 328
328 
Мы уже писали, что в выпуске 3.4.0 от апреля 2023 года Spark Connect представил несвязанную архитектуру клиент-сервер, которая обеспечивает удаленное подключение к кластерам Spark из любого приложения, работающего в любом месте. Сегодня рассмотрим подробнее, как это работает и каковы плюсы для практического использования.
Что такое Spark Connect и зачем это нужно
Изначально монолитная архитектура драйверов не позволяла подключаться к кластеру Spark с помощью языков, отличных от SQL и несовместимых с JVM. Также монолитная архитектура драйверов Spark вызывала проблемы со стабильностью систем, поскольку все приложения работают непосредственно на драйвере. Это допускает возникновение критических исключений по инициативе пользователей, таких как нехватка памяти, что может привести к отключению всего кластера. Из-за запутанных зависимостей платформенных и клиентских API, включая собственные и сторонние пути к классам, развитие фреймворка, а также отладка и наблюдаемость Spark-приложений тоже были проблематичными. У пользователей могли отсутствовать соответствующие разрешения безопасности для подключения к основному процессу Spark, тогда как отладка самого JVM-процесса могла снять все границы безопасности, установленные фреймворком. Дополнительную сложность вносила недоступность подробных журналов и системных метрики непосредственно в самом приложении и GUI, возможности которого мы рассматривали здесь и здесь.
Поэтому в версии 3.4.0, опубликованной в апреле 2023 года, была внедрена новая клиент-серверная архитектура Spark Connect. Это позволило разделить клиентский и серверный компоненты, обеспечивая удаленное подключение к кластерам Spark через API DataFrame и неразрешенные логические планы в качестве протокола, о чем мы подробно рассказываем в новой статье. Благодаря такому разделению между клиентом и сервером Spark, его можно использовать откуда угодно, включая различные IDE, интерактивные среды выполнения типа Google Colab и Jupyter Notebook, а также различные языки программирования. Кроме того, в эти среды можно встроить Spark Connect, чтобы обеспечить бесшовную интеграцию со Spark.
Примечательно, что впервые этот компонент еще год назад, в июле 2022, был представлен компанией Databricks, которая развивает Apache Spark и занимается коммерциализацией этой технологии. Подробно об этом мы писали здесь.
Архитектура и принципы работы
Клиентская библиотека Spark Connect представляет собой тонкий API, основанный на API DataFrame с использованием неразрешенных логических планов в качестве независимого от языка протокола между клиентом и драйвером Spark. Клиент Spark Connect преобразует операции DataFrame в неразрешенные планы логических запросов, которые кодируются с использованием буферов протокола. Они отправляются на сервер с помощью платформы gRPC. Конечная точка Spark Connect, встроенная в сервер Spark, получает и преобразует неразрешенные логические планы в операторы логического плана аналогично парсингу SQL-запроса, когда анализируются атрибуты и отношения и строится первоначальный план синтаксического анализа. После этого запускается стандартный процесс выполнения Spark, гарантирующий, что Spark Connect использует все оптимизации и улучшения Spark. Результаты передаются обратно клиенту через gRPC в виде пакетов строк, закодированных Apache Arrow.
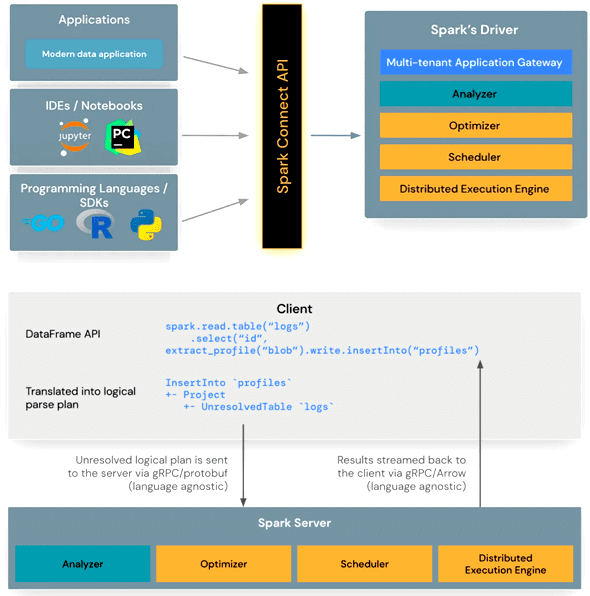
Таким образом, использование Spark Connect дает следующие возможности разработчику распределенных приложений, устраняя ряд операционных проблем:
- Улучшение стабильности, т.к. теперь приложения, использующие слишком много памяти, будут влиять только на свою собственную среду, поскольку работают в своих собственных процессах. Пользователи могут определять свои собственные зависимости от клиента, не беспокоясь о потенциальных конфликтах с драйвером Spark.
- Упрощенное обновление драйвера Spark, который теперь можно обновить независимо от приложений с поддержкой обратной совместимости с предыдущими версиями, если определения RPC на стороне сервера поддерживают это.
- Интерактивная отладка приложения во время его разработки непосредственно из IDE, а также мониторинг приложения с помощью собственных метрик платформы и библиотек журналов.
Чтобы использовать Spark Connect, необходимо включить этот пакет при запуске сервера Spark, обеспечив совпадение версий пакета с основной версией фреймворка. Например, для дистрибутива spark-3.4.0-bin-hadoop3.tgz нужен пакет org.apache.spark:spark-connect_2.12:3.4.0. Когда сервер Spark запущен, он готов принимать сеансы Spark Connect от клиентских приложений. Это можно сделать двумя способами:
- Через удаленную переменную среды SPARK_REMOTE на клиентском компьютере, где запущено клиентское приложение Spark, и создав новый сеанс Spark, который и будет сеансом Spark Connect. Этот подход позволяет оставить неизменным прежний код Spark-приложения, но использовать преимущества Spark Connect.
- явно указать на использование Spark Connect при создании сеанса Spark.
Хотя Spark Connect не имеет встроенной проверки подлинности, он предназначен для бесперебойной работы с существующей инфраструктурой аутентификации. Его gRPC-интерфейс с протоколом HTTP/2 позволяет использовать прокси-серверы для аутентификации, что позволяет защитить Spark Connect без необходимости непосредственно внедрять логику проверки подлинности пользователя в свое приложение.
В версии 3.4 Spark Connect поддерживает большинство API-интерфейсов PySpark, включая DataFrame, Functions и Column. Но некоторые API, такие как SparkContext и RDD, пока не поддерживаются. Такое ограничение отсутствует для большинства API-интерфейсов Scala, включая Dataset, Functions и Column. В будущих выпусках фреймворка запланирована поддержка большего количества API.
Освойте возможности Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

