 1168
1168 
Содержание
Озеро данных (Data Lake) на Apache Hadoop HDFS в мире Big Data стало фактически стандартом де-факто для хранения полуструктурированной и неструктурированной информации с целью последующего использования в задачах Data Science. Однако, недостатком этой архитектуры является низкая скорость вычислительных операций в HDFS: классический Hadoop MapReduce работает медленнее, чем аналоги на Apache Spark из-за обращения к жесткому диску, а не оперативной памяти. Поэтому с 2019 года стала активно развиваться концепция Delta Lake как хранилища данных нового уровня, сочетающая в себе преимущества Apache Spark для потоковой обработки с возможностями традиционного пакетного подхода. Читайте далее, что такое Delta Lake, зачем и кому это нужно, а также при чем здесь Apache Spark.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
6 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Как появилось Delta Lake: уход в облака и проблемы Hadoop-as-a-Service
Начнем с определения: Delta Lake — это уровень хранилища с открытым исходным кодом, обеспечивающий надежность озера данных. Delta Lake поддерживает ACID-транзакции и масштабируемую обработку метаданных, объединяя потоковые и пакетные операции с большими данными. Примечательно, что Delta Lake работает на базе существующего озера данных (на Apache Hadoop HDFS, Amazon S3 или Azure Data Lake Storage) и полностью совместимо со всеми API Apache Spark [1].
Вышеотмеченная проблема скорости вычислительных операций на HDFS – не единственная причина появления Delta Lake. Ведь совместить пакетную обработку с потоковой можно в рамках Лямбда-архитектуры, о чем мы писали здесь. Дополнительным драйвером развития концепции Delta Lake послужила цифровизация, гибридные облачные DWH и сервисный подход к использованию технологий Big Data. В частности, популяризация облачного развертывания Apache Hadoop (Hadoop-as-a-Service) помимо удобства SaaS/PaaS-подхода принесла следующие недостатки [2]:
- основные сервисы Hadoop, такие как YARN и HDFS, изначально не были разработаны для облачных сред, а предназначались для локального использования, что отражается на их архитектурных особенностях и принципах работы;
- высокие накладные расходы на DevOps и управление Hadoop;
- сложности с масштабированием и надежностью в облачных Data Lake на Apache
Эти проблемы усугубляются тем, что с ускорением циклов разработки согласно Agile-подходу и перемещением рабочих нагрузок в облако, ожидания клиентов от базовой платформы данных существенно изменились. Теперь пользователи хотя получить следующие преимущества [2]:
- удобные, полностью управляемые по запросу Big Data кластеры в виде PaaS- или SaaS-услуг;
- гибкие модели ценообразования с оплатой по факту потребления ресурсов;
- интеллектуальное автоматическое масштабирование для управления совокупной стоимостью владения и высокое качество эксплуатационной надежности (SRE), в частности, показатели SLA$
- надежность и высокое качество данных в облачных Data Lake для принятия обоснованных бизнес-решений на основе этой информации (data-driven управление);
- высокая производительность операций с очень большими наборами данных;
- универсальность используемых сервисов и возможность смены облачного провайдера в любое время;
- простой веб-GUI для настройки, конфигурирования и эксплуатации облачных сервисов, понятный большинству пользователей.
Сегодня все это и многое другое реализуется на облачном масштабируемом хранилище данных Delta Lake, в основе которого лежит фреймворк Apache Spark. Именно этим обусловлены главные преимущества хранилища Delta Lake, о которых мы расскажем далее.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
12 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
10 ключевых достоинств Дельта-озера
Помимо плюсов облачной реализации и высокой скорости за счет Apache Spark, Delta Lake характеризуется следующими отличиями [3]:
- поддержка ACID-транзакций – обычно озера данных имеют несколько конвейеров их обработки (data pipelines), которые одновременно читают и записывают информацию. Поэтому инженерам данных приходится обеспечивать целостность данных из-за отсутствия транзакций. Delta Lake переносит ACID-транзакции в озера данных, обеспечивая сериализуемость и самый высокий уровень изоляции.
- масштабируемая обработка метаданных – поскольку в Big Data даже данные о данных (метаданные) могут быть очень большими, Delta Lake обрабатывает их, используя распределенную вычислительную мощность Apache Это позволяет легко обрабатывать таблицы петабайтного масштаба с миллиардами разделов и файлов.
- управление версиями данных – Delta Lake предоставляет моментальные снимки данных, позволяя разработчикам получать доступ и возвращаться к более ранним версиям для аудита, отката или воспроизведения экспериментов, что мы рассматриваем здесь.
- открытый формат – все данные в Delta Lake хранятся в столбцовом формате Apache Parquet, что позволяет использовать эффективно сжимать и кодировать данные.
- унифицированный пакетный и потоковый источник и приемник в одном – таблица в Delta Lake одновременно является пакетной таблицей, а также источником и приемником потоковой передачи. Потоковая загрузка данных, пакетная обработка исторической информации и интерактивные запросы работают сразу после установки.
- поддержка схем данных, что позволяет указать структуру информации и обеспечить ее соблюдение, гарантируя правильность типов данных и наличие необходимых столбцов. Это предупреждает повреждение информации из-за некорректных данных.
- эволюция схемы – Delta Lake позволяет вносить изменения в схему таблицы, которые могут применяться автоматически, без необходимости использования громоздкого DDL (Data Definition Language — семейство языков для описания структуры СУБД).
- аудит истории изменений с помощью журнала транзакций, куда записываются сведения о каждом изменении данных.
- обновления и удаления наборов данных (Update/Delete) с помощью API Scala/Java, что упрощает сбор измененных данных, а также соблюдение требований GDPR и CCPA (California Consumer Privacy Act, Калифорнийский закон о защите прав потребителей о неприкосновенности частной жизни и защиты жителей Калифорнии, США).
- полная совместимость с Apache Spark API, благодаря чему разработчики могут запускать на Delta Lake существующие конвейеры обработки данных с минимальными изменениями.
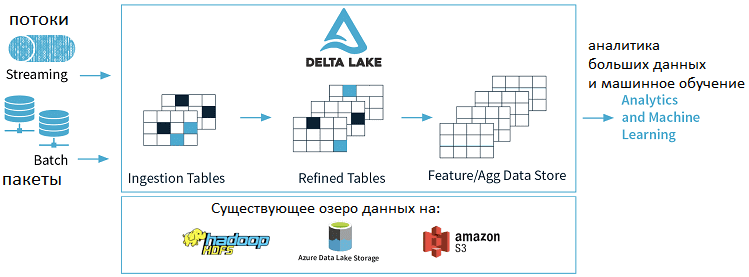
Таким образом, неудивительно, что архитектура Delta Lake активно используется множеством Big Data компаний, среди которых COMCAST, Alibaba Group, Conde Nast, Tableau, Ebay и другие предприятия по всему миру для задач аналитики больших данных с помощью методов Data Science и Machine Learning. Хотя Delta Lake является open-source технологией, в корпоративном мире основным флагманом ее продвижения выступает международная компания Databricks, организованная в 2013 году основателями Apache Spark. Сегодня большинство коммерческих реализаций Delta Lake, готовых к корпоративному использованию, базируются именно на продукте Databricks [4]. В чем уникальность этого решения по сравнению с типовым Data Lake на Apache Hadoop, мы поговорим завтра.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
6 апреля, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Больше подробностей по администрированию и эксплуатации Apache Spark и Apache Hadoop для аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Анализ данных с Apache Spark
- Безопасность озера данных Hadoop
- Hadoop для инженеров данных
- Архитектура Данных
Источники
- https://docs.microsoft.com/ru-ru/azure/databricks/delta/delta-intro
- https://blogs.informatica.com/2019/10/04/how-to-go-hadoop-less-with-informatica-data-engineering-and-databricks/
- https://delta.io/
- https://databricks.com/product/delta-lake-on-databricks

