Проблемы управления данными в мультиарендной среде или как Databricks решил изолировать клиентские приложения Apache Spark на общей виртуальной машине Java друг от друга и от самого фреймворка (драйвера и исполнителей). Знакомство с Lakeguard на базе каталога Unity.
Проблемы управления данными в мультитенантной среде
Компания Databricks не просто развивает и продвигает Apache Spark, а построила целую платформу данных Data Intelligence Platform на базе этого open-source фреймворка. Эта платформа позволяет запускать многопользовательские рабочие нагрузки Apache Spark на SQL, Python и Scala с полным управлением данными. Ранее для изоляции рабочих нагрузок в Databricks Data Intelligence Platform приходилось использовать однопользовательские кластеры, что увеличивало экономические затраты и эксплуатационные накладные расходы.
Изначально Apache Spark не предлагает механизма изоляции пользовательского кода. Поэтому когда разные пользователи используют одну и ту же среду выполнения, виртуальную машину Java, для запуска своих приложений, это является уязвимостью, открывает потенциальную возможность утечки данных между пользователями. Облачные службы Spark решают эту проблему путем создания выделенных кластеров для каждого пользователя, что приводит к росту затрат на инфраструктуру и на управление кластерами, поскольку администраторам приходится тратить на этом много времени и ресурсов.
Кроме того, изначально Apache Spark не был разработан с учетом детального контроля доступа: при запросе к представлению он извлекает все файлы базовых таблиц, используемых этим представлением. Поэтому пользователи потенциально могут читать данные, к которым у них нет доступа. Это тоже грубое нарушение принципа конфиденциальности в информационной безопасности.
Чтобы устранить эти проблемы, в 2024 году разработчики Databricks внедрили решение Lakeguard, которое позволяет изолировать пользовательский код, UDF-функции Python и SQL-запросы, а также движки Spark на общих вычислительных ресурсах, обеспечивая принудительное управление данными во время выполнения. Lakeguard является неотъемлемой частью каталога Unity. Каталог Unity – это единое решение для управления данными и ресурсами ИИ в Databricks Lakehouse, который обеспечивает централизованный контроль доступа, аудит, происхождение и возможности обнаружения данных в рабочих пространствах Databricks.
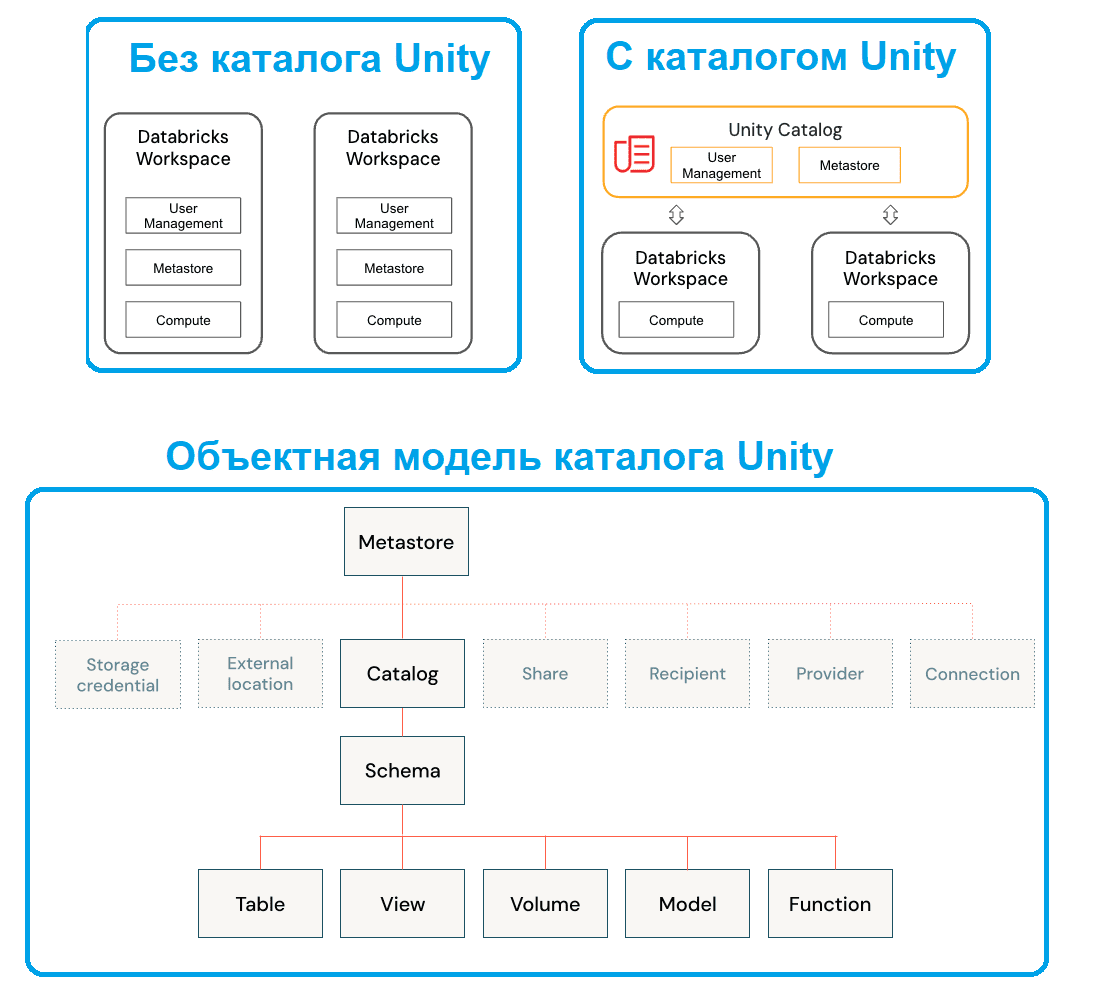
Для клиентов Databricks каталог Unity предлагает комплексное управление и происхождение всех таблиц, представлений и моделей машинного обучения в любом облаке. После определения управления данными в каталоге Unity правила управления необходимо применять во время выполнения.
Чтобы обеспечить управление данными на уровне вычислений, изолировав рабочие нагрузки разных пользователей друг от друга, архитектура совместного использования JVM с привилегированным доступом к базовой машине заменена на другую модель, которую мы рассмотрим далее.
Код курса
SPAD
Ближайшая дата курса
Продолжительность
ак.часов
Стоимость обучения
0
Изоляция пользовательского кода Apache Spark SQL с Lakeguard
В новой архитектуре платформы данных Databricks код каждого пользователя изолирован от драйвера и исполнителей Spark с помощью безопасных контейнеров. Благодаря этой архитектуре Databricks безопасно запускает несколько рабочих нагрузок в одном кластере, предлагая экономичное и безопасное решение для совместной работы.
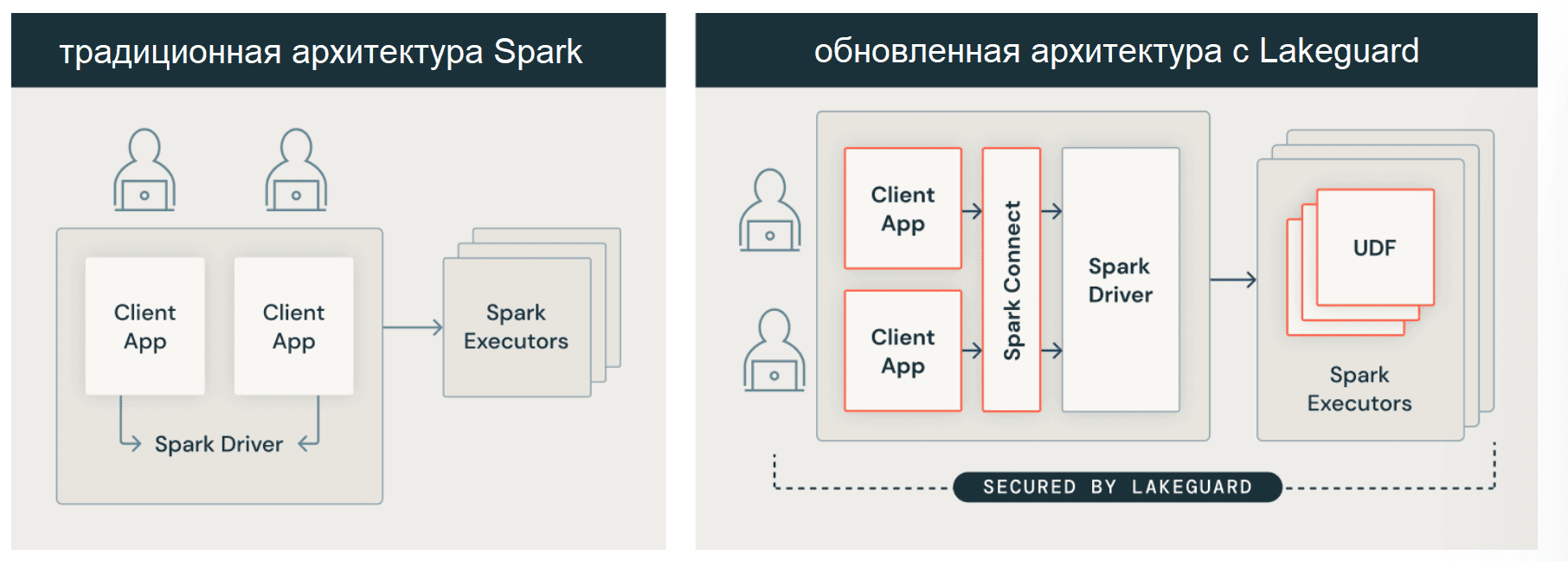
Чтобы изолировать клиентские приложения от драйвера Spark, сперва потребовалось их отделить, а затем изолировать друг от друга и от базовой JVM с целью создания полностью доверенной и надежной границы между отдельными пользователями и Spark. Для обеспечения изоляции пользовательского кода на стороне клиента, используется Spark Connect – тонкий клиент, позволяющий выполнять запросы Spark на устройствах с низкими вычислительными мощностями за счет модернизации драйвера, что позволяет обойти некоторые недостатки монолитного драйвера и улучшить поддержку мультиарендности. Исходный код Spark Connect был открыт в версии фреймворка 3.4, о чем мы подробно писали здесь и здесь.
Spark Connect позволяет отделить клиентское приложение от драйвера, чтобы они не использовали одну и ту же JVM или пути к классам, а также могли разрабатываться и запускаться независимо. Эта разделенная архитектура может обеспечить детальный контроль доступа, поскольку избыточные данные, используемые для обработки запросов к представлениям или таблицам с фильтрами на уровне строк/столбцов, больше не доступны из клиентского приложения.
Кроме того, разработчики Databricks Data Intelligence Platform запретили отдельным клиентским приложениям, то есть пользовательскому коду, доступ к данным друг друга или базовой JVM, создав облегченную изолированную среду выполнения для клиентских приложений на основе контейнеров. Теперь каждое клиентское приложение работает полностью изолированно в своем собственном контейнере.
Аналогично клиентскому приложению была изолирована среда выполнения на исполнителях Spark, чтобы безопасно запускать пользовательские функции Python и Scala. Поскольку ранее исполнители Spark, подобно драйверу, не обеспечивали изоляцию UDF-функций. Например, пользовательская функция Scala могла записывать произвольные файлы в файловую систему из-за привилегированного доступа к виртуальной машине Java. Также был изолирован исходящий сетевой трафик от остальной части системы.
А, чтобы пользователи могли использовать свои библиотеки в UDF, клиентская среда теперь безопасно реплицируется в изолированные программные среды UDF. В результате пользовательские функции в общих кластерах выполняются в полной изоляции. Lakeguard также используется для пользовательских функций Python в хранилище данных SQL Databricks.
Таким образом, решение Databricks поддерживает все современные тренды в построении платформ данных:
- облачные сервисы;
- унифицированное управление множеством разных ресурсов;
- активное использование контейнеров для изоляции пользовательских и системных пространств.
Узнайте больше про построение комплексных платформ хранения и обработки данных, а также использования возможностей Apache Spark для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники