
Чем похожи Apache Beam и Apache Wayang, чем они отличаются, что и когда выбирать для практического использования в аналитике и обработке больших данных: сравнительная таблица по 10 критериям. Сходства и отличия Apache Wayang и Apache Beam Недавно я писала про сходство и различие Apache Wayang и Trino, где упоминала, что...

Что такое Apache Wayang, чем он похож на Beam и в чем разница с Trino: архитектура и принципы работы еще одного распределенного фреймворка интеграции данных. Что такое Apache Wayang и чем это отличается от Trino Trino – это мощный, но далеко не единственный инструмент распределенного выполнения аналитических запросов, способный обрабатывать...

Можно ли при разработке конвейера Apache Beam использовать преобразования из SDK разных языков программирования и как это сделать, избежав типичных ошибок. Кросс-языковые преобразования и мультиязычные конвейеры Beam Как и многие популярные фреймворки для создания распределенных приложений обработки данных (Apache Flink, Spark и другие движки), Apache Beam поддерживает несколько языков. В...
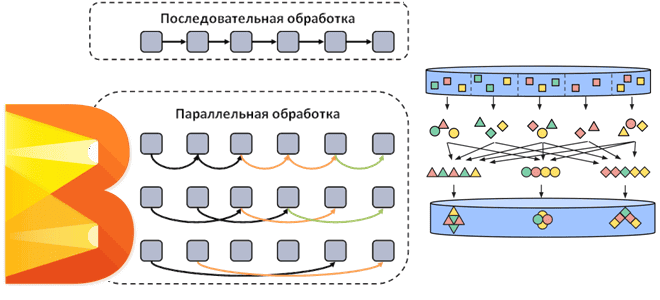
Как Apache Beam распараллеливает потоковые и пакетные конвейеры обработки данных, добавляя собственные операции к пользовательским преобразованиям. Смотрим на примере простого пакетного конвейера с ограниченным параллелизмом. Распараллеливание операций в Apache Beam Напомним, Apache Beam представляет собой унифицированную модель определения пакетных и потоковых конвейеров параллельной обработки данных, которую можно запустить в любой...

Чем Apache Beam отличается от Apache Flink, что и когда выбирать, зачем их совмещать для реализации сложных конвейеров обработки больших объемов данных с помощью распределенных stateful-приложений, и как это работает. Сходства и отличия Apache Beam и Flink Хотя Apache Beam является унифицированной моделью определения пакетных и потоковых конвейеров параллельной обработки данных,...
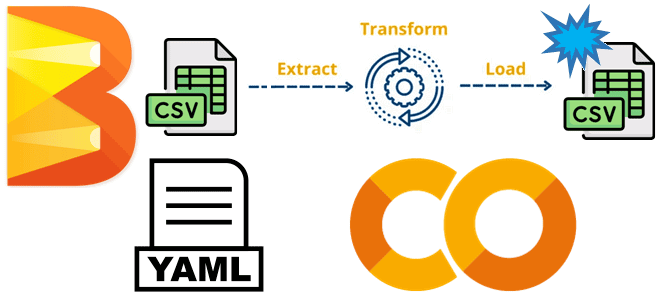
Как написать конвейер обработки данных Apache Beam, задав цепочку преобразований в YAML-конфигурации: практический пример фильтрации и агрегации платежей из CSV-файла. Пример разработки и запуска YAML-конвейера Apache Beam в Google Colab Недавно я рассказывала про Apache Beam – унифицированную модель определения пакетных и потоковых конвейеров параллельной обработки данных, которую можно запустить...
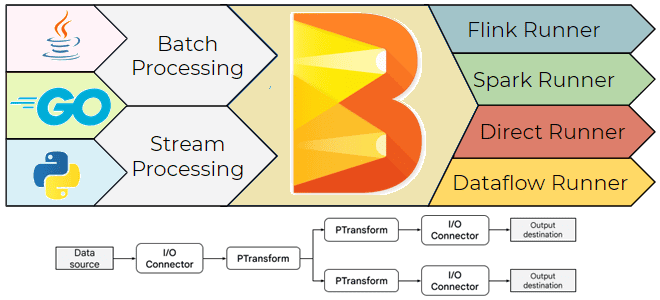
Что такое Apache Beam, зачем он нужен, чем полезен дата-инженеру и как его использовать: архитектура, принципы работы и примеры построения пакетных и потоковых конвейеров обработки данных. Что такое Apache Beam и зачем он нужен Хотя выбор технологического стека – один из важнейших вопросов архитектурного проектирования, иногда требуется универсальное решение построения...

В этой статье по обучению дата-инженеров разберем, что такое Apache Beam, чем этот фреймворк отличается от AirFlow и что между ними общего. На первый взгляд Apache Airflow и Beam являются конкурентами: они предназначены для организации процессов обработки данных в определенном порядке. Оба инструмента являются open-source проектами, широко используются и поддерживаются...