 668
668 
Появившись более 10 лет назад, Apache Hive до сих пор является самым популярным инструментом стека SQL-on-Hadoop и активно используется для аналитики больших данных. Однако, технологии Big Data постоянно развиваются: Spark все чаще заменяет Hadoop MapReduce, а вместо HDFS все чаще используются объектные облачные хранилища: AWS S3, Delta Lake, Apache Ozone и пр. Сегодня рассмотрим, ключевые возможности Apache Hive, актуальные для современных дата-инженеров и какие альтернативы способны заменить это NoSQL-хранилище.
Основные принципы работы и 4 главных преимущества Apache Hive
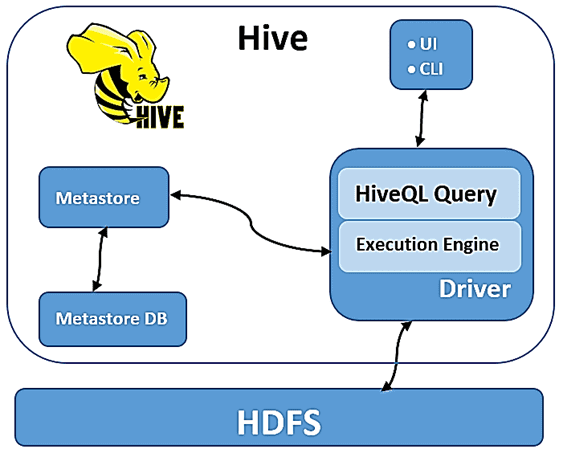
Архитектура Apache Hive состоит из 2-х основных сервисов:
- Механизм запросов, который отвечает за выполнение операторов SQL в диалекте HiveQL;
- Хранилище метаданных (Metastore), отвечающее за виртуализацию коллекций данных в HDFS в виде таблиц.
Напомним, в кластере Apache Hadoop огромные наборы данных хранятся в распределенной файловой системе HDFS. Обработка данных выполняется параллельно с использованием вычислительной MapReduce. За распределение задач отвечает YARN, а основным интерфейсом является язык программирования Java или Scala. Принцип работы Apache Hive как инструмента SQL-on-Hadoop достаточно прост и изящен: при сохранении новых данных в HDFS они регистрируются в Metastore, вызывая API хранилища метаданных из кода приложения или инструмента оркестровки. На этом декларативном этапе набор объектов в хранилище сопоставляется с таблицей Hive. Регистрация также включает определение схемы таблицы, содержащейся в файле, с некоторыми метаданными, описывающими столбцы.
По мере развития технологий Big Data вместо YARN все чаще используется Kubernetes, а HDFS вытесняют объектные хранилища типа AWS S3. Быстрый Apache Spark практически полностью вытеснил MapReduce. А производительность механизма запросов Hive уступает Presto. Однако, историческое развертывание озер данных на Hadoop HDFS во многих компаниях до сих пор активно использует Hive Metastore как часть Big Data инфраструктуры. Нет смысла отказываться от работающих преимуществ, которые предоставляет это NoSQL-хранилище:
- виртуализация, которая позволяет дата-аналитикам работать с данными, хранящимися в HDFS с помощью хорошо знакомого инструментария SQL-запросов;
- обнаруживаемость — Hive Metastore естественным образом становится каталогом всех коллекций в хранилище объектов, когда открытие новых данных сопровождается их обновлением, позволяя обнаруживать наборы данных, доступные для запросов, а также сопровождающие их метаданные (информация о частоте обновления, владельце и пр.);
- эволюция схемы данных, которая обеспечивает возможность динамического развития данных, записывая изменения атрибутов и столбцов в хранилище метаданных Hive;
- представление – поскольку хранилище метаданных Hive сопоставляет таблицу с базовым объектом, можно представлять разделы в соответствии с первичным ключом, поддерживаемым хранилищем объектов. Степень детализации разделов может устанавливаться пользователем, и, если разделы и их количество сбалансированы, такое сопоставление повышает производительность запросов. Это часто называют «сокращением разделов» (partition pruning), которое позволяет механизму запросов определять файлы данных, которые можно пропустить.
Альтернативы и конкуренты
Основными конкурентами Hive Metastore, которые будут также предоставлять вышеотмеченные преимущества, считаются форматы открытых таблиц:
- Iceberg – открытый формат таблиц для огромных наборов аналитических данных, который добавляет высокопроизводительные SQL-подобные таблицы в вычислительные механизмы (Spark, Trino, Presto, Flink и Hive). Подробнее про Apache Iceberg читайте в нашей новой статье.
- Hudi – многофункциональная платформа для создания озер потоковых данных с инкрементными конвейерами данных на уровне самоуправляемой СУБД с оптимизацией регулярной пакетной обработки. Hudi не предназначен для OLTP-сценариев и, несмотря на поддержку транзакций, не может заменить аналитическую In-Memory базу данных, но поддерживает прием данных в режиме near real-time с помощью эффективного пакетирования.
- Delta Lake – уровень хранилища с открытым исходным кодом, обеспечивающий надежность озера данных с поддержкой ACID-транзакций, масштабируемой пакетной и потоковой обработки Big Data и метаданных. Delta Lake работает на базе существующего озера данных (на Apache Hadoop HDFS, Amazon S3 или Azure Data Lake Storage) и полностью совместимо со всеми API Apache Spark. Подробнее о Delta Lake мы писали здесь, здесь и здесь.
Изменчивость данных поддерживают Hudi и Delta Lake, Iceberg обеспечивает эффективность доступа к большим таблицам, а эволюцию схемы реализует Delta Lake. Таким образом, ни один из этих инструментов не предоставляет все преимущества Hive Metastore одновременно, а потому пока не может его заменить. При использовании приложений, поддерживающих эти форматы, данные могут обрабатываться приложением как таблица без каких-либо промежуточных звеньев. Но не все приложения в экосистеме Big Data отдельно взятой компании поддерживают эти форматы, снижает их производительность. Поэтому Hive Metastore можно рассматривать как общий интерфейс, поддерживаемый всеми приложениями, использующих форматы открытых таблиц. Поэтому можно по-прежнему полагаться на Apache Hive для виртуализации и других сценариев использования, не охватываемых указанными открытыми форматами.
Если в качестве конкурента Hive Metastore рассматривать каталоги данных, такие как Allation, которые позволяют сопоставить хранилище объектов с используемыми базами данных, то некоторые из них можно считать кандидатами на замену функции каталогизации. Это обеспечивается благодаря оперативному мониторингу качества данных и конвейеров их обработки. Если инструмент мониторинга реализуется на протяжении всего жизненного цикла данных, он может динамически обновлять каталог данных, заменяя Hive Metastore в этом отношении.
Таким образом, пока ни одна из возможных альтернатив полностью не покрывает все функции Hive Metastore, что означает необходимость владения этим инструментом для современного дата-инженера, аналитика больших данных и разработчика распределенных приложений Big Data. Освоить все тонкости работы с Apache Hive для эффективной аналитики больших данных вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://lakefs.io/hive-metastore-why-its-still-here-and-what-can-replace-it/
- https://hudi.apache.org/
- https://iceberg.apache.org/

