 430
430 
Содержание
В недавней статье про преимущества хранилища метаданных Apache Hive и другие плюсы этого популярного инструмента SQL-on-Hadoop, мы упоминали формат открытых таблиц Iceberg как альтернативу для хранения огромных наборов аналитических данных. Он добавляет высокопроизводительные SQL-подобные таблицы в вычислительные механизмы Spark, Trino, Presto, Flink и Hive. Сегодня рассмотрим подробнее, что такое Apache Iceberg и как он используется в современных озерах данных.
Проблемы озера данных на Hadoop HDFS и средства их решения
Озеро данных (Data Lake) – это не просто склад информации в различных форматах, а хранилище потенциально полезных бизнес-сведений. Поэтому оно должно обеспечивать эффективный и надежный механизм изменения и транзакций данных. Пользователи Data Lake часто создают отчеты на основе одного набора данных, который постоянно меняется по мере поступления новых пакетов или потоков. Некоторые данные поступают с опозданием, другие меняются со временем, у третьих модифицируется состояния и пр. – все это необходимо учесть при создании бизнес-отчетов.
Однако, изначально распределенная файловая система Hadoop (HDFS) и хранилища объектов типа AWS S3, на которых чаще всего строятся озера данных, не были предназначены для поддержки транзакций. Реализация транзакций в средах распределенной обработки довольно сложная задача. Например, необходимо учесть блокировку доступа к системе хранения, что достигается за счет общей пропускной способности. Эти проблемы решают специальные системы, развертываемые поверх Data Lake, такие как Apache CarbonData, Apache Iceberg, Open Delta и Apache Hudi. Они обеспечивают поддержку ACID-транзакций для озер данных, вставляя эту транзакционную семантику и правила в сами форматы файлов или с использованием метаданных [1].
CarbonData является старейшей технологией на этом на рынке, поэтому имеет некоторые конкурентные преимущества благодаря наличию материализованных представлений, вторичного индекса и интеграции с множеством потоковых и AI-движков: Apache Spark, Flink, Presto, Hive и TensorFlow. Благодаря тесной интеграции с Apache Spark, CarbonData может пользоваться преимуществами оптимизации производительности этого фреймворка: векторизация, удаление предикатов, вычисление статистик и предподготовка данных (удаление/заполнение пропусков, очистка, сжатие и удаления сегментов с возможностью восстановления файлов).
Основным преимуществом Apache Hudi является высокая производительность при чтении и поддержка потокового режима приема данных в виде непрерывного цикла пакетной обработки. Apache Hudi поддерживает различные механизмы запросов, такие как Flink и Spark.
Delta Lake на базе Apache Spark, о котором мы рассказывали здесь, здесь и здесь, также имеет ряд специфических преимуществ. В частности, интегрированный пакетно-потоковый дизайн, оптимизация производительности за счет Spark: векторизация, поддержка столбцового формата данных Parquet, функции предобработки данных. Также у Delta Lake гибкий пользовательский API и подробная документация, поддерживаемая Databricks.
Apache Iceberg не привязан к какому-либо конкретному движку и обладает наилучшей степенью абстракции с точки зрения чтения и записи, а также использования хранилища и формата файлов. Он имеет встроенную оптимизацию, такую как предикатное выталкивание, и собственный векторизованный считыватель. Iceberg устранит проблемы с производительностью, связанные с перечислением объектов S3 или перечислением разделов Hive Metastore. Но в Iceberg есть некоторые сложности с поддержкой удалений и изменений данных, а их сохранение связано с операционными накладными расходами. Об этом мы подробнее поговорим далее.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
15 декабря, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Что такое Apache Iceberg и как он работает: краткий ликбез
Apache Iceberg можно рассматривать средство для вычислительных движков (Spark, Trino, PrestoDB, Flink и Hive), которое позволяет им применять табличный формат поверх форматов файлов, таких как Parquet или ORC, находящихся в хранилище Data Lake. Таким образом, подобно идее SQL-on-Hadoop, Iceberg позволяет работать с файлами в озере данных как со структурированными таблицами через язык SQL-запросов. Изначально Iceberg был разработан компанией Netflix для собственных нужд, а в мае 2020 года стал open-source проектом Apache Software Foundation.
С самого начала Iceberg создавался для огромных таблиц с десятками петабайт данных, позволяя читать их без распределенного механизма SQL. Пользователям не нужно знать о разделении, чтобы быстро получать ответы на свои запросы. При этом Iceberg поддерживает эволюцию схемы данных: добавление, удаление, обновление и переименование столбцов, а скрытое разбиение на разделы предотвращает ошибки пользователя.
Являясь табличной надстройкой над файловыми форматами, Iceberg отлично работает поверх ORC, Avro или Parquet, а также превосходно интегрируется с исполнительными движками: Apache Hive, Spark, Flink и Presto. Также этот открытый формат таблицы работает с любым облачным хранилищем и снижает нагрузку в HDFS, избегая перечисления и переименования за счет метаданных. Будучи разработанным для решения проблем корректности в постоянно согласованных хранилищах облачных объектов, Iceberg обеспечивает расширенную фильтрацию, удаляя файлы данных вместе со статистикой на уровне разделов и столбцов с использованием метаданных таблицы. При этом изменения таблицы атомарны: читатели не увидят частичные или незафиксированные изменения. Несколько параллельных писателей используют оптимистичный параллелизм и будут повторять попытки, чтобы гарантировать успешное выполнение совместных обновлений, даже в случае конфликта записи. Поэтому все операции записи выполняются изолированно, не влияя на текущее чтение или текущую схему в метаданных.
Благодаря отсутствию распределенного механизма SQL при чтении таблицы или поиске файлов, планирование сканирования выполняется быстро. Кроме того, Iceberg не требует перечисления файлов, а поддерживает данные в манифестах. Iceberg поддерживает разные уровни разделения в одной и той же схеме данных, а также изоляцию между чтением и записью, сохраняя снимки файлов, которые менялись с течением времени. Это обеспечивает параллельное, но изолированное выполнение операций чтения и записи. Если новая запись не зафиксирована, этот снимок будет недоступен для чтения.
Наконец, Iceberg поддерживает управление версиями, позволяя вернуться к предыдущей версии схемы данных. Метаданные хранятся параллельно с файлами данных. В файле метаданных моментального снимка (snapshot) хранятся спецификации таблицы: ее схема, столбцы партиционирования и путь к списку манифестов, каждый из которых указывает на определенную версию файла [2].
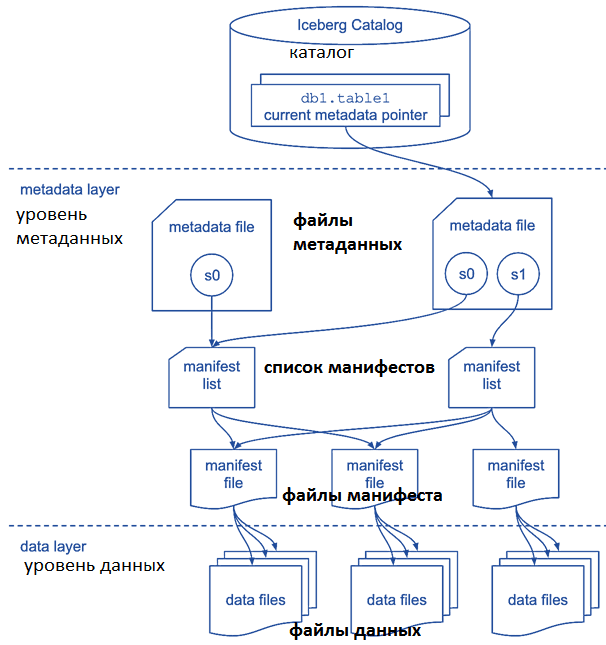
Эту эволюционную особенность Iceberg стоит учитывать при практическом использовании: с течением времени количество snapshot’ов, как и размер файлов метаданных, постоянно растет. Поэтому рекомендуется сохранить несколько версий моментальных снимков, архивировав или удалив snapshot’ы с истекшим сроком действия. Например, потерянные файлы метаданных, которые не были зафиксированы во время записи, можно обработать повторно или удалить их, используя метод API RemoveOrphanFilesAction() [3].
Это действие удаляет потерянные метаданные и файлы данных, перечисляя заданное местоположение и сравнивая фактические файлы в этом месте с файлами данных и метаданных, на которые ссылаются все действительные snapshot’ы. Местоположение должно быть доступно для перечисления через файловую систему Hadoop. По умолчанию вызов RemoveOrphanFilesAction() очищает местоположение таблицы, возвращаемое методом Table.location(), и удаляет недоступные файлы старше 3 дней с помощью Table.io(). Поведение можно изменить, передав пользовательское местоположение в location и пользовательскую метку времени в oldThan(long). Например, можно применить это действие к папке с данными, чтобы очистить только потерянные файлы данных или настроить альтернативный метод удаления через метод deleteWith(Consumer). Стоит отметить, что опасно вызывать это действие с коротким интервалом хранения из-за риска повреждения состояния таблицы, если при этом выполняется другая операция записи [4].
Практическое использование Iceberg довольно просто, т.к. этот открытый формат таблицы представляет собой просто Java-библиотеку, которую легко встроить в текущие приложения или собственный SDK. Например, именно так и поступили дата-инженеры компании Adobe, встроив Iceberg в Adobe Experience Platform SDK, который использует API источника данных Apache Spark для подключения различных серверных модулей. Это позволило компании совместить пакетный и потоковый режимы обработки данных в одном Data Lake на базе облачного хранилища Azure, чтобы поддерживать сразу несколько бизнес-сценариев аналитики больших данных, от обработки временных рядов до ad-hoc запросов с помощью Spark-приложений [5]. Как это было сделано, мы рассмотрим в следующий раз. Аналогичным опытом использования Apache Iceberg вместо Hive делятся дата-инженеры Airbnb, что мы разбираем здесь.
А подробнее узнать про тонкости построения и эксплуатации Data Lake для эффективной аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Узнайте больше про построение надежных архитектур для мощных дата-платформ в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, архитекторов, инженеров, администраторов, Data Scientist’ов, менеджеров и аналитиков Big Data в Москве:
Источники
- https://brijoobopanna.medium.com/comparative-study-of-apache-iceberg-open-delta-apache-carbondata-and-hudi-c3962e5a0c4a
- https://iceberg.apache.org/
- https://ajithshetty28.medium.com/as-cool-as-iceberg-bb7d93084c72
- https://iceberg.apache.org/javadoc/0.8.0-incubating/org/apache/iceberg/actions/RemoveOrphanFilesAction/
- https://medium.com/adobetech/iceberg-at-adobe-88cf1950e866

