 1260
1260 
Содержание
Недавно мы рассматривали практический пример разделения большого датафрейма Apache Spark на несколько разделов. Сегодня поговорим о том, как их объединить с помощью механизм AQE и динамической настройки конфигурации spark.sql.shuffle.partitions.
Разделы и оптимизация распределенных вычислений в Spark-приложениях
Распределение данных по разделам сильно влияет на скорость работы Spark-приложений. Распределенное приложение выполняется наиболее эффективно, когда каждый его этап работает на оптимальном количестве разделов в зависимости объема входных данных и характера вычислений. Слишком много маленьких разделов увеличивает нагрузку на оценку и планирование, а чрезмерно большие разделы приводят к потере желаемого параллелизма, поскольку один исполнитель может обрабатывать только 1 раздел в любой момент времени. Поэтому для тяжелых и ресурсоемких вычислений предпочтительны разделы небольшого размера, а для простых и быстрых подходят разделы большого размера. Большинство этапов в задании возникает из-за того, что shuffle-операторы в случайном порядке вставляются механизмом выполнения фреймворка. Каждый из этих операторов (repartition, groupByKey, reduceByKey, cogroup и join) использует параметр конфигурации spark.sql.shuffle.partitions, чтобы определить количество разделов. Таким образом, все этапы, выполняющие случайное чтение, выполняются на одинаковом количестве разделов. Но такое универсальное решение не может быть оптимальным для всех этапов и снижает общую эффективность заданий распределенного приложения.
Например, рассмотрим скриншот из GUI заданий распределенного приложения, выполняющегося в кластере. Этапы 3, 5 и 6 являются этапами, созданными в случайном порядке, и каждый из них выполняется со значением конфигурации spark.sql.shuffle.partitions, которое по умолчанию установлено на 200.
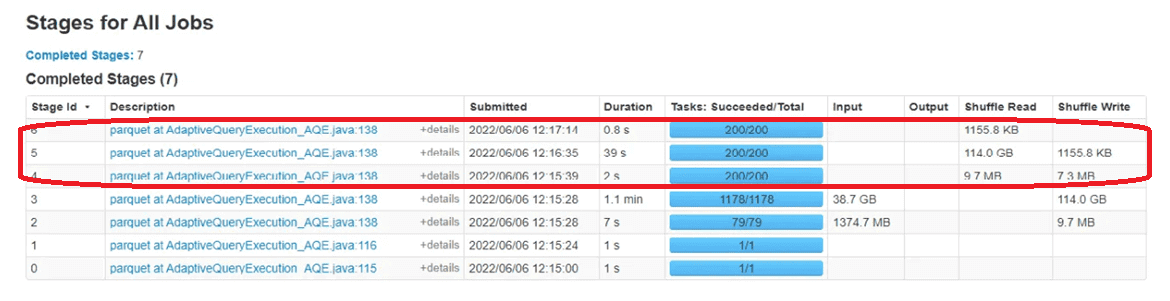
Чтобы преодолеть ограничение этой конфигурации, разработчик может вручную настроить количество разделов с помощью преобразований функций repartition() или coalesce(), работу которых мы разбирали здесь. Однако, можно воспользоваться встроенной функцией Coalescing Post Shuffle Partitions, которая динамически объединяет разделы после перетасовки на основе выходной статистики сопоставления, когда оба параметры конфигураций spark.sql.adaptive.enabled и spark.sql.adaptive.coalescePartitions.enabled установлены в значение true.
Эта функция упрощает настройку количества разделов в случайном порядке при выполнении запросов. Фреймворк может выбрать правильное число разделов во время выполнения, когда предварительно установлено достаточно большое начальное количество разделов для перемешивания с помощью конфигурации spark.sql.adaptive.coalescePartitions.initialPartitionNum.
Эта функция стала доступна благодаря методу адаптивного выполнения запросов (AQE, Adaptive Query Execution), который использует статистику времени выполнения для выбора наиболее эффективного плана. Метод оптимизации AQE включен по умолчанию в Spark SQL, начиная с версии 3.2.0. Это было сделано чтобы снизить нагрузку на разработчиков, связанную с ручным перераспределением разделов с помощью функций repartition() или coalesce(), применение которых является итеративным и сложным процессом, требующим хорошего понимания исполнительного механизма фреймворка.
Чтобы использовать динамическое объединение разделов, необходимо установить для конфигураций spark.sql.adaptive.enabled и spark.sql.adaptive.coalescePartitions.enabled значения true. Впрочем, по умолчанию в версии фреймворка 3.0 и выше, это так и есть по умолчанию. А до этого выпуска значение конфигурации spark.sql.adaptive.enabled по умолчанию установлено false и следует переключить его вручную. Как работает динамическое объединение разделов, мы рассмотрим далее.
Динамическое объединение разделов
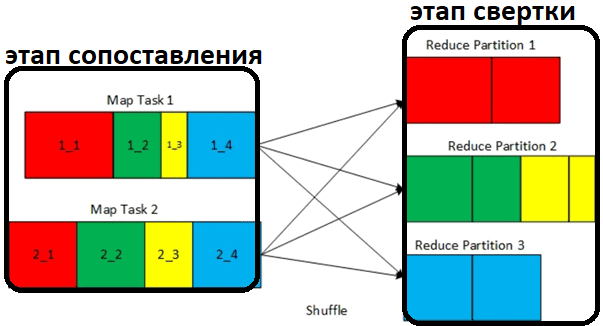
Согласно вычислительной модели MapReduce, shuffle-операции состоят из двух последовательных этапов:
- этап сопоставления (Map), который записывает блоки перемешивания, соответствующие настроенному количеству shuffle-разделов;
- этап свертки (Reduce), который считывает соответствующие shuffle-блоки, комбинирует их по количеству их разделов перемешивания, а затем последовательно запускает логику свертки для каждого объединенного блока данных.
Именно между этапами Map и Reduce работает динамическое объединение разделов: после этапа сопоставления до завершения перемешивания после записи всех блоков shuffle-данных вычисляется множество статистических данных, таких как количество записей и размер каждого из разделов, чтобы передать эти сведения в исполнительный механизм фреймворка. Эта статистика используется для поиска оптимизации плана выполнения запросов, чтобы вычислить оптимальный целевой размер для объединенного раздела. На основе вычисленного целевого размера выполняется оценка количества объединенных разделов в случайном порядке. Если это оценочное число меньше значения, определенного в конфигурации spark.sql.shuffle.partitions, динамическое объединение разделов динамически вставляет во время выполнения преобразование объединения, имеющее входной параметр в качестве предполагаемого количества объединенных перетасованных разделов.
Например, для конфигурации spark.sql.shuffle.partitions установлено значение 4. Поэтому две задачи сопоставления, соответствующие 2-м разделам, на этапе сопоставления перетасовки записывают 4 блока перетасовки, соответствующие настроенным shuffle-разделам. Благодаря динамическому объединению shuffle-разделы 2 и 3 объединяются. Поэтому общее количество разделов в случайном порядке становится равным 3 вместо 4 на этапе свертки после перемешивания.
На процесс принятия решения для динамического объединения разделов влияют несколько параметров, которые настраиваются. В версиях фреймворка до 3.0 таким параметром был spark.sql.adaptive.shuffle.targetPostShuffleInputSize, который управлял целевым размером раздела после объединения. Размеры объединенных разделов близки к этому целевому значению, по умолчанию равному 64 МБ, но не превышают его. В версии 3.0 введено еще несколько параметров для более точной настройки, поддержания баланса между желаемым параллелизмом и максимальным размером объединенного раздела:
- spark.sql.adaptive.advisoryPartitionSizeInBytes — целевой размер раздела после объединения (по умолчанию: 64 МБ);
- spark.sql.adaptive.coalescePartitions.minPartitionNum – минимальное количество разделов после объединения, если не задано, по умолчанию равен значению конфигурации параллелизма (spark.default.parallelism);
- spark.sql.adaptive.coalescePartitions.minPartitionSize – минимальный размер разделов после объединения, по умолчанию равный 1 МБ. Размеры объединенных разделов будут не меньше этого размера.
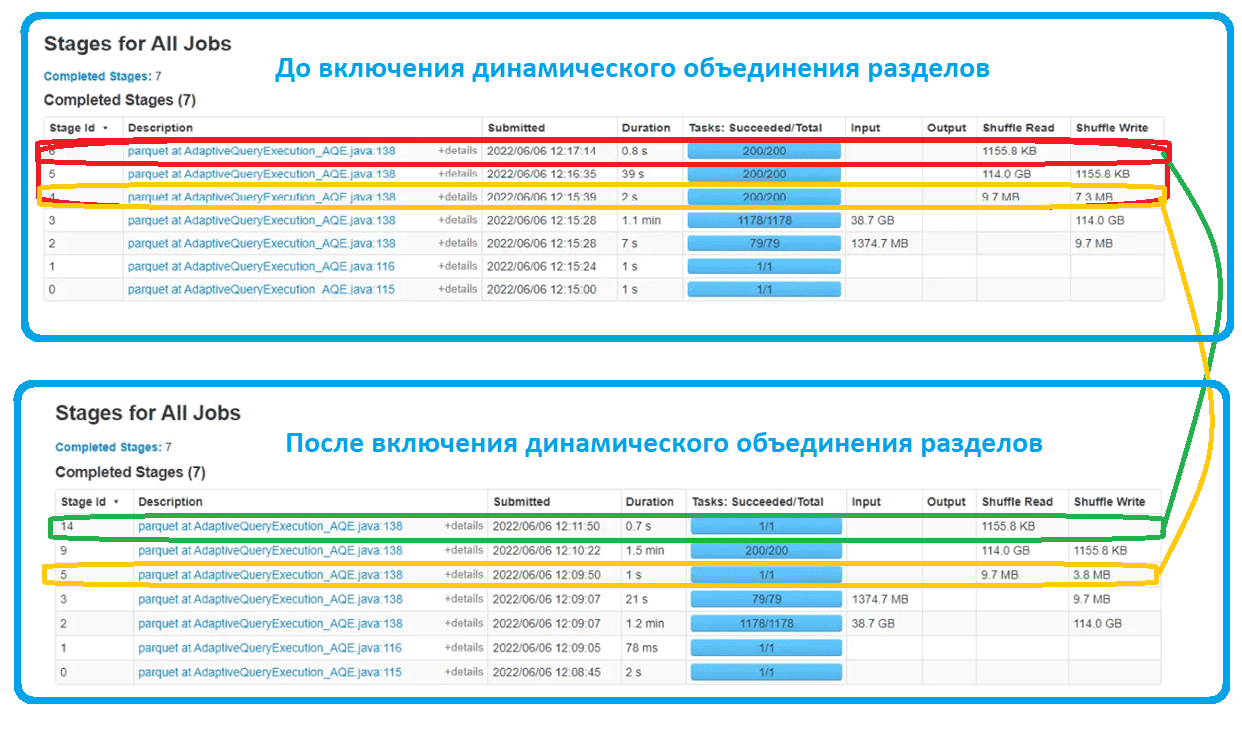
После включения динамического объединения разделов к ранее рассмотренному набору этапов распределенного приложения, количество разделов в случайном порядке сократилось до 1 на этапах 5 и 14, что ранее соответствовало этапам 4 и 6. Несовпадение номер объясняется тем, что AQE меняет нумерацию этапов из-за добавления промежуточных преобразований.
Освойте тонкости применения Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
[elementor-template id=»13619″]
Источники

