
Как прочитать данные из ClickHouse в Apache NiFi или загрузить их в таблицу колоночной СУБД: настройки подключения, использование процессоров и тонкости потоковой интеграции.
Подключение к ClickHouse из Apache NiFi
Как и интеграция ClickHouse с Apache AirFlow, связь этой колоночной СУБД с приложением NiFi реализуется с помощью решения сообщества, средствами самого NiFi. Чтобы подключиться к ClickHouse из Apache NiFi, нужен JDBC-драйвер ClickHouse и служба контроллера пула подключений к базам данных DBCPConnectionPool Controller Service в NiFi. А исполнение SQL-запросов, т.е. вставок или выборки данных в таблицах ClickHouse выполняется в интерфейсе Apache NiFi с помощью процессоров PutDatabaseRecord или ExecuteSQL соответственно.
Поскольку Apache NiFi является Java-приложением, при интеграции его с Clickhouse для автоматизации потоковых ETL-процессов, следует вспомнить, как вообще можно связать эту колоночную СУБД с Java-приложениями. Чаще всего для этого используется JDBC-драйвер Clickhouse – Java-библиотека для подключения к ClickHouse и обработки данных в различных форматах. Вообще есть 3 варианта подключения к ClickHouse с помощью Java: Java-клиент, JDBC-драйвер, и драйвер R2DBC. Java-клиент считается наиболее гибким и эффективным способ интеграции Java-приложения с ClickHouse. Драйвер clickhouse-jdbc реализует стандартный интерфейс JDBC. Будучи построенным на основе clickhouse-client, он предоставляет дополнительные функции, такие как настраиваемое сопоставление типов, поддержку транзакций, стандартные синхронные операции, операторы UPDATEи DELETE и пр. Поэтому его можно использовать с устаревшими приложениями и инструментами. API JDBC-драйвера Clickhouse является синхронным и имеет больше накладных расходов по сравнению с Java-клиентом. Драйвер R2DBC (Reactive Relational Database Connectivity) представляет собой оболочку асинхронного Java-клиента для ClickHouse. Он основан на спецификации Reactive Streams, которая предоставляет полностью реактивный неблокирующий API для работы с реляционными базами данных. В отличие от блокирующего характера JDBC, R2DBC позволяет работать с РСУБД, используя реактивный API и мощное масштабирование. R2DBC является открытой спецификацией и устанавливает интерфейс поставщика услуг (SPI, Service Provider Interface) для реализации провайдерами драйверов и использования клиентами.
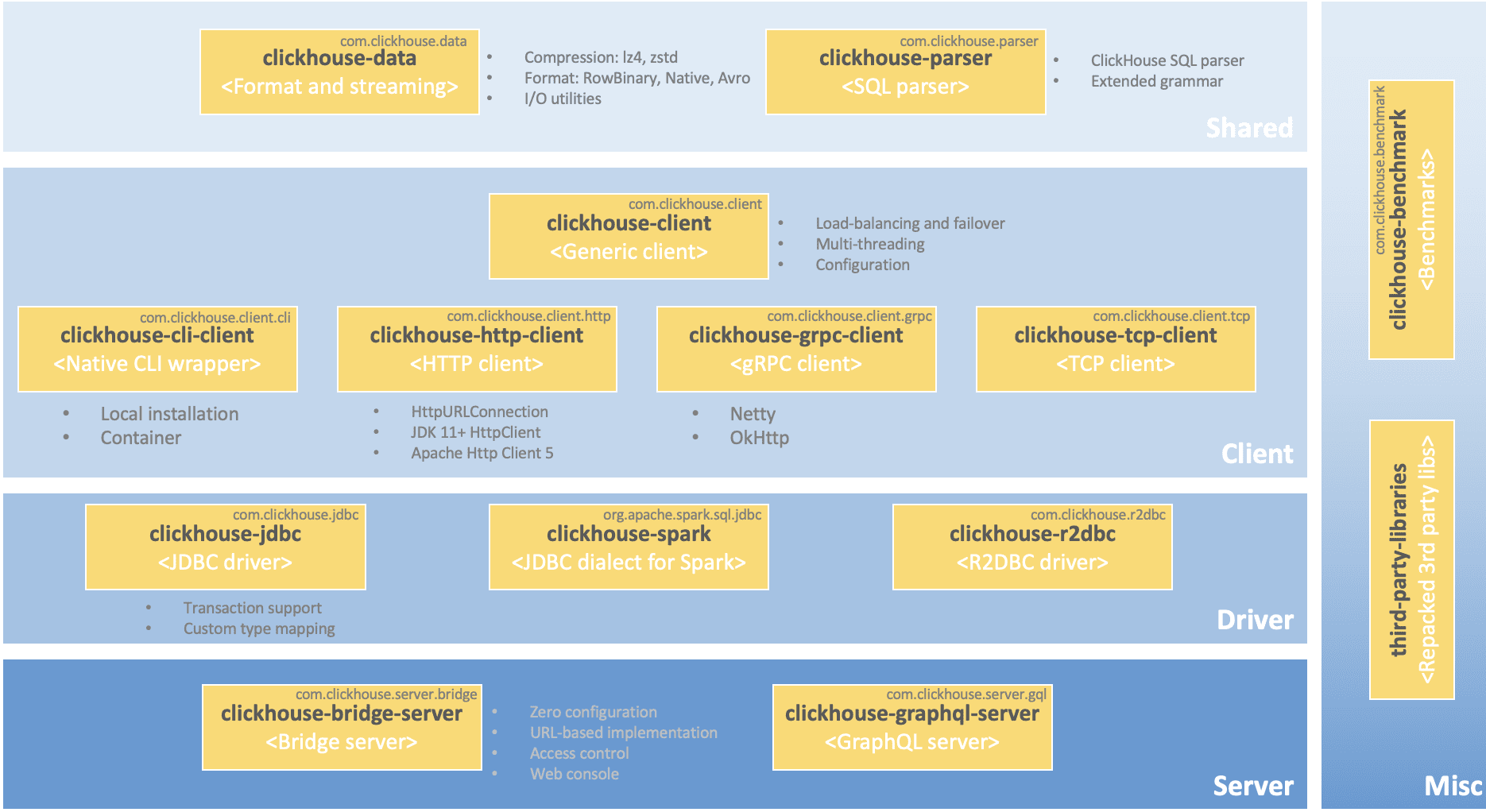
Чтобы подключиться к ClickHouse по протоколу HTTP(S), нужно знать хост сервера СУБД и порт (обычно 8443 при использовании TLS-шифрования или 8123 без него), название базы, имя пользователя и пароль. Также необходимо загрузить JAR-архив JDBC-драйвера ClickHouse в директорию, доступную приложению Apache NiFi, чтобы потом указать эту папку в свойстве службы контроллера DBCPConnectionPool. Это делает дата-инженер в веб-интерфейсе NiFi при проектировании потока данных.
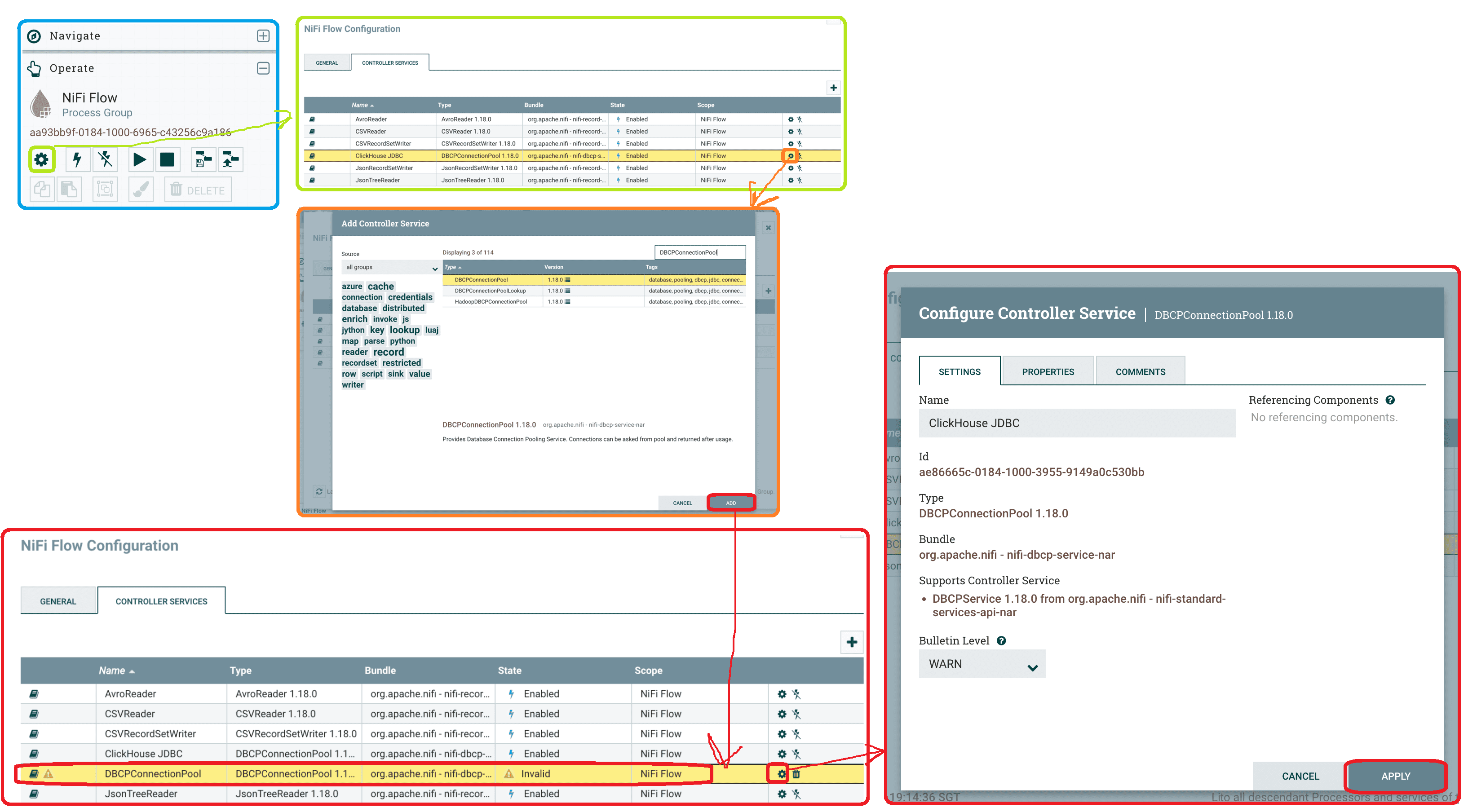
После настройки этой службы контроллера ее следует активировать и включить, чтобы затем использовать ClickHouse как источник или приемник данных в Apache NiFi с помощью процессоров ExecuteSQL и PutDatabaseRecord. Как это сделать, рассмотрим, далее.
Выполнение операций с данными
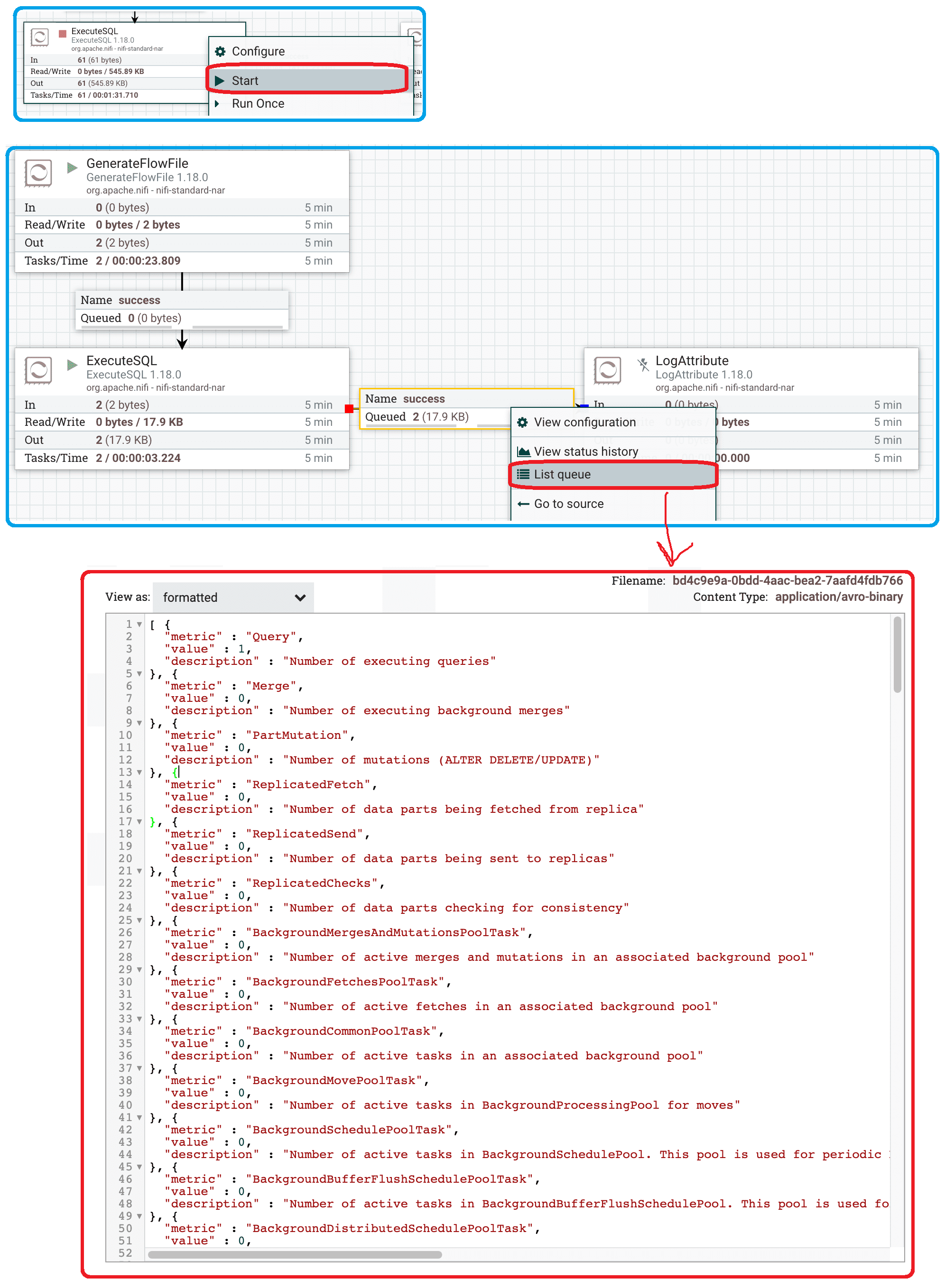
Как уже было отмечено ранее, для чтения данных из ClickHouse в Apache NiFi используется процессор ExecuteSQL. Он выполняет предоставленный SQL-запрос на выборку данных, возвращая результат в формате AVRO. Потоковый характер NiFi позволяет работать с большим объемом данных, что также характерно для сценариев использования ClickHouse. Процессор ExecuteSQL можно запланировать для запуска по таймеру или выражению cron, используя стандартные методы планирования. Также он может быть запущен входящим FlowFile, при этом его атрибуты будут доступны при оценке запроса, включая оператор ? для выходных параметров. В этом случае используемые параметры должны существовать в виде атрибутов FlowFile с соглашением об именах sql.args.N.type и sql.args.N.value, где N — положительное целое число, которое указывает тип JDBC. Содержимое FlowFile должно быть в кодировке UTF-8. Атрибут executesql.row.count указывает на количество строк при SELECT-запросе.
Помимо службы пула подключений к базе данных, роль которой выполняет служба контроллера DBCPConnectionPool, в настройках процессора ExecuteSQL также надо указать SQL-запрос на выбору данных из ClickHouse в свойстве SQL select query. Этот параметр может быть пустым, иметь постоянное значение или создан из атрибутов с использованием языка выражений. Если это свойство указано, оно будет использоваться независимо от содержимого входящих FlowFile. Если это свойство пусто, ожидается, что содержимое входящего FlowFile будет содержать действительный SELECT-запрос, который будет отправлен процессором в базу данных. После настроек можно запустить процессор и проверить наличие данных в выходной очереди.
Для записи данных в ClickHouse средствами NiFi следует использовать процессор PutDatabaseRecord. Он использует указанный RecordReader для ввода записей из FlowFile, которые преобразуются в SQL-операторы и выполняются как одна транзакция. При возникновении ошибок FlowFile перенаправляется в отношение failure или повторяется. При успешном выполнении операций вставки, входящий FlowFile перенаправляется в отношение success. Тип оператора, выполняемого процессором, указывается через свойство Statement Type, которое принимает жестко запрограммированные значения, соответствующие SQL-операторам INSERT, UPDATE и DELETE, а также «Использовать атрибут Statement.type», который заставляет процессор получать тип оператора из атрибута FlowFile. Если тип оператора UPDATE, то входящие записи не должны изменять значения первичных ключей или указанных пользователем ключей обновления.
Как и в случае чтения данных, для связи с ClickHouse, в процессоре PutDatabaseRecord надо задать службу контроллера DBCPConnectionPool. Также надо установить имя таблицу, куда будут вставляться данные и максимальное количество строк при операции вставки.
Поскольку ClickHouse оптимизирован для больших объемов данных, а не для мелких частых вставок, перед сохранением данных в него рекомендуется объединить несколько записей в одну. Для этого в NiFi есть процессор MergeRecord, выходные данные которого представляют собой массив из нескольких входных записей. Минимальное и максимальное количество записей для объединения задается в свойствах этого процессора.
Узнайте больше про применение ClickHouse и Apache NiFi для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

