 2086
2086 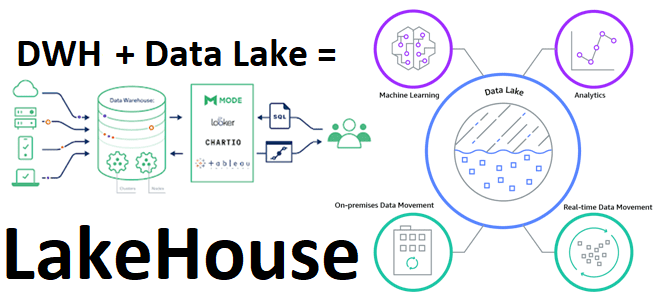
В рамках обучения дата-инженеров и архитекторов корпоративных платформ и приложений аналитики больших данных, сегодня рассмотрим, что такое LakeHouse. Как эта новая гибридная архитектура управления данными объединяет 2 разнонаправленные парадигмы хранения информации, а также чего от нее ожидают бизнес-пользователи, дата-инженеры, аналитики и ML- специалисты.
Историческая справка: от DWH к Data Lake
Корпоративные хранилища данных (DWH, Data WareHouse) имеют долгую историю использования в приложениях поддержки принятия решений и бизнес-аналитики. С момента своего появления в конце 1980-х годов технология хранилищ данных продолжала развиваться. Архитектура массивно-параллельной обработки данных, на которой основана MPP-СУБД Greenplum, привела к созданию систем, способных обрабатывать большие объемы данных. Хотя хранилища отлично подходили для структурированных данных, современному бизнесу приходится иметь дело с неструктурированными и полуструктурированными данными, которые отличаются большим разнообразием, скоростью и объемом. Традиционное DWH не очень подходит для таких сценариев использования, в т.ч. с экономической точки зрения.
Для хранения хранения данных из множества различных источников для разных аналитических продуктов и рабочих нагрузок в начале 2010-хх гг. дата-архитекторы начали создавать озера данных. Озеро данных (Data Lake) – это хранилище необработанных данных в различных форматах. Хотя озера данных отлично подходят для хранения, им не хватает некоторых важных функций, таких как поддержка транзакций и обеспечение качества данных. А отсутствие согласованности и изоляции делает практически невозможным смешивание операций добавления и чтения, а также пакетных и потоковых заданий. Поэтому потребность в гибкой, высокопроизводительной системе не уменьшилась: бизнесу требовались хранилища для различных приложений, включая аналитику через SQL-запросы, мониторинг в реальном времени, машинное обучение и другие возможности Data Science. В частности, многие приложения искусственного интеллекта связаны с улучшением моделей обработки неструктурированных данных (текст, изображения, видео, аудио). Но именно эти типы данных не имеют четкой структуры, на которую ориентировано традиционное DWH. Чтобы совместить возможности озер и хранилищ данных со специфическими СУБД, оптимизированными для потоковой обработки, аналитики временных рядов, графов и пр., компании разворачивали их все в своей локальной или облачной инфраструктуре. Но подобный зоопарк систем усложняет владение данными и приводит к задержкам их обработки, т.к. дата-инженерам нужно строить и поддерживать ETL-конвейеры для перемещения или копирования данных между различными платформами.
Поэтому в начале 2020 года появилась новая модель гибридной архитектуры данных, которая стремится объединить достоинства классических DWH с гибкостью Data Lake. Эта архитектура управления данными получила название LakeHouse и отлично коррелирует с идеями цифровой трансформации. Что она из себя представляет и какие возможности предоставляет, мы рассмотрим далее.
Что такое LakeHouse
Lakehouse — это новая открытая архитектура, сочетающая в себе лучшие элементы озер и хранилищ данных. Lakehouses стали возможными благодаря новому дизайну системы: реализации структур данных и функций управления данными, аналогичных тем, которые используются в хранилище данных, непосредственно поверх недорогого облачного хранилища в открытых форматах. LakeHouse имеет следующие основные особенности:
- поддержка транзакций — конвейеры данных способны одновременно считывать и записывать данные. Поддержка ACID-транзакций обеспечивает согласованность, поскольку несколько сторон одновременно считывают или записывают данные, обычно используя популярный инструментарий SQL-запросов.
- принудительное применение и управление схемой, включая поддержку классических моделей DWH, такие как схемы звезды и снежинки, с обеспечением целостности и полноты данных, а также надежные механизмы управления и аудита.
- совместимость с BI — Lakehouse позволяет использовать инструменты бизнес-аналитики непосредственно в исходных данных, повышая их актуальность, а также уменьшая задержку и затраты, связанные с необходимостью выполнения операций над двумя копиями данных как в озере данных, так и в хранилище.
- изоляция хранения от вычислений по разным кластерам, что облегчает масштабирование для большего количества одновременных пользователей и объемов данных.
- открытость стандартизованных форматов хранения данных, таких как Apache Parquet или Iceberg, которые предоставляют API, поэтому различные инструменты и механизмы, включая ML-системы и библиотеки Python/R, могут эффективно обращаться к данным напрямую.
- многообразие различных типов данных, от неструктурированных до структурированных. Lakehouse можно использовать для хранения, уточнения, анализа и доступа к разным типам данных, включая изображения, видео, аудио, JSON-структуры и текст.
- поддержка разнообразных рабочих нагрузок, от алгоритмов машинного обучения до SQL-запросов и распределенных вычислений – хотя все эти рабочие нагрузки требуют разных технологий реализации, все они полагаются на один и тот же репозиторий данных.
- сквозная потоковая передача событий в режиме реального времени, что устраняет необходимость в отдельных streaming-системах.
Помимо вышеотмеченных возможностей Lakehouse, для корпоративных систем также требуются средства обеспечения безопасности и контроля доступа, включая аудит, хранение, мониторинг происхождения и поддержка наблюдаемости, в т.ч. каталоги данных и показатели их использования. В отличие от классических DWH, которые ориентированы на BI-инструменты, парадигму LakeHouse можно назвать AI-центричной. Потенциально Lakehouse дает более гибкие и широкие возможности, но из-за этого является менее управляемым по сравнению с Data Warehouse.
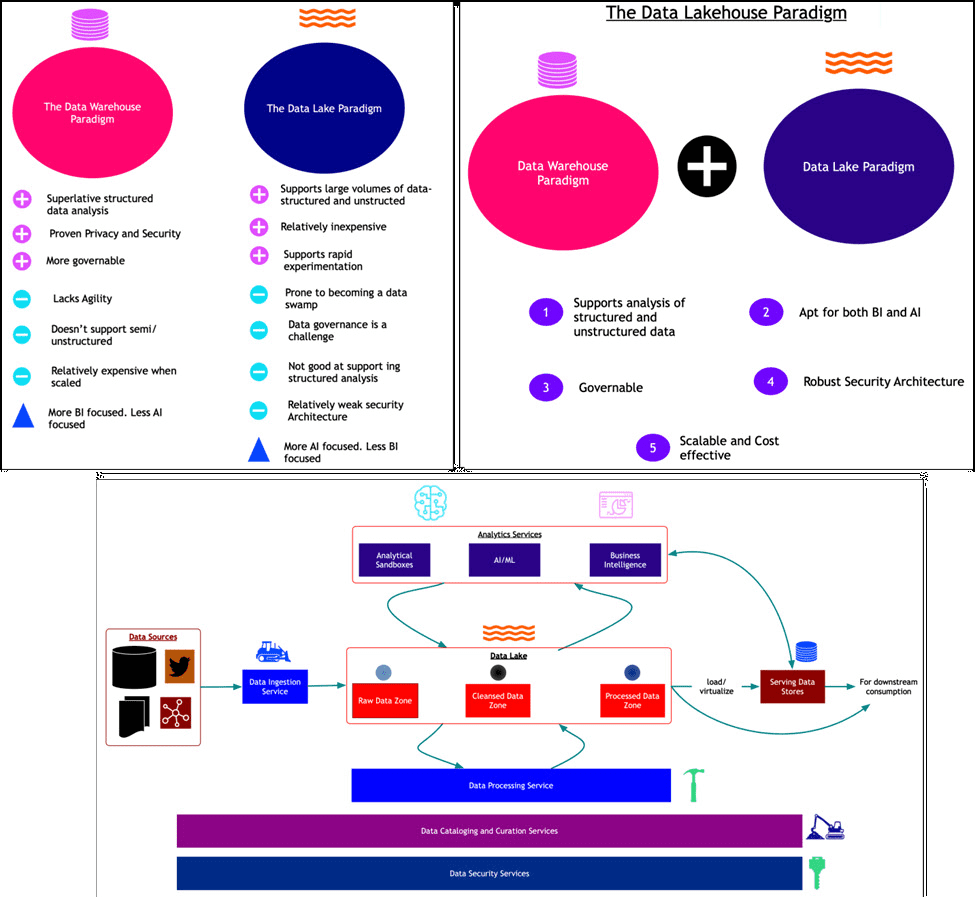
Можно сказать, что переход к гибридной архитектуре позволит унифицировать источники данных, включая хранилища и озера, в масштабе всей организации, обеспечивая получение непротиворечивой отчетности и аналитики для разных бизнес-вертикалей. Именно этого ожидает от технологий Big Data цифровизация современного бизнеса. Lakehouse расширяет традиционную аналитику данных, совмещая гибкость озер с четкой структурой хранилищ. Структурированные данные можно обрабатывать с помощью SQL-запросов, которыми владеет каждый аналитик, от продуктового до бизнес-аналитика. Однако, гибридная архитектура LakeHouse пока находится на уровне концепции и формирования инструментария. Хотя, некоторые платформы уже реализуют ее в практическом виде, например, Tableflow от Confluent, что мы разбираем здесь. Впрочем, говорить о закате реляционных DWH и NoSQL-хранилищ Data Lake еще преждевременно. Кроме того, если новая гибридная архитектура будет иметь эффективные технологии реализации, она еще более усилит позиции и возможности классических DWH в корпоративном ИТ-ландшафте, сочетая согласованность и надежность отчетных данных с гибкостью аналитики и ML. Как эта архитектура меняет подходы к построению конвейеров обработки данных, читайте в нашей новой статье. А здесь вы узнаете про эволюцию этого подхода под названием Streamhouse.
Читайте в нашей следующей статье про архитектурные принципы и инструментальные средства LakeHouse. А как внедрить современные архитектурные модели в свои ИТ-проекты аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

