 2274
2274 
Содержание
- Определение и концепция
- Фундаментальные характеристики Data Lake
- Политика хранения данных (Retention Policy)
- Неизменность хранимых данных (Immutability)
- Архитектура и технические характеристики
- Основные компоненты и инфраструктура
- Форматы данных и технологии хранения
- Data Governance и управление качеством данных
- Система управления данными
- Data Quality и контроль качества
- Data Lineage и Provenance
- Преимущества и недостатки
- Ключевые преимущества озер данных
- Основные недостатки и ограничения
- Сравнение с хранилищами данных и современные гибридные подходы
- Традиционные различия и эволюция архитектур
- Современное понимание интеграции
- Использование и практические применения
- Отраслевые применения и сценарии использования
- Технологические лидеры и инновации
- Современные тенденции и будущее развитие
- Инновационные технологии следующего поколения
- Искусственный интеллект и автоматизация
- Облачные технологии и serverless архитектуры
- Emerging технологии и будущие направления
- Дополнительные источники и литература
Data Lake (озеро данных) — это логическая совокупность репозиториев данных, предназначенных для хранения и анализа больших данных в их исходном формате. В отличие от традиционного понимания централизованного хранилища, Data Lake может быть распределенным по множеству физических местоположений, включая облачные платформы, on-premises инфраструктуру или гибридные среды. Концепция озера данных представляет собой эволюционный подход к управлению корпоративными данными, обеспечивающий гибкость, масштабируемость и экономическую эффективность в условиях постоянно растущих объемов информации.

Определение и концепция
Озеро данных представляет собой архитектурный подход, который позволяет организациям хранить огромные объемы данных в их натуральном формате до тех пор, пока они не понадобятся для анализа. Этот подход основан на принципе «схема при чтении» (schema-on-read) в противоположность традиционному подходу «схема при записи» (schema-on-write), используемому в реляционных базах данных и хранилищах данных. Такая философия обеспечивает максимальную гибкость в работе с данными и позволяет адаптироваться к изменяющимся требованиям бизнеса без необходимости перестройки всей инфраструктуры.
Ключевой особенностью озера данных является его способность служить единой логической точкой входа для всех типов корпоративных данных, независимо от их структуры, источника или физического местоположения. Это создает основу для создания всеобъемлющей экосистемы данных, где различные системы и приложения могут эффективно взаимодействовать и обмениваться информацией через унифицированные интерфейсы доступа.
Фундаментальные характеристики Data Lake
Политика хранения данных (Retention Policy)
Retention Policy определяет жизненный цикл данных в озере и является критически важным аспектом управления информацией. Эта политика устанавливает правила того, как долго различные типы данных должны храниться, когда они должны быть перемещены в более дешевые уровни хранения, и когда они могут быть безопасно удалены. Политика хранения включает несколько ключевых аспектов: временные рамки хранения для различных категорий данных (от нескольких месяцев до десятилетий в зависимости от регулятивных требований), автоматическое управление жизненным циклом с переводом данных между «горячими», «теплыми» и «холодными» уровнями хранения, соблюдение регулятивных требований таких как GDPR, HIPAA, SOX, которые могут требовать хранения данных в течение определенных периодов, и оптимизацию затрат через автоматическое удаление устаревших данных и использование более дешевых систем хранения для редко используемой информации.
Неизменность хранимых данных (Immutability)
Immutability является второй фундаментальной характеристикой Data Lake, обеспечивающей целостность и надежность аналитических процессов. Принцип неизменности означает, что данные, однажды записанные в озеро, не могут быть изменены или удалены — они остаются в неизменном виде на протяжении всего срока хранения. Это свойство критически важно для обеспечения reproducibility исследований и аналитических процессов, audit trail для соблюдения регулятивных требований, data integrity и защиты от случайного или преднамеренного искажения данных, а также версионирования данных с возможностью отслеживания всех изменений и обновлений. Неизменность реализуется через технологии append-only логов, версионные файловые системы, и специализированные форматы хранения такие как Delta Lake и Apache Iceberg, которые поддерживают ACID-транзакции и time travel queries.
Архитектура и технические характеристики
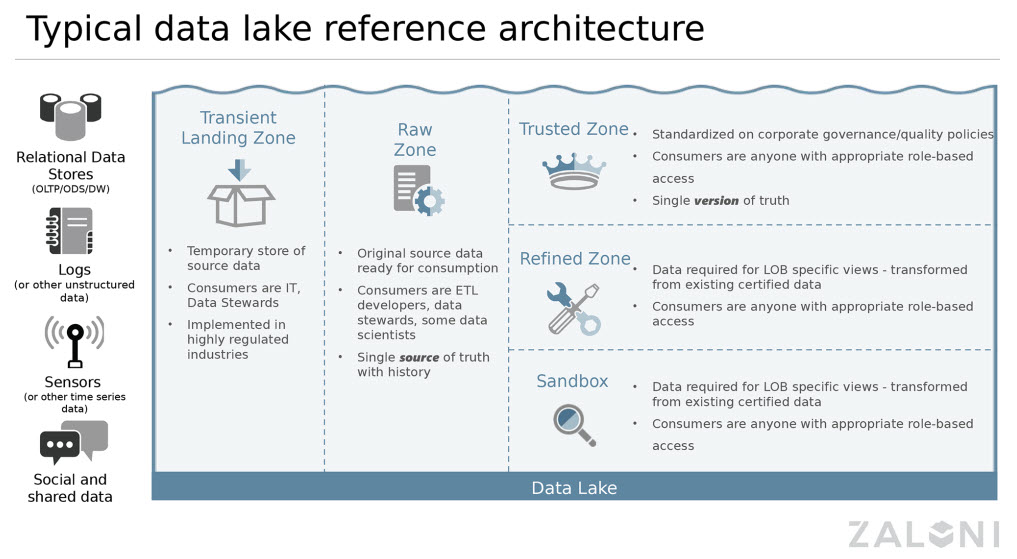
Основные компоненты и инфраструктура
Современная архитектура Data Lake представляет собой многоуровневую систему, которая может быть физически распределена по различным географическим регионам и облачным провайдерам. Слой хранения образует фундамент озера данных и может включать распределенные файловые системы такие как Apache Hadoop Distributed File System (HDFS), объектные хранилища облачных провайдеров включая Amazon S3, Azure Data Lake Storage, Google Cloud Storage, а также гибридные решения, объединяющие on-premises и облачные компоненты. Этот слой обеспечивает практически неограниченную масштабируемость, географическую распределенность для соответствия требованиям data residency, автоматическую репликацию для обеспечения отказоустойчивости, и экономическую эффективность через использование различных классов хранения.
Слой обработки и вычислений представляет собой распределенную вычислительную платформу, способную масштабироваться от нескольких узлов до тысяч серверов в зависимости от потребностей обработки. Он включает Apache Spark для универсальной обработки больших данных с поддержкой пакетной и потоковой обработки, Apache Flink для потоковой обработки в реальном времени с гарантиями exactly-once delivery, Apache Kafka для высокопроизводительной обработки потоков событий, специализированные системы машинного обучения такие как TensorFlow, PyTorch, Apache MLlib, и современные движки для SQL-запросов включая Apache Drill, Presto, и Apache Impala. Этот слой поддерживает множество языков программирования включая SQL, Python, R, Scala, Java, что обеспечивает гибкость для различных специалистов.
Слой управления метаданными и каталогизации является критически важным компонентом, который обеспечивает Data Governance и предотвращает превращение озера данных в «болото данных» (data swamp). Современные решения включают Apache Atlas для комплексного управления метаданными корпоративного уровня, AWS Glue Data Catalog для автоматического обнаружения схем и ETL процессов, Apache Hive Metastore для управления структурированными данными, инновационные платформы такие как DataHub для создания каталогов данных нового поколения. Этот слой также обеспечивает Data Lineage — отслеживание происхождения и трансформаций данных, Provenance — детальную историю создания и изменения данных, и Data Quality мониторинг с автоматическими проверками качества и целостности информации.
Слой безопасности и управления доступом обеспечивает комплексную защиту данных на всех уровнях архитектуры через множество механизмов безопасности. Он включает системы аутентификации и авторизации такие как Apache Ranger, AWS IAM, Azure AD, многоуровневое шифрование данных как в покое (encryption at rest), так и в движении (encryption in transit), используя алгоритмы AES-256 и TLS 1.3, подробный аудит всех операций с данными для соблюдения compliance требований, интеграцию с корпоративными системами управления идентификацией включая Active Directory, LDAP, SAML, OAuth 2.0, а также продвинутые механизмы защиты включая row-level security, column-level encryption, и dynamic data masking для защиты чувствительной информации.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
27 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Форматы данных и технологии хранения
Data Lake поддерживает всеобъемлющую экосистему форматов данных, что является одним из его ключевых конкурентных преимуществ. Структурированные данные включают традиционные форматы такие как CSV, JSON, XML, Avro, а также данные из реляционных баз данных, которые могут быть импортированы через современные ETL/ELT процессы с использованием инструментов CDC (Change Data Capture). Полуструктурированные данные охватывают широкий спектр источников включая логи веб-серверов и приложений, данные сенсоров IoT с различными протоколами передачи, информацию из социальных сетей и API ответы в формате JSON/XML, конфигурационные файлы систем, метрики производительности и мониторинга. Неструктурированные данные включают текстовые документы различных форматов, мультимедийные файлы (изображения, видео, аудио), презентации, электронные письма, и другие бинарные данные.
Для оптимизации производительности аналитических запросов и значительного снижения затрат на хранение активно используются современные колоночные форматы данных. Apache Parquet обеспечивает превосходное сжатие данных (часто в 5-10 раз лучше традиционных форматов), поддерживает предикатные фильтры и column pruning для ускорения запросов, совместим со всеми основными аналитическими движками. Apache ORC (Optimized Row Columnar) предоставляет аналогичные преимущества с дополнительной оптимизацией для Hive экосистемы. Delta Lake добавляет ACID-транзакции, time travel capabilities, и schema evolution поверх Parquet формата. Apache Iceberg и Apache Hudi представляют новое поколение табличных форматов с поддержкой современных требований к управлению данными.
Data Governance и управление качеством данных
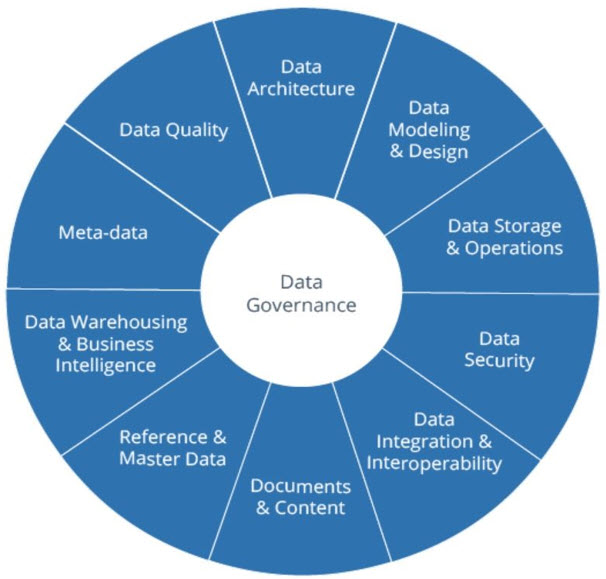
Система управления данными
Data Governance в контексте Data Lake представляет собой комплексную систему политик, процедур, и технологических решений, обеспечивающих эффективное управление данными на всех этапах их жизненного цикла. Эта система включает определение владельцев данных (data owners) и распределение ответственности за различные датасеты, установление политик доступа с детальным контролем на уровне пользователей, ролей, и отдельных данных, стандартизацию форматов данных и методологий их обработки для обеспечения консистентности, мониторинг соответствия регулятивным требованиям включая GDPR, CCPA, HIPAA, и отраслевые стандарты. Система также включает процедуры для управления метаданными, каталогизации данных, и обеспечения прозрачности использования информации во всей организации.
Data Quality и контроль качества
Data Quality является критически важным аспектом управления Data Lake, поскольку качество входящих данных напрямую влияет на точность аналитических результатов и бизнес-решений. Система контроля качества включает автоматическую валидацию данных при поступлении с проверкой форматов, диапазонов значений, и бизнес-правил, профилирование данных для понимания статистических характеристик и выявления аномалий, детекцию дубликатов и несогласованностей между различными источниками данных, мониторинг полноты данных и выявление пропущенных значений или записей, а также отслеживание качества во времени для идентификации деградации данных. Современные решения используют машинное обучение для автоматического обнаружения проблем качества и предложения стратегий их исправления.
Data Lineage и Provenance
Data Lineage обеспечивает полную видимость происхождения данных и всех трансформаций, которые были применены к ним в процессе их движения через Data Lake. Эта система критически важна для аудита и соответствия требованиям, отладки аналитических процессов, оценки влияния изменений в данных или процессах обработки, и обеспечения доверия к аналитическим результатам. Provenance предоставляет еще более детальную информацию о контексте создания данных, включая временные метки, источники, методы сбора, версии используемого программного обеспечения, и других факторов, которые могут влиять на интерпретацию данных. Современные системы автоматически собирают информацию о lineage и provenance, создавая интерактивные графы зависимостей данных и предоставляя API для интеграции с другими системами управления данными.
Преимущества и недостатки
Ключевые преимущества озер данных
Архитектурная гибкость и масштабируемость представляют собой одни из наиболее значимых преимуществ Data Lake, позволяя организациям адаптироваться к быстро изменяющимся требованиям бизнеса и технологическому развитию. Возможность хранения данных в исходном формате без необходимости предварительного определения схемы особенно ценна при работе с разнообразными источниками данных, включая IoT сенсоры, социальные медиа, внешние API, и legacy системы с различными форматами данных. Распределенная архитектура позволяет практически неограниченно масштабировать систему как горизонтально (добавление новых узлов), так и вертикально (увеличение ресурсов существующих узлов), что обеспечивает поддержку роста объемов данных от терабайтов до эксабайтов без необходимости фундаментальных изменений архитектуры.
Экономическая эффективность и оптимизация затрат достигается через использование современных облачных технологий и экономичных систем хранения. Объектные хранилища в облаке стоят значительно дешевле традиционных реляционных баз данных, особенно при хранении больших объемов данных в различных классах хранения (hot, warm, cold, archive). Модель pay-as-you-use позволяет организациям платить только за фактически используемые ресурсы, что особенно важно для компаний с сезонными колебаниями нагрузки или непредсказуемыми паттернами роста данных. Возможность использования spot instances и preemptible VMs может дополнительно снизить затраты на вычислительные ресурсы до 90% для некритичных рабочих нагрузок.
Поддержка современных аналитических сценариев включает широкий спектр применений от традиционной бизнес-аналитики до продвинутых алгоритмов искусственного интеллекта. Data Lake нативно поддерживает пакетную обработку для больших исторических датасетов, потоковую обработку для real-time аналитики, машинное обучение с интеграцией популярных фреймворков, интерактивные SQL запросы для ad-hoc анализа, и graph analytics для анализа сложных связей в данных. Возможность объединения различных типов данных в едином аналитическом процессе открывает новые возможности для получения insights, которые были бы недоступны при использовании изолированных систем.
Основные недостатки и ограничения
Сложность управления и операционные вызовы значительно возрастают с увеличением объема, разнообразия данных и количества пользователей системы. Без должного управления и четко определенных процессов Data Lake может быстро превратиться в «болото данных» (data swamp), где поиск нужной информации становится крайне затруднительным, данные дублируются без контроля, а качество информации деградирует со временем. Управление распределенной системой требует специализированных навыков включая глубокое понимание больших данных, облачных технологий, современных методов DevOps и DataOps, что может привести к необходимости найма дорогостоящих специалистов или значительных инвестиций в обучение существующих сотрудников. Операционная сложность также включает мониторинг производительности множества компонентов, управление версиями данных и схем, оптимизацию затрат, и обеспечение высокой доступности системы.
Вызовы качества данных и управления возникают из-за фундаментального принципа «схема при чтении», который, обеспечивая гибкость, одновременно создает риски для качества и консистентности данных. Отсутствие строгого контроля при загрузке данных может привести к накоплению некачественных данных включая дубликаты, неполные записи, устаревшую информацию, данные с форматными ошибками, и противоречивую информацию из различных источников. Проблемы качества могут проявляться не сразу, а накапливаться со временем, становясь критическими для аналитической экосистемы организации только когда исправление требует значительных ресурсов. Обеспечение Data Quality требует постоянного мониторинга, автоматизированных проверок качества, и четко определенных процессов исправления выявленных проблем.
Безопасность и соответствие регулятивным требованиям представляют комплексные вызовы при работе с разнообразными данными в распределенной архитектуре. Необходимость соблюдения различных регулятивных требований таких как GDPR в Европе, CCPA в Калифорнии, HIPAA в здравоохранении, или SOX для публичных компаний создает сложные требования к архитектуре безопасности. Обеспечение различных уровней доступа к разным типам данных, шифрование чувствительной информации на всех уровнях, управление персональными данными включая права на забвение и портабельность, соблюдение требований к территориальному размещению данных (data residency), и поддержание детального аудита всех операций требует значительных инвестиций в технологии безопасности и соответствующую экспертизу.
Сравнение с хранилищами данных и современные гибридные подходы
Традиционные различия и эволюция архитектур
Исторически сложившиеся различия между Data Lake и Data Warehouse основаны на фундаментально разных философиях управления данными. Data Warehouse следует принципу «схема при записи» (schema-on-write), требуя четкого определения структуры данных перед их загрузкой, что обеспечивает высокую производительность запросов и гарантированное качество данных, но ограничивает гибкость и увеличивает время подготовки данных. Традиционные хранилища данных оптимизированы для структурированных данных и предсказуемых аналитических запросов, используя денормализованные схемы типа «звезда» или «снежинка», и обеспечивают быстрое выполнение сложных аналитических запросов благодаря предварительной оптимизации и индексированию.
Data Lake использует противоположный подход «схема при чтении» (schema-on-read), позволяя хранить данные в исходном виде и определять структуру только при необходимости обработки или анализа. Этот подход обеспечивает максимальную гибкость для работы с разнообразными типами данных, включая неструктурированные и полуструктурированные данные, но может требовать дополнительных вычислительных ресурсов для обработки данных во время выполнения запросов и создает дополнительные требования к качеству данных и их управлению.
Современное понимание интеграции
Согласно современному пониманию архитектуры данных, Data Lake может включать в себя структурированные данные, что означает, что традиционные хранилища данных (Data Warehouses) могут являться логической частью более обширной экосистемы озера данных. Этот эволюционный подход, известный как «современная архитектура данных» или «unified data platform», позволяет организациям использовать преимущества обеих технологий: высокую производительность и надежность хранилищ данных для критичных операционных отчетов и регулярной бизнес-аналитики, а также гибкость и масштабируемость озер данных для исследовательской аналитики, машинного обучения, и работы с новыми типами данных.
В такой интегрированной архитектуре Data Warehouse становится специализированной зоной внутри Data Lake, оптимизированной для конкретных аналитических сценариев, в то время как общая экосистема данных обеспечивает единообразное управление метаданными, безопасностью, и доступом ко всем типам данных. Это позволяет избежать дублирования данных, упростить управление данными, и обеспечить консистентность аналитических результатов между различными системами.
Использование и практические применения
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
6 июля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Отраслевые применения и сценарии использования
Data Lake находят широкое применение в различных отраслях экономики, трансформируя подходы к анализу данных и принятию решений. В ритейле и электронной коммерции озера данных используются для создания 360-градусного представления о клиентах через интеграцию данных из онлайн и офлайн каналов продаж, мобильных приложений, социальных сетей, программ лояльности, и внешних источников демографической информации. Это позволяет персонализировать предложения в реальном времени, оптимизировать цепочки поставок через анализ данных о продажах и инвентаре, прогнозировать спрос с использованием внешних факторов таких как погода и экономические индикаторы, и выявлять мошеннические транзакции через анализ паттернов поведения.
В финансовой индустрии Data Lake обеспечивают комплексное управление рисками через объединение трансакционных данных, рыночной информации, новостных лент, социальных медиа, и альтернативных источников данных. Банки и страховые компании используют их для real-time обнаружения мошенничества, анализа кредитных рисков с использованием альтернативных источников данных, алгоритмического трейдинга, соблюдения регулятивных требований через автоматизированную отчетность, и создания персонализированных финансовых продуктов на основе анализа поведения клиентов.
Здравоохранение и life sciences представляют особенно интересную область применения благодаря разнообразию типов данных и критической важности их анализа. Data Lake помогают в интеграции электронных медицинских карт, результатов лабораторных исследований, медицинских изображений, геномных данных, данных носимых устройств, и исследовательских данных для разработки персонализированной медицины, ускорения clinical trials через анализ real-world evidence, эпидемиологических исследований, drug discovery с использованием AI/ML, и популяционного анализа здоровья для общественного здравоохранения.
Телекоммуникационные компании используют Data Lake для управления сетевой инфраструктурой через анализ трафика, оптимизации качества обслуживания, предиктивного обслуживания оборудования, анализа поведения клиентов для снижения churn rate, и разработки новых сервисов на основе location-based данных и паттернов использования сети.
Технологические лидеры и инновации
Крупные технологические компании стали пионерами в использовании Data Lake архитектур, создавая новые стандарты и best practices. Netflix использует массивные Data Lake для персонализации контента для более чем 200 миллионов подписчиков, анализируя viewing patterns, search behavior, device usage, content metadata, и external signals для создания highly personalized recommendations. Их архитектура обрабатывает петабайты данных ежедневно, используя real-time и batch processing для continuous optimization пользовательского опыта.
Uber построила свою бизнес-модель на foundation Data Lake архитектуры, интегрируя location данные, traffic patterns, weather information, driver behavior, rider preferences, и economic factors для dynamic pricing, route optimization, demand forecasting, и fraud detection. Их система обрабатывает миллиарды events ежедневно с subsecond latency для критических операций.
Airbnb использует Data Lake для marketplace optimization, интегрируя listing data, user behavior, reviews, local events, seasonal patterns, и economic indicators для price recommendations, search ranking optimization, trust and safety measures, и business intelligence. Их data science teams используют эту платформу для A/B testing, causal inference, и machine learning model development.
Современные тенденции и будущее развитие
Инновационные технологии следующего поколения
Развитие технологий Data Lake продолжается в направлении создания более интеллектуальных, автоматизированных, и самоуправляемых систем. Delta Lake представляет революционную технологию, разработанную компанией Databricks, которая привносит ACID-транзакции, управление версиями данных (time travel), schema evolution, и унифицированную обработку пакетных и потоковых данных в экосистему Data Lake. Delta Lake решает многие традиционные проблемы озер данных, включая проблемы консистентности данных при concurrent writes, сложности в управлении обновлениями и deletes, отсутствие возможности отката изменений (rollback), и challenges в управлении schema evolution. Технология также обеспечивает improved performance через advanced indexing, data skipping, и Z-ordering optimization.
Lakehouse архитектура представляет собой следующую эволюцию в архитектуре данных, объединяя лучшие характеристики Data Lake и Data Warehouse в единой платформе нового поколения. Lakehouse обеспечивает производительность и надежность традиционных хранилищ данных при сохранении гибкости и экономической эффективности озер данных. Эта концепция поддерживает как traditional BI и operational reporting, так и advanced analytics включая machine learning и data science, устраняя необходимость в сложных и дорогостоящих ETL процессах между различными системами. Ключевые технологии, обеспечивающие Lakehouse, включают Apache Iceberg, Apache Hudi, и Delta Lake, которые предоставляют table-level abstractions поверх object storage с поддержкой ACID transactions, time travel, и schema evolution.
Искусственный интеллект и автоматизация
AI-driven Data Management становится критически важным компонентом современных Data Lake платформ, обеспечивая автоматизацию многих традиционно manual процессов. Machine learning алгоритмы используются для автоматического обнаружения схем данных (schema inference), классификации sensitive data для применения соответствующих security policies, детекции аномалий в качестве данных и производительности системы, predictive capacity planning для оптимизации ресурсов, и intelligent data tiering для автоматического перемещения данных между различными storage classes на основе usage patterns.
Automated DataOps практики начинают широко применяться для управления жизненным циклом данных, включая continuous integration и continuous deployment (CI/CD) для data pipelines, автоматическое тестирование качества данных на всех этапах processing pipeline, мониторинг производительности с automatic alerting и remediation, automated backup и disaster recovery процедуры, и intelligent resource optimization на основе workload patterns и business priorities.
Natural Language Processing и Conversational Analytics интегрируются в Data Lake платформы для democratization доступа к данным. Современные системы позволяют business users задавать вопросы на естественном языке, которые автоматически переводятся в SQL запросы или analytical workflows. Это значительно снижает barrier to entry для non-technical users и ускоряет time-to-insight для business stakeholders.
Облачные технологии и serverless архитектуры
Cloud-native решения для Data Lake продолжают трансформировать ландшафт управления данными с появлением новых управляемых сервисов, которые значительно упрощают развертывание и управление озерами данных. AWS Lake Formation автоматизирует настройку озера данных с встроенными возможностями безопасности, управления и каталогизации данных. Azure Synapse Analytics объединяет хранилища данных, аналитику больших данных и интеграцию данных в единой платформе с бесшовной интеграцией в экосистему Azure. Google Cloud Dataflow и BigQuery предоставляют serverless аналитические возможности с автоматическим масштабированием и моделью оплаты за запрос.
Serverless computing революционизирует способы обработки данных в озерах данных, устраняя необходимость управления инфраструктурой и обеспечивая действительно эластичное масштабирование. Serverless функции позволяют запускать обработку данных в ответ на события, такие как поступление новых данных, автоматическое масштабирование до нуля при отсутствии активных рабочих нагрузок, и модель оплаты за выполнение, которая может значительно снизить затраты для прерывистых или непредсказуемых рабочих нагрузок.
Мультиоблачные и гибридные стратегии становятся стандартом для корпоративных организаций, стремящихся избежать зависимости от поставщика и оптимизировать затраты через выбор лучших сервисов от различных облачных провайдеров. Современные архитектуры озер данных поддерживают переносимость данных между различными облачными платформами, унифицированные интерфейсы управления для мультиоблачных сред, и бесшовную репликацию данных для аварийного восстановления и соблюдения требований соответствия.
Emerging технологии и будущие направления
Quantum computing начинает влиять на подходы к обработке больших данных, особенно в областях optimization, cryptography, и machine learning. Хотя практические quantum computers пока ограничены, quantum-inspired algorithms уже используются для решения complex optimization problems в Data Lake environments.
Edge computing и интеграция IoT создают новые требования для архитектур озер данных, включая поддержку каналов передачи данных от периферии к облаку, обработку данных в реальном времени на периферийных устройствах, интеллектуальную фильтрацию данных для снижения нагрузки на каналы связи, и бесшовную интеграцию между периферийными и облачными аналитическими платформами.
Blockchain технологии исследуются для обеспечения неизменяемых журналов аудита, децентрализованного управления данными и безопасного обмена данными между организациями. Технологии распределенного реестра могут обеспечить новые уровни прозрачности и доверия при отслеживании происхождения и истории данных.
Federated learning открывает возможности для совместного машинного обучения без централизованного обмена данными, что особенно важно для приложений, чувствительных к конфиденциальности в здравоохранении, финансах и государственном секторе. Эта технология позволяет организациям извлекать ценные выводы из распределенных наборов данных без фактического перемещения информации.
Будущее озер данных также связано с развитием автономных систем управления данными, которые смогут самостоятельно оптимизировать производительность, управлять политиками безопасности, предсказывать и предотвращать проблемы, и автоматически адаптироваться к изменяющимся бизнес-требованиям. Интеграция с технологиями расширенной аналитики и объяснимого искусственного интеллекта поможет демократизировать возможности продвинутой аналитики и обеспечить прозрачность в принятии решений на основе ИИ.
Устойчивое развитие и экологичные вычисления становятся все более важными соображениями для развертывания озер данных, с акцентом на энергоэффективное оборудование, алгоритмы оптимизации для снижения вычислительных затрат, интеллектуальное управление жизненным циклом данных для минимизации объема хранилищ, и планирование рабочих нагрузок с учетом доступности возобновляемых источников энергии.
Ожидается, что озера данных будут становиться все более интеллектуальными, самоуправляемыми и способными автоматически адаптироваться к развивающимся потребностям бизнеса, регулятивным требованиям и технологическим инновациям, при этом поддерживая высокие уровни безопасности, производительности и экономической эффективности.
Дополнительные источники и литература
- James Dixon (2010) — «Pentaho, Hadoop, and Data Lakes» — оригинальная статья, в которой был впервые введен термин Data Lake — https://jamesdixon.wordpress.com/2010/10/14/pentaho-hadoop-and-data-lakes/
- Apache Software Foundation — «Apache Spark Documentation» — официальная документация по Apache Spark, ключевой технологии обработки данных в Data Lake — https://spark.apache.org/docs/latest/
- Microsoft Azure — «Modern Data Warehouse Architecture» — руководство по современным архитектурам данных, включая интеграцию Data Lake и Data Warehouse — https://docs.microsoft.com/en-us/azure/architecture/data-guide/