
Для популяризации нашего нового курса для дата-инженеров по Trino мы проводим очередной бесплатный митап для аналитиков, архитекторов, инженеров данных, разработчиков, DataOps- инженеров и тех, кто интересуется современными технологиями обработки данных. Поскольку Trino является движком для онлайн-обработки больших объемов данных с помощью распределенных SQL-запросов, ему нужна повышенная отказоустойчивость для стабильной работы...

Что общего у StarRocks с Trino, чем они отличаются, когда и что выбирать для практического использования: сравниваем движки для быстрой аналитики больших данных из Data Lake. Чем похожи StarRocks и Trino Вчера мы разбирали, что такое StarRocks, как устроена и где пригодится эта высокопроизводительная аналитическая база данных с открытым исходным...

Вместо Trino и ClickHouse: что такое StarRocks и как оно устроено, архитектура и принципы работы, сценарии использования и место в корпоративной архитектуре данных. Архитектура и принципы работы StarRocks Хотя ClickHouse сегодня считается одним из наиболее популярных колоночных хранилищ для аналитики больших объемов данных в реальном времени, это не единственный представитель...

Что такое Apache Wayang, чем он похож на Beam и в чем разница с Trino: архитектура и принципы работы еще одного распределенного фреймворка интеграции данных. Что такое Apache Wayang и чем это отличается от Trino Trino – это мощный, но далеко не единственный инструмент распределенного выполнения аналитических запросов, способный обрабатывать...

В поддержку нашего нового курса для дата-инженеров Школа Больших Данных проводит очередной бесплатный митап для аналитиков, архитекторов, инженеров данных, разработчиков, DataOps- инженеров и тех, кто интересуется современными технологиями обработки данных. Trino – это распределенный SQL-движок с массово-параллельной архитектурой и открытым исходным кодом. Он предназначен для работы с большими объемами данных в...
Пишем собственный плагин Trino для работы с пользовательским типом данных: практический пример создания и регистрации своих классов и pom-файла. Пример реализации своего плагина Trino О том, что гибкость Trino обеспечивается благодаря его плагинной архитектуре, я недавно писала здесь. Сегодня рассмотрим пример создания своего плагина, который реализует возможность работы с пользовательским...
Почему Trino такой гибкий: плагинная архитектура SQL-движка, зависимости SPI-интерфейса и последовательность создания пользовательского плагина. Плагинная архитектура Trino и как она работает Благодаря настраиваемым коннекторам Trino может подключаться к любым источникам, от реляционных баз данных до NoSQL-хранилищ. При этом коннекторы – это частный случай плагина. С точки зрения проектирования ПО, Trino...
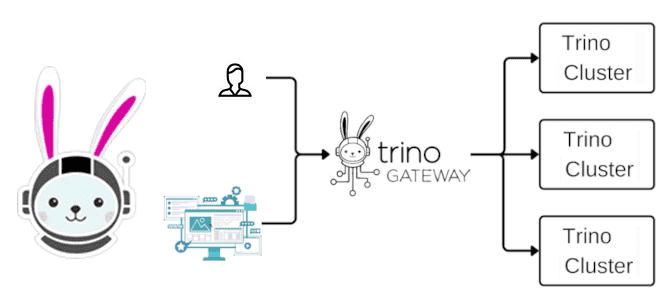
Что такое Trino Gateway, зачем он нужен и как работает: для чего делить один большой кластер Trino на несколько маленьких и как к ним обращаться без изменений на стороне клиентов. Проблемы бесконечного масштабирования кластера Благодаря горизонтальному масштабированию, о котором мы говорили вчера, кластер Trino можно расширять, добавляя новые рабочие узлы....
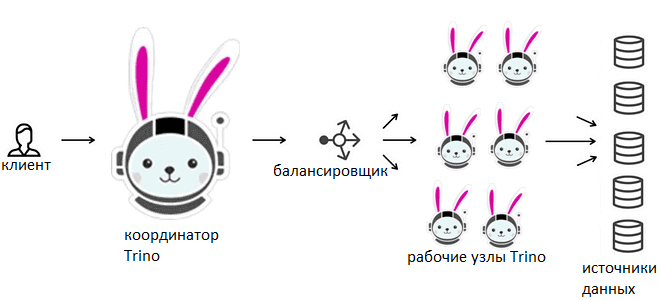
Как ускорить работу Trino при росте нагрузки и сэкономить на кластере при ее сокращении: автомасштабирование рабочих узлов и операций записи, а также настройка групп ресурсов. Масштабирование кластера Классическим способом справиться с растущими вычислительными нагрузками в гомогенной распределенной системе является горизонтальное масштабирование кластера. Это сводится к добавлению новых узлов, которые отвечают...

Мы уже писали о том, как Trino работает с удаленными объектными хранилищами и файловыми системами. Сегодня поговорим о том, какие изменения выпущены в февральском релизе 2025 года, почему в Trino удалена поддержка доступа к Azure Storage, Google Cloud Storage, S3 и S3-совместимым файловым системам через Hive и что использовать вместо...
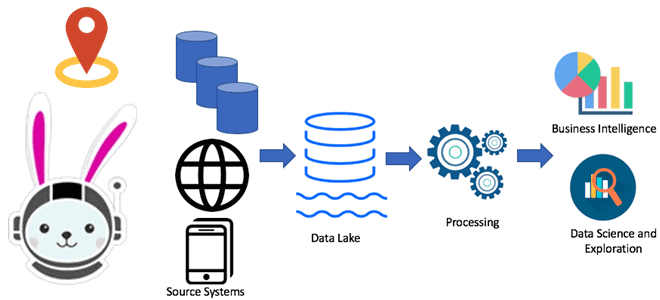
Почему Trino не заменит Flink, Spark и Airflow: границы применимости MPP-движка распределенного выполнения SQL-запросов к реляционным и нереляционным источникам данных. Почему Trino не заменит Flink, Spark и Airflow Хотя Trino отлично подходит для быстрой ad-hoc аналитики, позволяя SQL-запросами в реальном времени обращаться к различным базам данных, включая нереляционные хранилища и...

Как устроен механизм отказоустойчивого выполнения в Trino, чем политика повтора QUERY отличается от TASK, зачем настраивать диспетчер обмена на внешнее S3-совместимое хранилище и задавать коэффициент задержки перед повторными попытками выполнить SQL-запрос. 2 политики отказоустойчивого выполнения в Trino Будучи движком online-обработки больших объемов данных с помощью распределенных SQL-запросов, Trino должен иметь...
Для продвижения нашего нового курса для дата-инженеров Школа Больших Данных проводит очередной бесплатный митап для аналитиков, архитекторов, инженеров данных, разработчиков, DataOps- инженеров и тех, кто интересуется современными технологиями обработки данных. Trino – это распределенный SQL-движок с массово-параллельной архитектурой и открытым исходным кодом, предназначенный для работы с большими объемами данных в разных...
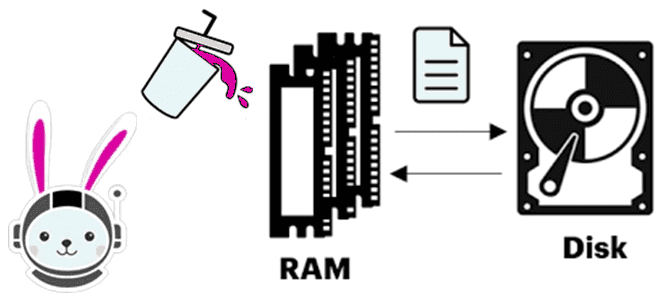
Что происходит, когда Trino не хватает памяти для выполнения SQL-запроса, как выполняется сброс промежуточных результатов на диск и почему механизм spill-to-disk не избавляет от OOM-ошибок. Spill-to-disk: сброс промежуточных результатов на диск в Trino Продолжая вчерашний разговор про нехватку памяти (OOM, Out Of Memory) в Trino, сегодня рассмотрим, как работает spill-механизм...

Почему в кластере Trino может возникнуть OOM-ошибка и как справиться с нехваткой памяти, оптимизировав SQL-запросы и настроив конфигурации: примеры и рекомендации. Причины OOM-ошибок в кластере Trino и как их устранить Для Trino, как и для многих JVM-приложений, характерны проблемы с управлением памятью, включая возникновение OOM-ошибок (Out Of Memory). Это связано...
Где и как задавать настройки безопасного доступа клиента к кластеру Trino, каким образом обеспечить безопасность внутри кластера и защитить доступ к внешним источникам данных: примеры конфигураций. Как настроить безопасную работу кластера Trino По умолчанию в Trino не включены функции обеспечения безопасности. Однако, это можно настроить для различных частей архитектуры фреймворка:...
Зачем Trino использует внешние таблицы при запросах к данным в объектных хранилищам и удаленных файловых системах, чем они отличаются от внутренних и как повысить производительность таких SQL-запросов с помощью кэширования. Доступ из Trino к данным в объектных хранилищах Помимо реляционных и нереляционных баз данных, Trino позволяет делать распределенные запросы и...

Что общего между Trino и dbt, чем они отличаются и в каких случаях выбирать тот или иной инструмент для инженерии и анализа данных. Краткий ликбез для начинающего дата-инженера и аналитика. Сходства и отличия Trino и dbt Trino и dbt (Data Build Tool) — это два популярных инструмента с открытым исходным...
Зачем Trino статистика таблиц, как MPP-движок создает план выполнения SQL-запросов к разным источникам данных, применяя CBO-оптимизацию, а также полную или частичную передачу обработки предикатов в базовое хранилище. Внутренние оптимизации Trino В отличие от MapReduce с материализацией промежуточных результатов на диске, в массово-параллельной архитектуре Trino промежуточные результаты передаются между рабочими узлами...
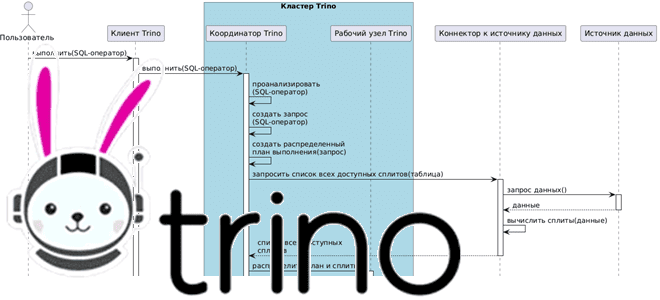
Как взаимодействуют рабочие узлы Trino между собой и с координатором кластера, а также с клиентскими приложениями и драйверами при выполнении SQL-запросов к данным из внешних источников без их фактического копирования. Последовательность выполнения запросов в кластере Trino Продолжая разбираться с Trino, сегодня рассмотрим, как этот аналитический движок с массово-параллельной архитектурой (MPP,...