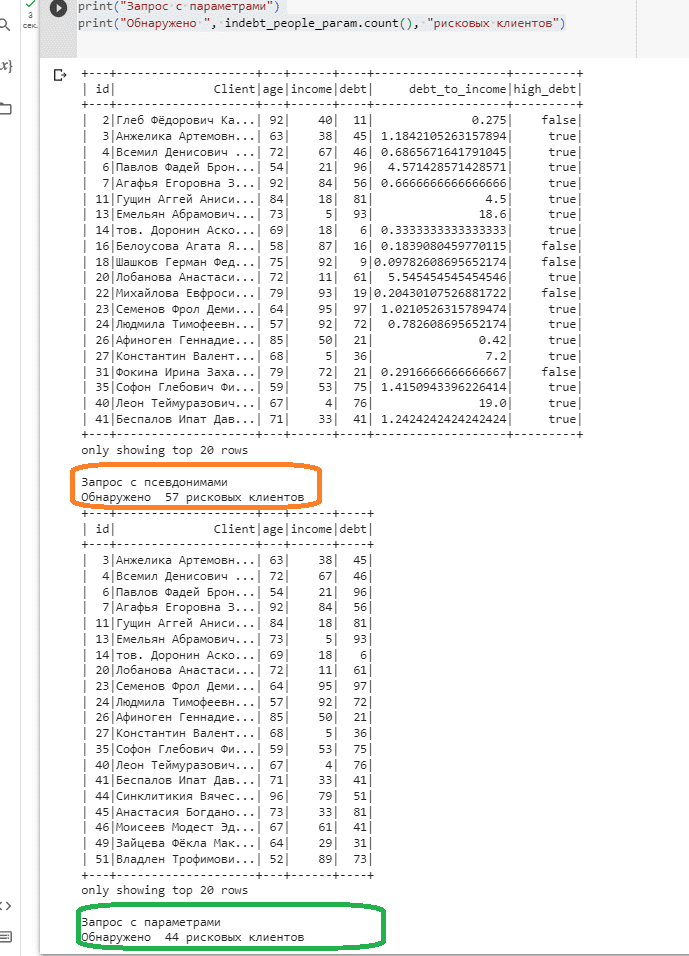
Это происходит потому, что первый запрос (с псевдонимами) вычисляет отношение долга к доходу, используя выражение столбца my_df.debt/my_df.income AS debt_to_income. А второй запрос (с параметрами) передает отношение долга к доходу в качестве параметра (debt/income) >= {debt_to_income}. Поэтому фактические расчетные коэффициенты являются разными.
Кроме того, первый запрос фильтрует my_df.age > 50, а второй фильтрует age > {age}, где {age} — параметр, равный 50. Имена столбцов также разрешаются по-разному: в первом запросе выполняется поиск столбца возраста из таблицы my_df, а во втором запросе выполняется поиск общего столбца возраста.
Также запрос с псевдонимами добавляет столбец high_debt, указывающий, превышает ли отношение долга к доходу 0,3, а параметризованный запрос фильтрует данные только при отношении долга к доходу, превышающем 0,3.
Таким образом, соотношение долга к доходу рассчитывается по-разному, фильтры возраста используют разные имена столбцов и в запросе с псевдонимами есть дополнительный столбец high_debt.
Читайте в нашей новой статье, как как искать, заменять и фильтровать строковые данные в PySpark с помощью регулярных выражений.
Освойте возможности Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
[elementor-template id=»13619″]
Источники

