 703
703 
Сегодня посмотрим, как запустить Spark-приложение в Google Colab и увидеть сведения о его выполнении в веб-интерфейсе на удаленной машине, тунеллированной с помощью утилиты ngrok.
Проброска туннеля в Google Colab с ngrok для Spark-приложения
Хотя назвать Google Colab удобной средой для разработки приложений или исследования данных, нельзя, им часто пользуются аналитики данных и специалисты по Data Science. Однако, при запуске Spark-приложения в Colab иногда надо посмотреть сведения о его выполнении. Многие из них представлены в веб-интерфейсе фреймворка, о котором мы писали здесь. Однако, при работе в Google Colab войти в этот веб-интерфейс не так-то просто, поскольку скрипт запускается на удаленной машине, а изначально GUI фреймворка привязан к сокету http://localhost:4040, т.е. порту 4040 на локальном хосте. Поэтому, чтобы достучаться до веб-интерфейса приложения, запускаемого в Google Colab, необходимом прокинуть туннель, который делает локальный хост доступным извне. Для этого можно использовать утилиту ngrok. Этот сервис позволяет открыть доступ к внутренним ресурсам машины, на которой он запущен, из внешней сети, путем создания публичного адреса, все запросы на который будут переброшены на локальный адрес и заданный порт.
Пусть приложение в дальнейшем будет использоваться для анализа данных по финансовым транзакциям среди клиентов банка. Создадим 2 датафрейма с данными клиентов и сведениями о транзакциях. Но сперва установим и импортируем необходимые библиотеки и модули:
!apt-get install wget !pip install pyspark !apt install openjdk-8-jdk-headless !pip install Faker !wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip !unzip ngrok-stable-linux-amd64.zip !pip install pyngrok #импорт модулей from pyspark.sql import SparkSession import pyspark import sys import os import random from pyngrok import ngrok !ngrok update os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64" # Импорт модуля faker from faker import Faker from faker.providers.address.ru_RU import Provider
Далее напишем скрипт создания Spark-приложения под названием MySparkApp, указав в конфигурации номер порта для GUI:
from pyspark.sql import SparkSession
# Создаем объект SparkSession и устанавливаем имя приложения
spark = SparkSession.builder.appName("MySparkApp").config('spark.ui.port', '4040').getOrCreate()
#Импорт и настройка генератора случайных данных Faker.
fake = Faker('ru_RU')
fake.add_provider(Provider)
# создаем пустой список для хранения сгенерированных данных
data1 = []
# генерируем данные и добавляем их в список
for i in range(100):
k=random.randint(0, 1)
if k==1 :
name = fake.company()
else :
name = fake.name()
bank_account = fake.checking_account()
data1.append((i, name, bank_account))
# создаем датафрейм вершин из списка данных
v = spark.createDataFrame(data1, schema=['id', 'Client', 'Bank Account'])
# создаем пустой список для хранения сгенерированных данных
data2 = []
# генерируем данные и добавляем их в список
for i in range(200):
src = random.randint(0, 19)
dst = random.randint(0, 19)
summa = random.randint(0, 10000)
data2.append((src, dst, summa))
# создаем датафрейм связей из списка данных
e = spark.createDataFrame(data2, schema=['src', 'dst', 'summa'])
# Запускаем сервис ngrok для открытия порта Spark UI
get_ipython().system_raw('./ngrok http 4040 &')
!sleep 5
!curl -s http://localhost:4040/api/tunnels | grep -Po 'public_url":"https://.*?"'
Чтобы пробросить туннель с помощью ngrok мне понадобилось аутентифицироваться в этом сервисе и указать свой токен:
auth_token = "….здесь ваш токен аутентификации в ngrok…." #@param {type:"string"}
# Since we can't access Colab notebooks IP directly we'll use
# ngrok to create a public URL for the server via a tunnel
# Authenticate ngrok
# https://dashboard.ngrok.com/signup
# Then go to the "Your Authtoken" tab in the sidebar and copy the API key
os.system(f"ngrok authtoken {auth_token}")
public_url = ngrok.connect()
print(public_url)
Написав в отдельной ячейке название созданного объекта класса SparkSession, т.е. spark, можно увидеть краткие сведения о своем приложении и ссылку на его веб-GUI. Однако, не стоит пытаться переходить по ней, вместо этого надо кликнуть на NgrokTunnel, например, https://adbf-35-196-225-227.ngrok-free.app, который является представлением локального хоста http://localhost:4040 на удаленной машине, где запущено приложение под названием MySparkApp.
Поскольку Spark использует концепцию отложенных вычислений, чтобы в веб-GUI появились сведения о выполняемых заданиях и данных, необходимо запустить какие-то действия. В отличие от преобразований (transformations), которые фактически не выполняются сразу, а после материализации запроса и вызове какого-либо действия, действия (actions) представляют собой функции, запрашивающие вывод. При этом не только создается план запроса, но и оптимизируется оптимизатором Spark, а также физический план компилируется в RDD DAG, который делится на этапы (stages) и задачи (tasks), выполняемые в кластере. Подробнее об отличии преобразований и действий читайте здесь.
Для этого я вызвала несколько элементарных действий: подсчета количества строк в обоих датафреймах и разделения датафреймов на несколько разделов с помощью функции coalesce(), которая создает разделы разных размеров, т.е. с разным объемом данных.
e.count() v.count() v.coalesce(2).show() e.coalesce(2).show()
Теперь посмотрим, как это выглядит в веб-GUI Spark. Всего доступны следующие вкладки:
- Jobs (Задания)– сводная страница всех заданий в приложении Spark с детализацией сведений по каждому заданию (Jobs detail);
- Stages (Этапы)— сводная страница с текущим состоянием всех этапов каждого задания в Spark-приложении с детализацией сведений по каждому из них (Stages detail);
- Storage (Хранилище)– сводная страница с сохраненными (кэшированными) RDD и датафреймами Spark-приложения с детализацией сведений об их уровнях хранения, размерах, разделах и используемых исполнителях;
- Environment (Среда)— значения различных переменных среды и конфигурации, включая JVM, Spark и системные свойства;
- Executors (Исполнители)— сводная информация об исполнителях, созданных для приложения, включая использование ресурсов;
- SQL/Dataframe – информация о заданиях Spark SQL, включая их продолжительность, а также физические и логические планы запросов.
В случае моего простенького приложения информация присутствует на всех вкладках, кроме Storage, поскольку написанный скрипт не выполняет действий кэширования и сохранения данных – все данные находятся в памяти.
Например, на вкладке Jabs показан список заданий:

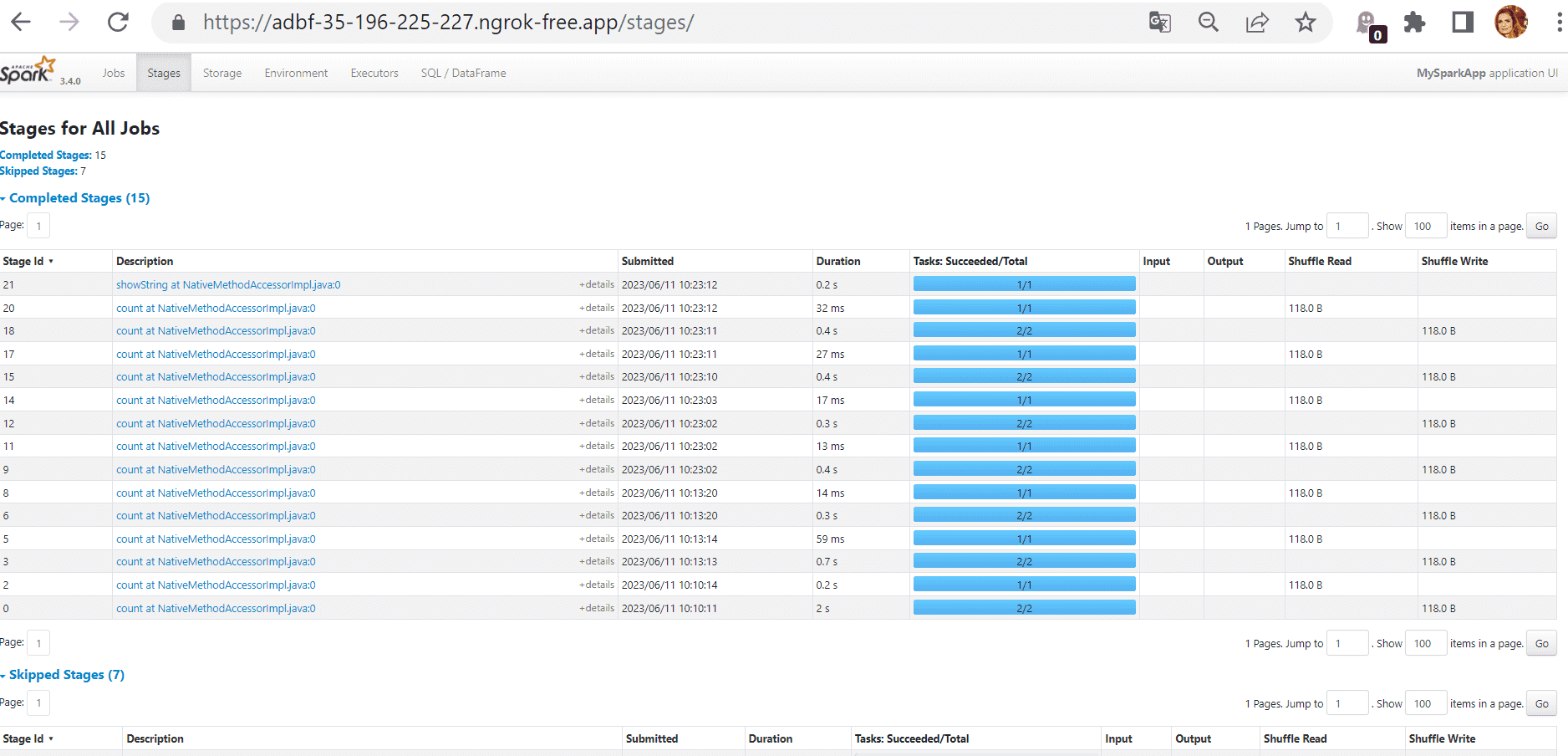
На вкладке Stages показаны этапы всех заданий
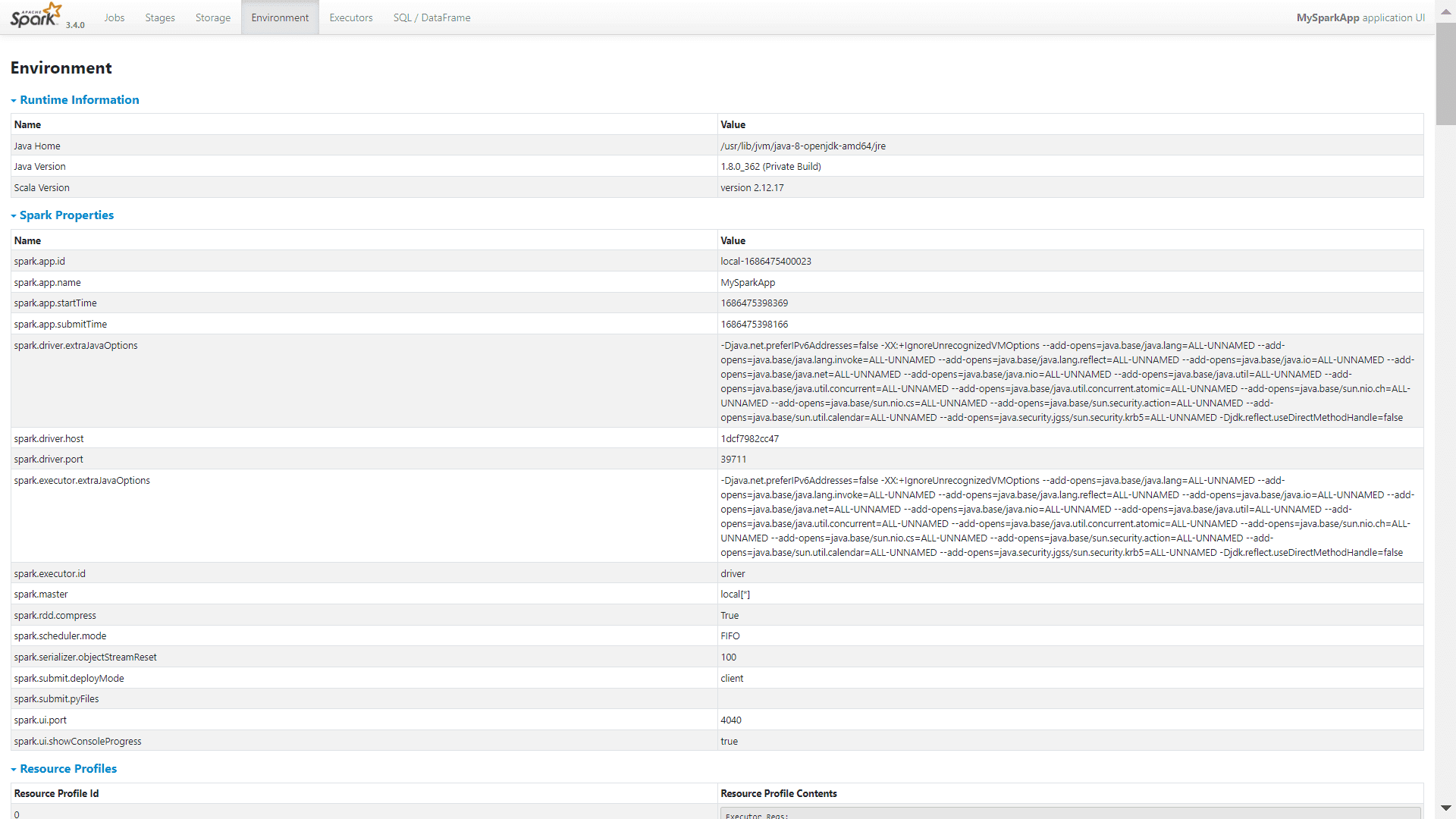
На вкладке Environment информация о рабочей среде исполнения моего Spark-приложения
На вкладке Executors есть данные об исполнителях:
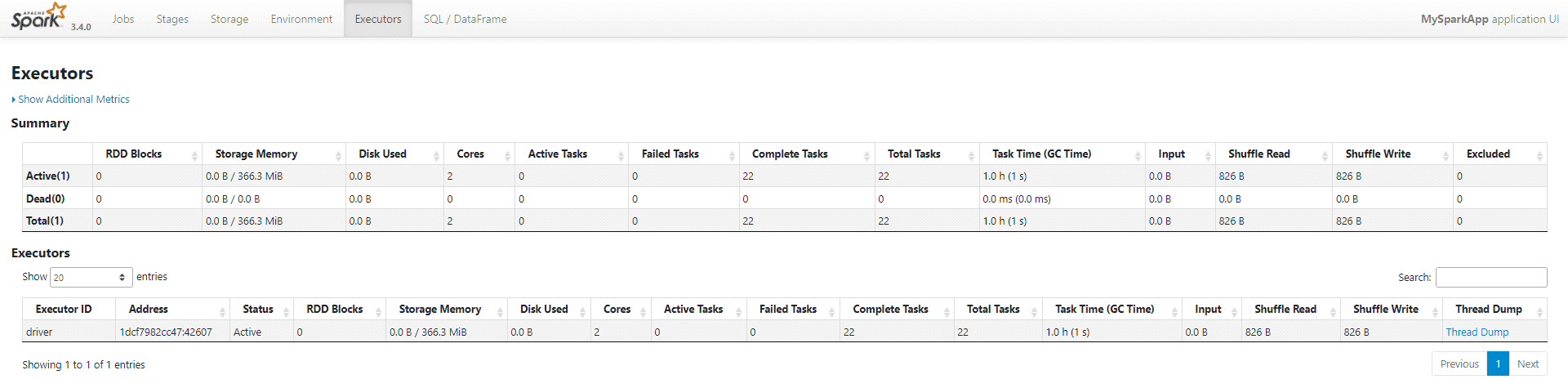
Исполнители Spark
На вкладке SQL/Dataframe доступен список задач, т.е. выполненных запросов к данным со ссылкой на идентификаторы заданий:
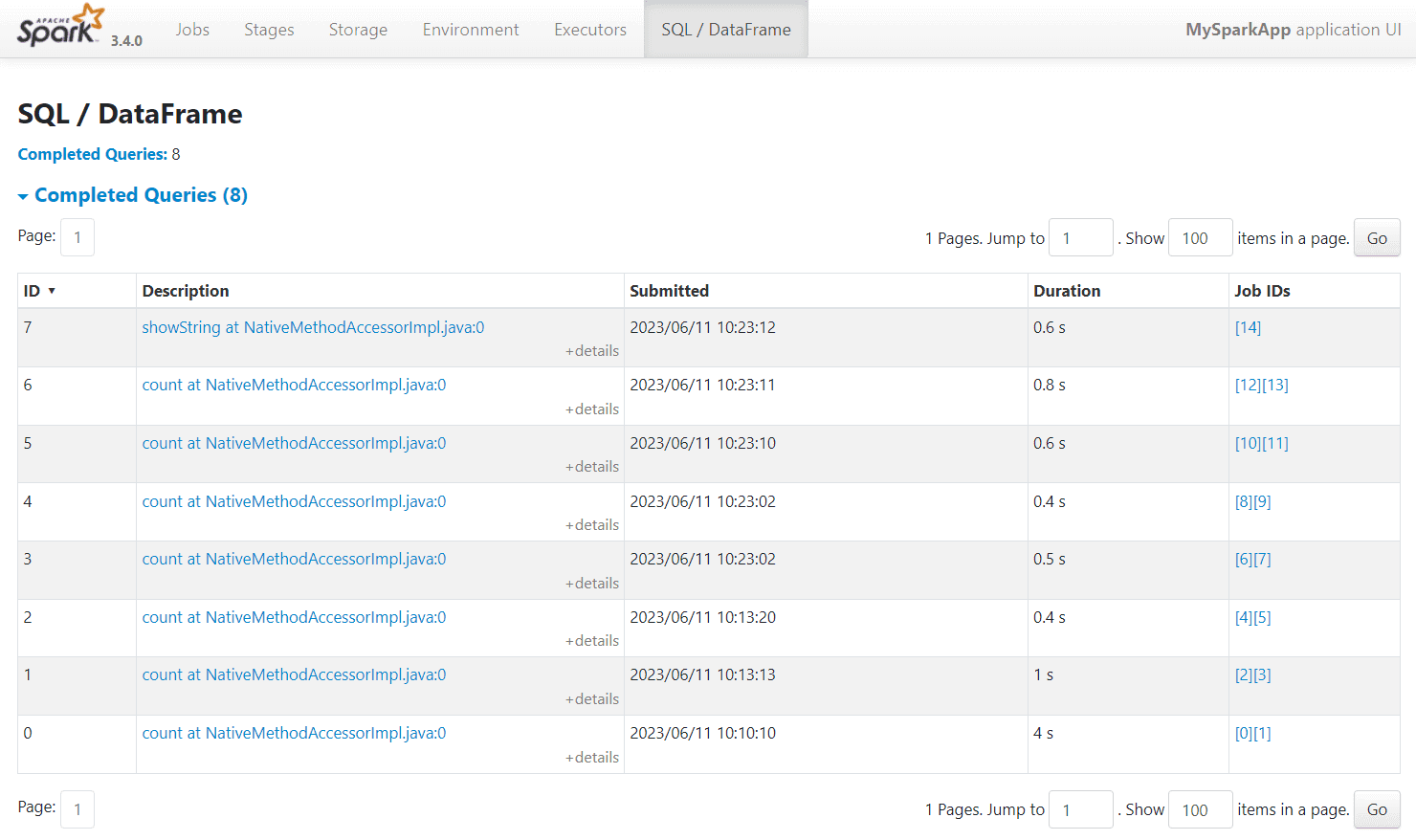
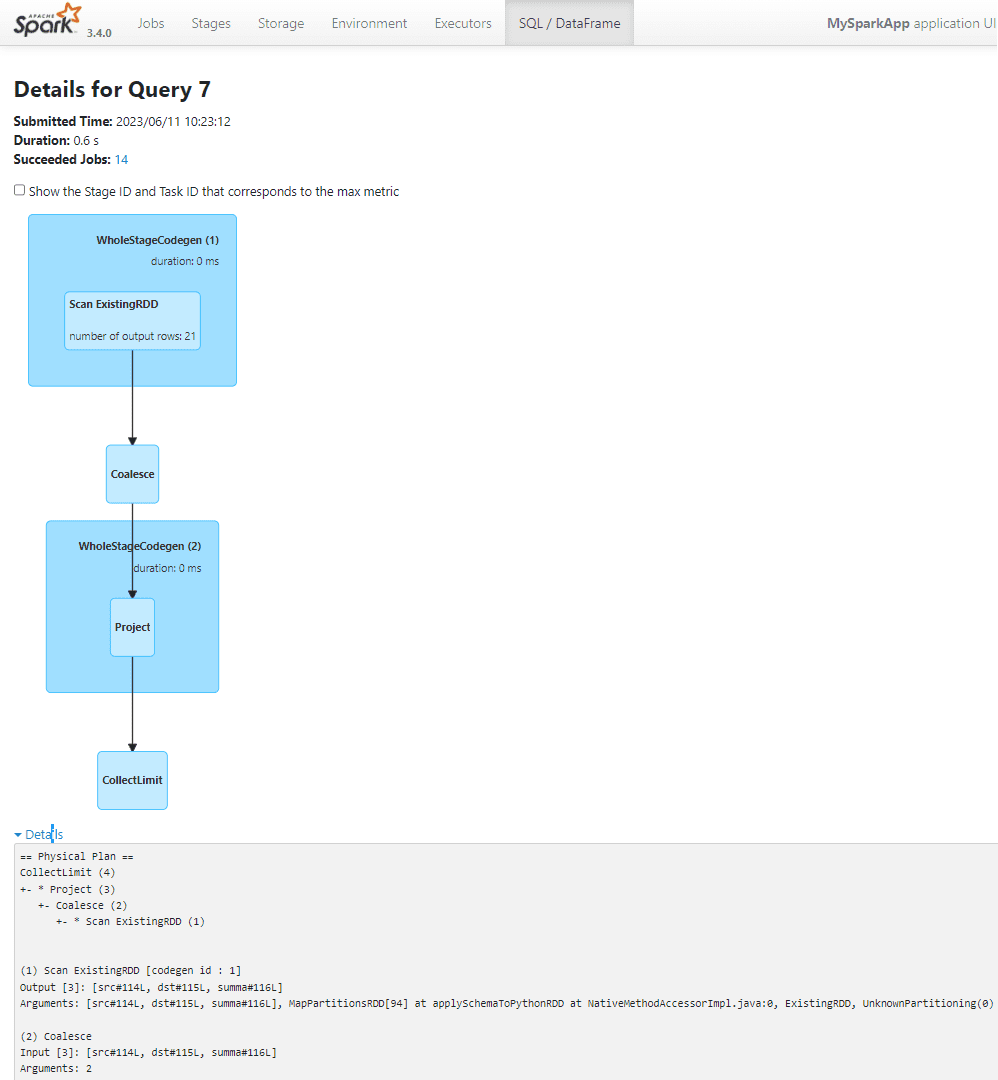
Можно просмотреть детали по каждому запросу, включая его планы выполнения в текстовом и графическом видах, кликнув на описание (Description):
В заключение напомню про рекомендацию закрывать среду выполнения и сеанс в Colab после того, как вы поработали со своим приложением, чтобы не выкачать бесплатные лимиты, как это получилось у меня.
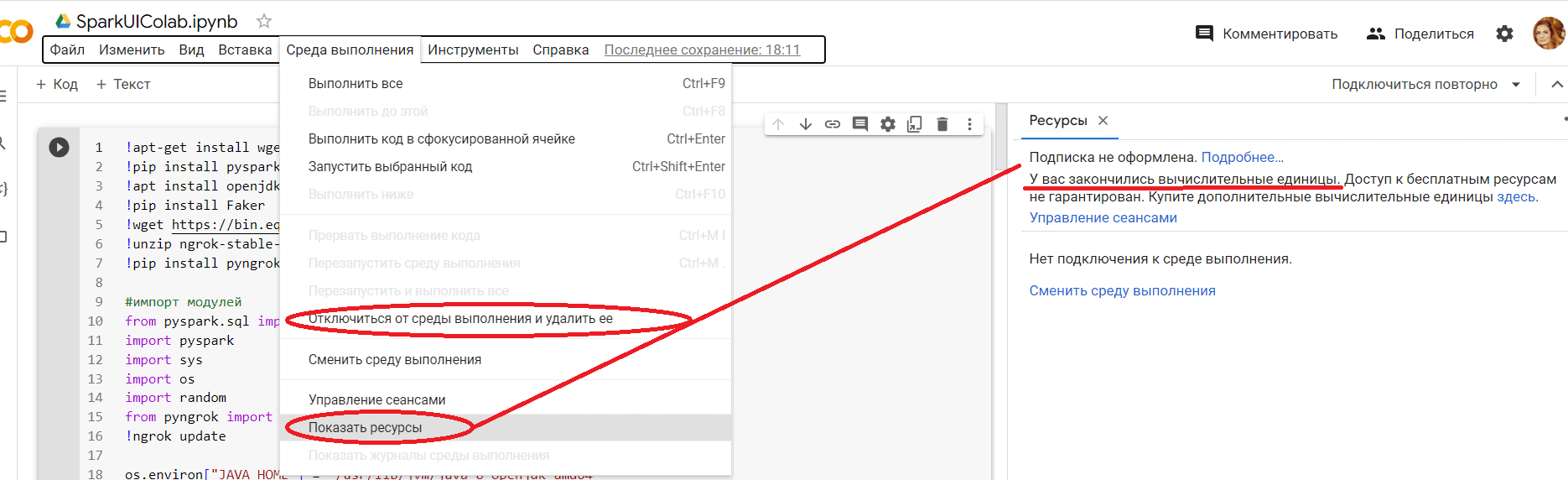
Теперь вычислительной мощности этой интерактивной среды мне хватает лишь на какие-то простенькие Python-скрипты, а на Spark-приложениях она начинает подвисать и выдает ошибку RuntimeError: Java gateway process exited before sending its port number, которая означает, что
Spark не может запустить свой Java-шлюз. Чаще всего это случается при недостатке ресурсов (память, ЦП) для запуска Spark в среде выполнения. В этом случае рекомендуется увеличить количество выделенной памяти или использовать другой тип машины, т.е. перейти с бесплатного тарифа на платный, что я, конечно же, делать не буду). Что еще не позволил мне сделать Google Colab при разработке и запуске Spark-приложения, читайте в новой статье.
Узнайте больше про использование Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

