
Сегодня рассмотрим новое унифицированное решение для хранения потоковых и пакетных таблиц, созданное на основе Apache Spark. Что такое Lakesoul, чем это лучше Apache Iceberg, Hudi и Deta Lake. Также разберем, в чем конкурентные преимущества этого табличного хранилища по сравнению с этими форматами открытых таблиц, включая поддержку upsert, управление метаданными и другие фичи, полезные для дата-инженера.
Архитектура LakeHouse и другие предпосылки появления нового табличного хранилища
Архитектура экосистемы больших данных постоянно развивается: появляются новые модели, например, LakeHouse, о чем мы писали здесь и здесь, есть яркая тенденция к объединению пакетной и потоковой парадигм обработки данных, а также стремительный уход в дешевые облачные хранилища. Общедоступные и частные облака обеспечивают абстракцию оборудования для вычислений и хранения, абстрагируя традиционные операции управления и обслуживания IaaS. При этом облачные вычисления и хранилища обеспечивают гибкие возможности, позволяя снизить затраты при одновременном улучшении использования ресурсов.
Ускорение темпов обработки информации приводит к тому, что хранилища на основе пакетной Hadoop-модели MapReduce не обеспечивают требования к минимальной задержке или ее отсутствию. Традиционная Lamda-архитектура не позволяет менять стратегии анализа данных «на лету», требуя повторных вычислений, а также сложна в реализации и эксплуатации. Поэтому вопрос создания эффективной системы хранилища данных с записью обновлений и анализом данных в реальном времени в недорогом облачном хранилище сегодня стал особенно актуальным.
Эту проблему стремится решить новая гибридная архитектура Data LakeHouse, которая сочетает преимущества озер и хранилищ данных, реализуя функции DWH на базе недорогого облачного хранилища в открытом формате. LakeHouse включает параллельное чтение и запись данных, механизмы управления данными, прямой доступ к исходным данным, разделение ресурсов хранения и вычислений. Также эта новая гибридная модель поддерживает открытые форматы хранения, структурированные и полуструктурированные данные, в т.ч. аудио и видео. Наконец, LakeHouse обеспечивает главное требование современного бизнеса – сквозную потоковую передачу и возможность работы с различными вычислительными движками: Spark Structured Streaming, Flink и пр., каждый из которых имеет свои особенности работы. Однако, с точки зрения технологической зрелости, LakeHouse намного проигрывает более зрелым подходам, таким как озеро данных (Data Lake) и традиционное DWH.
Таким образом, архитекторы Big Data платформ столкнулись с необходимостью объединить различные вычислительные движки и облачные хранилища с быстро меняющимися сервисами и правилами обработки данных. Для этого нужен набор идеальных платформ хранения, которые могут обеспечить высокую степень параллелизма данных, высокую пропускную способность чтения и записи, а также полную возможность управления облачным хранилищем. Эту проблему стремится решить новый унифицированный механизм хранения потоковых и пакетных таблиц под названием LakeSoul, о котором мы поговорим далее.
Что такое LakeSoul и при чем здесь Apache Spark с Cassandra
Одной из причин высокой популярности Apache Hive как основного инструмента стека SQL-on-Hadoop является наличие Metastore – хранилища метаданных, которое отвечает за виртуализацию коллекций данных в HDFS в виде таблиц. Главными конкурентами Hive Metastore считаются форматы открытых таблиц: Hudi, Delta Lake и Iceberg. Однако, они не реализуют все возможности Hive Metastore, поэтому не могут заменить это хранилище метаданных. Hudi и Delta Lake поддерживают изменчивость данных, Iceberg обеспечивает эффективность доступа к большим таблицам, а эволюцию схемы реализует Delta Lake. Но, к примеру, Hudi не предназначен для OLTP-сценариев и, несмотря на поддержку транзакций, не может заменить аналитическую In-Memory базу данных, хотя и поддерживает прием данных в режиме, близкому к реальному времени, с помощью механизма пакетирования. Подробнее об этом мы писали здесь.
Поэтому на практике именно Apache Hive чаще всего используется вместе с вычислительным движком Spark для запроса данных в Hadoop HDFS, играя роль вспомогательного слоя доступа к данным. Однако, как уже было отмечено выше, Hive реализует классическую пакетную Hadoop-парадигму MapReduce, а не сквозную потоковую передачу. Поэтому с учетом тенденций развития архитектуры данных возникает необходимость замены Apache Hive на потоковый инструмент для работы с неструктурированными данными с помощью SQL-запросов. Таким унифицированным решением с открытым исходным кодом может стать LakeSoul от команды DMetaSoul. LakeSoul представляет собой унифицированный механизм хранения потоковых и пакетных таблиц на базе Apache Spark, который поддерживает масштабируемое управление метаданными, ACID-транзакции, эффективную и гибкую операцию вставки-изменения (UPSERT) данных, эволюцию схемы, а также потоковую и пакетную унификацию.
UPSERT в LakeSoul реализуется на уровне строк и столбцов, а конкурентная запись выполняется с высокой скоростью и массовом сканированием данных в облачном хранилище. Архитектура облачных вычислений и разделения хранилища делает развертывание очень простым, поддерживая при этом огромные объемы данных с меньшими затратами.
LakeSoul специально оптимизирует добавочные обновления на уровне строк и столбцов, большое количество одновременных записей и чтение пакетного сканирования для данных поверх облачного хранилища Data Lake. LakeSoul поддерживает высокопроизводительную пропускную способность записи в upsert-сценариях для первичного ключа хешированного раздела через lSM-дерево. В частности, для AWS S3 эта пропускная способность может достигать 30 МБ/с на ядро. Высокооптимизированная реализация слияния при чтении также обеспечивает производительность чтения. LakeSoul управляет метаданными через Cassandra для достижения высокой масштабируемости метаданных. Во 2-ой версии LakeSoul взаимодействие с метаданными и базой данных полностью реализовано с использованием протокола PostgreSQL, т.к. Cassandra не поддерживает однотабличные многораздельные транзакции и управление кластером Cassandra более затратно, чем Postgres.
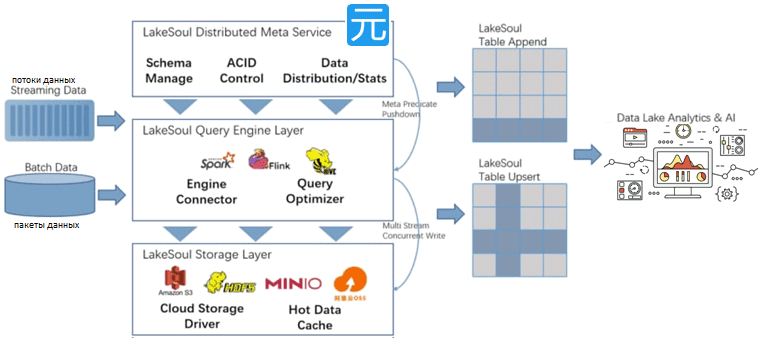
LakeSoul на основе Apache Spark обладает следующими характеристиками:
- эластичная структура с полным разделением вычислений и хранилища. Без необходимости в фиксированных узлах и дисках механизмы вычисления и хранения данных имеют собственную эластичную емкость. Облачное хранилище оптимизировано для обеспечения согласованности параллелизма и upsert-операций. С LakeSoul не нужно поддерживать фиксированные узлы для хранения данных, а стоимость облачного объектного хранилища составляет около 10% стоимости локального диска, что значительно снижает затраты на хранение и эксплуатацию Big Data системы.
- эффективное и масштабируемое управление метаданными – LakeSoul использует внешнюю базу данных для управления метаданными, которая может эффективно обрабатывать изменения метаданных и поддерживать несколько операций конкурентной записи. Это решает проблемы медленного анализа метаданных после долгой работы в системах озера данных, которые используют файлы для хранения метаданных.
- ACID-транзакции – механизм Undo and Redo гарантирует, что фиксация является транзакционной, и пользователи никогда не увидят несогласованные данные.
- Многоуровневое партиционирование и эффективный upsert. LakeSoul поддерживает разделение данных по диапазонам и хэшам, а также upsert на уровне строк и столбцов. Данные upsert хранятся в виде дельта-файлов, что повышает эффективность и параллелизм записи, а оптимизированное сканирование слиянием обеспечивает эффективную производительность метода MergeOnRead.
- Потоковая и пакетная унификация со Streaming Sink, что позволяет одновременно обрабатывать потоковые данные, заполнение исторических данных в пакетном режиме, выполнять интерактивные запросы и другие сценарии.
- Эволюция схемы – пользователи могут добавлять новые поля в любое время и быстро заполнять новые поля историческими данными.
Таким образом, для практического применения LakeSoul отлично подходит в случаях, когда добавляемые данные надо эффективно записывать большими пакетами в режиме реального времени, а также выполнять одновременные обновления на уровне строк или столбцов. Другим примером сценария использования этого унифицированного решения является подробный запрос и обновление данных в большом временном диапазоне с огромным количеством исторических данных при сохранении низкой стоимости. Или запрос не является фиксированным, а потребление ресурсов сильно меняется, поэтому нужны гибкие и независимо масштабируемые вычислительные ресурсы. Наконец, LakeSoul на базе Apache Spark подойдет, если нужно много одновременных операций записи, а метаданные слишком велики для Delta Lake, чтобы соответствовать требованиям производительности или для обновления данных первичных ключей требуется высокая скорость записи. Читайте в нашей следующей статье о деталях реализации LakeSoul.
Узнайте больше про архитектуру и аналитику больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

