 999
999 
Apache Flink – это распределенная отказоустойчивая платформа обработки информации с открытым исходным кодом, используемая в высоконагруженных Big Data приложениях для анализа данных, хранящихся в кластерах Hadoop. Разработанный в 2010 году в Техническом университете Берлина в качестве альтернативы Hadoop MapReduce для распределенных вычислений больших наборов данных, Flink использует подход ориентированного графа, устраняя необходимость в отображении и сокращения [1].
Подобно Apache Spark, Flink имеет готовые коннекторы с Apache Kafka, Amazon Kinesis, HDFS, Cassandra, Google Cloud Platform и др., а также интегрируется со всеми основными системами управления кластерами: Hadoop YARN, Apache Mesos и Kubernetes. Кроме того, Флинк может использоваться в качестве основы автономного кластера [1].
Как устроен Apache Flink: архитектура и принцип работы
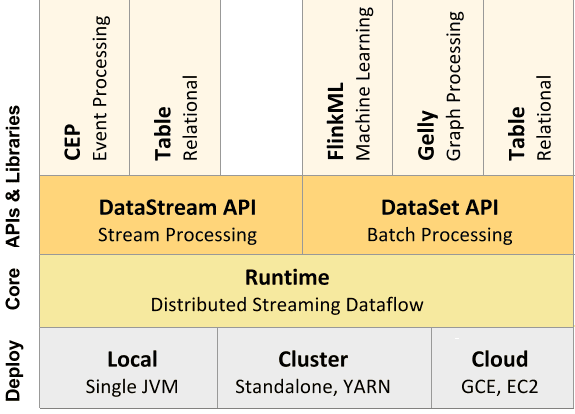
Входные данные каждого потока Флинк берутся с одного или нескольких источников, например, из очереди сообщений Apache Kafka, СУБД HBase или файловой системы Hadoop HDFS, отправляясь в один или несколько приемников (очередь сообщений, файловую систему или базу данных). В потоке может быть выполнено произвольное число преобразований. Эти потоки могут быть организованы как ориентированный ациклический граф, позволяющий приложению распределять и объединять потоки данных. Помимо потоковой обработки Big Data в рамках DataStream API, Flink также позволяет работать с пакетами данных с помощью мощного DataSet API.
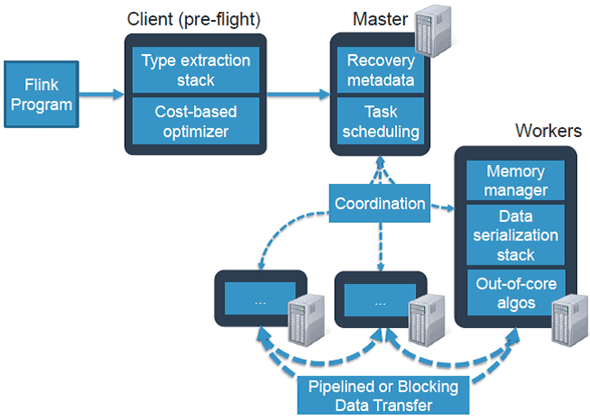
При развертывании приложения Flink автоматически идентифицирует требуемые ресурсы на основе настроенного параллелизма приложения и запрашивает их из системы управления кластером. В случае сбоя Flink заменяет контейнер, запрашивая новые ресурсы. Отправка и управление приложением происходит через REST. Это облегчает интеграцию Flink в различных средах [1].
Подобно другому популярному фреймворку потоковой обработки Big Data, Apache Spark, Флинк содержит оптимизатор и библиотеки для машинного обучения, аналитических графиков и реляционной обработки данных.
Преимущества и недостатки Флинк
Ключевыми достоинствами Apache Flink можно назвать следующие [1]:
- высокая производительность — приложения Флинк могут распараллеливаться в тысячи задач, которые распределяются и выполняются в кластере одновременно, используя практически неограниченное количество процессоров, основной памяти, дискового и сетевого ввода-вывода. Кроме того, Flink легко поддерживает очень большое состояние приложения. Его асинхронный и инкрементный контрольный алгоритм обеспечивает минимальное влияние на задержки обработки, гарантируя точную согласованность состояния за один раз.
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
12 января, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
- низкое время задержки, достигаемое, в т.ч. за счет собственной подсистемы управления памятью и ее эффективного использования – приложения Флинк оптимизированы для локального доступа. Состояние задачи (stateful) сохраняется в локально памяти или, если его размер превышает доступную память, на жестком диске.
- веб-интерфейс, который отображает граф обработки данных и позволяет посмотреть, сколько данных каждой подзадачи обработал конкретный worker. Благодаря этому можно определить, какой участок кода работает с задержкой, т.е. какой процент данных не успел обработаться и где [2].
- отказоустойчивость – Flink гарантирует согласованность состояния приложений в случае сбоев, периодически и асинхронно проверяя локальное состояние на необходимость перемещения в долговечное хранилище;
- гибкая работа с потоковыми данными – поддержка временных и неисправных событий, непрерывная потоковая модель передачи с обратным воздействием, реализация концепции «окон» для избирательной обработки данных в определенном временном промежутке (подробно механизм временных окон мы описывали здесь на примере Apache Kafka Streams);
- 2 режима работы с данными в 1 среде – потоковая передача и пакетная обработка;
- специализированная поддержка итерационных вычислений (машинное обучение, анализ графов).
При всех вышеперечисленных достоинствах, для Флинк характерны следующие недостатки:
- даже при наличии отказоустойчивого хранилища состояний для приложений (stateful), которое поддерживает механизм контрольных точек (checkpoints), из него нельзя восстановиться при изменении кода [2];
- многие библиотеки Flink до сих пор находятся в бета-режиме [1], что затрудняет его использование в крупных Big Data проектах корпоративного сектора, где требуется высокая надежность [3].
Сравнению Flink с Apache Spark, другим популярным фреймворком потоковой обработки больших данных мы посвятили отдельную статью.
Источники
- https://ru.bmstu.wiki/Apache_Flink
- https://habr.com/ru/company/ivi/blog/347408/
- https://medium.com/@chandanbaranwal/spark-streaming-vs-flink-vs-storm-vs-kafka-streams-vs-samza-choose-your-stream-processing-91ea3f04675b