 706
706 
Содержание
Недавно мы писали про Lakesoul – новое унифицированное решение для хранения потоковых и пакетных таблиц, которое реализует архитектуру данных LakeHouse. Сегодня заглянем под капот этого унифицированного механизма на базе Apache Spark и разберемся с преимуществами его последнего релиза.
Как работает LakeSoul: краткий обзор
Напомним, LakeSoul от команды DMetaSoul представляет собой унифицированный механизм хранения потоковых и пакетных таблиц на базе Apache Spark, который поддерживает масштабируемое управление метаданными, ACID-транзакции, эффективную и гибкую операцию вставки-изменения (UPSERT) данных, эволюцию схемы, а также потоковую и пакетную унификацию. Это решение соответствует новой гибридной архитектуре данных под названием LakeHouse, которая стремится объединить достоинства классических DWH с преимуществами гибкого озера данных (Data Lake), о чем мы писали здесь и здесь.
LakeSoul поддерживает многоуровневое управление разделами, несколько разделов диапазона и один хеш-раздел на уровне раздела таблицы. В реальном бизнес-сценарии большое хранилище данных будет отправлять большой объем информации о разделах на уровень метаданных после длительного обновления. Для сценариев обновления в реальном времени отправка происходит чаще. При этом часто встречается инфляция метаданных, что приводит к низкой эффективности доступа к метаданным. Производительность метаданных сильно влияет на производительность запросов, поскольку во время запроса данных необходимо получить доступ к информации о разделах и другой базовой информации о распределении данных в метаданных. Поэтому для хранилища данных важна высокопроизводительная и расширяемая служба метаданных.
LakeSoul использует мощную распределенную NoSQL-СУБД Cassandra для управления метаданными. Это децентрализованное масштабируемое решение предоставляет богатые методы моделирования данных и высокую пропускную способность чтения/записи. В качестве хранилища метаданных Cassandra обеспечивает настраиваемые уровни доступности и согласованности, простое управление параллелизмом и ACID для операций с метаданными.
LakeSoul организует первичный ключ и индекс таблицы уровня метаданных. Для раздела конечного уровня требуется только одна операция с первичным ключом, чтобы получить всю информацию об этом разделе, прочитать и записать моментальный снимок (snapshot) текущей версии и пр. Snapshot раздела содержит полный путь к файлу и тип фиксации для полной записи и операций upsert. Этот план чтения раздела может быть построен путем последовательного обхода фиксаций файлов в моментальном снимке. Такой доступ к информации о разделах позволяет избежать обхода файлов и каталогов, необходимого метода оптимизации для объектных хранилищ типа AWS S3 и OSS.
В отличие от Apache Hive, которая использует слабомасштабируемую реляционную СУБД MySQL в качестве уровня хранения метаданных, благодаря Cassandra LakeSoul поддерживает на порядок больше разделов в одной таблице. Аналогичное преимущество LakeSoul можно отметить по сравнению с Apache Iceberg и Delta Lake, которые используют файловые системы для хранения метаданных.
Чтобы обеспечить согласованность одновременной записи и чтения данных, LakeSoul поддерживает транзакции ACID и одновременные обновления. В отличие от OLTP-сценария, обновления Lakehouse являются гранулированными на уровне файлов. LakeSoul использует облегченную транзакцию Cassandra для реализации обновлений на уровне разделов. Как и многие NoSQL-СУБД, Cassandra по-своему реализует ACID-требования к транзакциям. В частности, она может обеспечить обновленную атомарность и изоляцию с помощью LWT (Light Weight Transaction) – механизма легковесных транзакций. А доступность и согласованность можно контролировать с помощью гибко настраиваемых уровней согласованности Cassandra.
В частности, когда вычислительный механизм создает файлы для каждого раздела для фиксации, он сначала фиксирует информацию об обновлении файла раздела, такую как полное или добавочное обновление (upsert), а затем обновляет видимую для читателя версию через LWT. В сценариях, где обнаруживаются одновременные обновления, LakeSoul автоматически различает типы записи, чтобы определить, есть ли конфликт, и следует ли повторно отправить данные напрямую или откатить операцию.
LakeSoul поддерживает несколько механизмов обновления, включая Append, Overwrite и Upsert. Общие записи потоковой передачи журнала обычно находятся в Append. В этом случае уровень метаданных должен записывать только пути к файлам, добавляемые каждым разделом. В то же время задание на чтение данных единообразно считывает все присоединенные файлы в разделе, чтобы выполнить слияние при чтении. Для ситуаций перезаписи, когда обновление/удаление происходит в произвольных условиях или когда происходит уплотнение, LakeSoul использует механизм копирования при записи для обновления.
LakeSoul поддерживает более эффективный механизм Upsert в случае хеш-разделов и операций для хеш-ключей. В каждом сегменте хеширования LakeSoul сортирует файлы по ключу хеша. После многократного выполнения Upsert получается несколько упорядоченных файлов, которые сливаются при операции чтении.
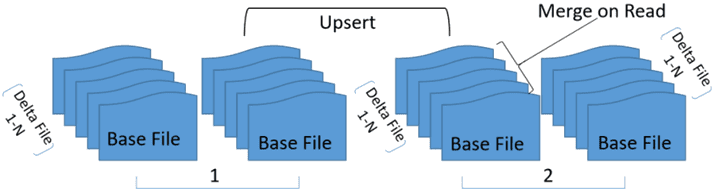
Таким образом, LakeSoul достигает высокой пропускной способности записи при сохранении скорости чтения за счет оптимизированного упорядоченного слияния файлов. Чтобы предоставить эффективные возможности хранилища данных в реальном времени, LakeSoul поддерживает сценарии захвата обновленных данных (CDC, Change Data Capture), предоставляя отдельный набор семантических выражений. LakeSoul может взаимодействовать с различными источниками сбора измененных данных, такими как Debezium, Flink и Canal, путем указания столбца операции в таблице CDC. Этот столбец действий источника коллекции можно преобразовать в столбец CDC-действий LakeSoul. В случае онлайн-синхронизации с OLTP-СУБД принимающая таблица LakeSoul также может использовать метод хэширования и записывать CDC в Upsert для хешированных ключей, достигая очень высокой скорости.
На практике это полезно в таких сценариях, как синхронизация CDC-отчетов в режиме реального времени с хранилищами и витринами данных. Если для этого использовать базу данных периодического дампа, задержки и накладные расходы на хранение данных становятся слишком велики. А движки для вычислений в реальном времени типа Apache Flink требуют много ресурсов для разработки и обслуживания приложений. CDC-синхронизация с LakeSoul в реальном времени и преобразование в Upsert в случае операции с первичным ключом позволяют достичь чрезвычайно высокой пропускной способности записи. Изменения в базе данных могут быть синхронизированы с DWH практически в режиме реального времени, чтобы быстро выполнить BI-анализ онлайн-данных с помощью SQL-запроса. С этой задачей отлично справляется Debezium — сервис захвата изменений в базах данных и отправки их на обработку в другие системы, о чем мы писали здесь и здесь. Применение CDC в Data Lake может значительно упростить архитектуру обновления данных в режиме реального времени.
Также отметим еще один пример практического использования LakeSoul для построения образца базы данных рекомендательной системы в режиме реального времени. Общим требованием в этом сценарии является объединение нескольких таблиц, включая характеристики пользователей, характеристики продукта, метки воздействия и метки кликов, для библиотеки обучающих примеров ML-модели. Офлайн-соединение больших таблиц имеет проблемы с низкой своевременностью и высоким потреблением вычислительных ресурсов. Обойти это ограничение можно, используя Flink для выполнения многопотокового соединения в реальном времени. Но в случае большого временного окна это потребляет много ресурсов. LakeSoul может преобразовать многопотоковое соединения в параллельный Upsert. Поскольку разные потоки имеют один и тот же первичный ключ, его можно установить на ключ хеш-раздела для Upsert, что даже в случае большого временного окна обеспечит высокую пропускную способность записи.
Что нового во 2-ой версии и при чем здесь Apache Spark
В конце июля 2022 года команда DMetaSoul выпустила новую версию LakeSoul — 2.0, где служба каталога отделена от Apache Spark, чтобы реализовать независимую структуру и интерфейс хранения метаданных. Spark, Flink, Presto и другие вычислительные движки могут взаимодействовать с LakeSoul для обеспечения потоковой передачи и пакетной интеграции. Теперь DDL-запросы и функции датасета в Spark SQL тесно взаимодействуют с каталогом. Информация о созданной таблице хранится в Каталоге. Для этого в LakeSoul перенастроен интерфейс Spark Scala.
Приемник данных (DataSink) Spark включает в себя не только информацию о метаданных, но и обнаружение конфликтов данных файлов данных и разделов, когда потоковая пакетная задача записывает данные. Поэтому скорректирован интерфейс работы с данными после завершения задания Spark. Обнаружение конфликтов фиксации данных секционирования также перенесено в Каталог.
Слияние при чтении (Merge On Read) оптимизировано для источника данных Spark. Ранее при чтении данных файлы сортировались по номеру версии записи. Поэтому при слиянии последняя версия по умолчанию перезаписывала данные прежней версии. В LakeSoul 2.0 атрибут записи версии для файлов данных удален вместо использования упорядоченного списка файлов с последним файлом сборки в конце списка.
В заключение отметим, что LakeSoul 2.0 также поддерживает унифицированную потоковую передачу и пакетную запись Flink, а также реализует семантику строго однократной доставки сообщений exactly-once. Это обеспечивает точность данных для Flink CDC и других сценариев, сочетая возможности Merge On Read и Schema AutoMerge, что важно для слияния нескольких таблиц и баз данных.
Узнайте больше про архитектуру и аналитику больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

