Что такое аккумуляторы в Apache Spark, чем они отличаются от широковещательных переменных и какова польза от этих концепций при разработке распределенных приложений и их использовании в кластере.
Широковещательные переменные vs аккумуляторы
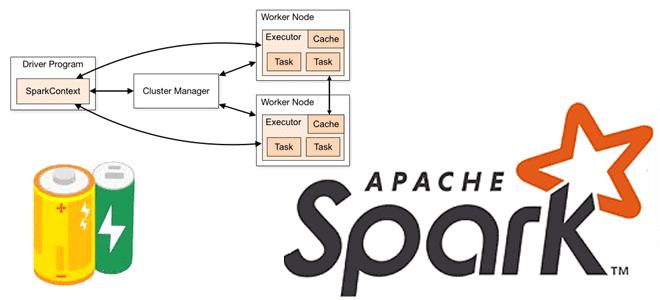
В любой распределенной среде возникает задача сведения локальных результатов вместе. На практике, ее решение не всегда является простым. Например, в Apache Spark, функция в операцию Map или Reduce, выполняется на удаленном узле кластера и работает с отдельными копиями всех переменных, используемых в функции. Эти переменные копируются на каждую машину кластера, и их обновления на отдельно взятом удаленном узле не распространяются обратно в программу-драйвер. Чтобы обеспечить такой обмен данными, Spark предоставляет два ограниченных типа общих переменных (Shared Variables): широковещательные переменные (Broadcast Variables) и аккумуляторы (accumulators).
Широковещательные переменные позволяют разработчику хранить переменную только для чтения в кэше на каждой машине, а не отправлять ее копию с задачами. Это пригодится для эффективного предоставления каждому узлу копии большого набора входных данных. Spark использует широковещательные переменные в операциях перетасовки (shuffle), чтобы сократить стоимость этих вычислений. Действия Spark выполняются через набор этапов, разделенных распределенными shuffle-операциями. Фреймворк автоматически передает общие данные, необходимые задачам на каждом этапе. Передаваемые данные кэшируются в сериализованной форме и десериализуются перед запуском каждой задачи. Поэтому явное создание широковещательных переменных полезно, когда задачам на нескольких этапах нужны одни и те же данные или когда важно кэшировать данные в десериализованной форме. Широковещательные переменные создаются из параметра v метода broadcast(v) объекта SparkContext, который является точкой входа в Spark-приложение в программе драйвера. Именно SparkContext представляет подключение к кластеру Spark и может использоваться для создания RDD, аккумуляторов и широковещательных переменных в этом кластере. Для каждой JVM может быть активен только один SparkContext. Широковещательная переменная представляет собой оболочку вокруг этого параметра v, и ее значение можно получить, вызвав метод value.
После создания широковещательной переменной ее следует использовать вместо значения v в любых функциях, выполняемых в кластере, чтобы она не отправлялась на узлы более одного раза. Кроме того, объект v не следует изменять после его широковещательной передачи, чтобы гарантировать одно и то же значение широковещательной переменной для всех узлов. Чтобы освободить ресурсы, которые широковещательная переменная скопировала на исполнителей, необходимо вызвать метод unpersist(). Если после этого широковещательная переменная снова будет использоваться, она транслируется повторно. Навсегда освободить все ресурсы, используемые широковещательной переменной, поможет метод destroy(), после вызова которого широковещательную переменную нельзя использовать. Эти методы не блокируются по умолчанию. Если такое поведение необходимо изменить, т.е. блокировать ресурсы до их освобождения, следует указать опцию blocking=true при вызове методов unpersist() и destroy().
Аккумуляторы — это общие переменные, которые позволяют накапливать значения на рабочих узлах в распределенной среде. Они добавляются только посредством ассоциативной и коммутативной операции и поэтому могут эффективно поддерживаться параллельно. Их можно использовать для реализации счетчиков (как в MapReduce) или сумм, для агрегирования данных или отслеживания глобальной статистики во время вычислений. В отличие от обычных переменных, аккумуляторы могут обновляться рабочими узлами, но могут быть прочитаны только программой-драйвером. Это очень полезно для сбора и обработки важной информации в кластере. Как и когда использовать аккумуляторы в коде Spark-приложения, рассмотрим далее.
Когда и как использовать аккумуляторы в Apache Spark
По сути, аккумулятор – это накопитель, общая переменная, которая может накапливаться, т.е. имеет коммутативную и ассоциативную операцию сложения. Рабочие задачи в кластере Spark могут добавлять значения в аккумулятор с помощью оператора += , но только программа-драйвер может получить доступ к его значению, используя метод value. Обновления от рабочих процессов автоматически распространяются на программу-драйвер.
Аккумулятор создается из начального значения параметра v метода accumulator(v) у объекта SparkContext. Задачи, запущенные в кластере, могут добавлять к нему данные с помощью метода add() или оператора +=. Однако, они не могут прочитать его значение, в отличие от программы-драйвера.
Хотя SparkContext поддерживаются аккумуляторы для примитивных типов данных, таких как int и float, разработчик может также определять аккумуляторы для пользовательских типов, предоставляя пользовательский объект AccumulatorParam, т.е. создавая его подклассы. Интерфейс AccumulatorParam имеет два метода: zero() для предоставления нулевого значения для пользовательского типа данных и addInPlace() для сложения двух значений вместе.
Разработчик может создавать собственные именованные или неименованные аккумуляторы. Именованный аккумулятор будет отображаться в веб-интерфейсе Apache Spark для этапа, который изменяет этот аккумулятор. Spark отображает значение для каждого аккумулятора, измененного задачей, в таблице задач. Отслеживание аккумуляторов в пользовательском интерфейсе Apache Spark полезно для понимания хода выполнения этапов, но это еще не поддерживается в Python, с которым я обычно работаю. Поэтому показать пока не смогу.
Для обновлений аккумулятора, выполняемых только внутри действий, т.е. функций, запрашивающих вывод, Spark гарантирует, что для каждой задачи это будет применено только один раз. Это означает, что перезапущенные задачи не будут обновлять значение аккумулятора. При преобразованиях, т.е. отложенных вычислениях, которые фактически не выполняются сразу, а после материализации запроса и вызове какого-либо действия, обновление каждой задачи может применяться более одного раза, если задачи или этапы задания выполняются повторно. Аккумуляторы не изменяют модель отложенных вычислений Spark. Если они обновляются в рамках операции с RDD, их значение обновляется только после того, как RDD вычисляется как часть действия. Поэтому не гарантируется обновление аккумулятора в рамках отложенного преобразования, такого как map(). О том, чем отличаются действия и преобразования в Spark, мы подробно рассказывали здесь.
На практике аккумуляторы можно использовать для мониторинга качества данных во время ETL-процессов на всех узлах кластера или для генерации уникальных значений для нескольких узлов. Впрочем, стоит помнить, что аккумуляторы могут привести к неожиданным результатам при неправильном использовании. Одним из распространенных антипаттернов является попытка доступа к значению аккумулятора в операции преобразования, такой как map() или filter(). Из-за модели отложенных вычислений Spark это может привести к неверным или противоречивым значениям.
Таким образом, аккумуляторы — это мощная функция Apache Spark, упрощающая сбор глобальной статистики и метрик во время распределенных вычислений, но их следует применять аккумуляторы в действиях, а не в преобразованиях, чтобы избежать ошибок и максимально использовать потенциал фреймворка. В заключение отметим, что аккумуляторы и широковещательные переменные не могут быть восстановлены из контрольной точки в Spark Streaming, о чем мы рассказываем в новой статье.
Освойте все возможности Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

