Недавно мы писали про новую гибридную архитектуру Lakehouse, которая объединяет лучше из мира озер и хранилищ данных. Сегодня разберем принципы работы и особенности построения этой архитектуры данных, включая технологии ее реализации с точки зрения дата-инженера и уделим внимание организации конвейеров аналитики больших данных.
Архитектурная парадигма Lakehouse
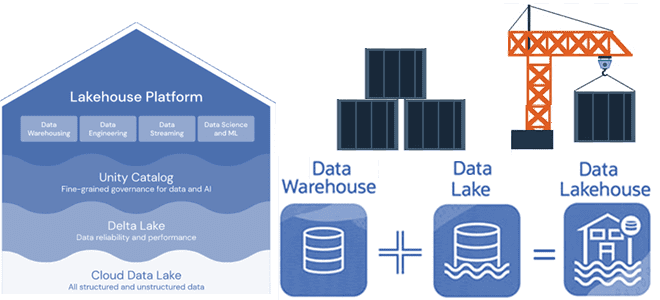
Напомним, Lakehouse — это новая открытая гибридная архитектура данных, сочетающая лучшие элементы озер и хранилищ данных. Эта модель стала возможной благодаря реализации структур данных и функций управления ими, аналогичных тем, которые используются в хранилище данных, непосредственно поверх недорогого облачного хранилища в открытых форматах.
Для организации Lakehouse нужна слаженная работа дата-инженеров. В частности, по аналогии с озерами данных, требуется развернуть и настроить ETL-процессы, включая пакетные и потоковые сервисы приема данных из различных источников. Согласно эмпирическому правилу, данные должны приниматься без каких-либо преобразований и храниться в Data Lake в зоне сырых данных, откуда их потребляют сервисы преобразования. Они выполняют такие операции, как очистка, объединение, применение сложной бизнес-логики и преобразование данных в формат, который можно использовать для последующего анализа, включая AI и BI-системы.
Данные также периодически помещаются в промежуточный слой, называемый зоной очищенных данных, чтобы устранить необходимость многократного дублирования результатов обработки. Окончательные обработанные данные хранятся в соответствующей зоне Data Lake, откуда их можно их использовать для анализа, машинного обучения и отчетности. Однако, в отличие от классических DWH, озера данных обычно не подходят для структурированной отчетности или самостоятельной бизнес-аналитики.
Службы каталогизации данных обеспечивают надлежащую каталогизацию всех данных исходной системы, данных в озере и хранилище, конвейеров обработки и результатов, извлеченных из DWH. Это предотвращает превращение озер и хранилищ данных в болото. Аналитические службы используются для разных целей: Data Scientsit создает аналитические песочницы для проведения экспериментов и проверки гипотез, аналитик – для выполнения быстрых запросов, а сервисы AI/ML выполняют задачу запуска и обслуживания моделей. Службы BI предоставляют пользователям возможности самостоятельной бизнес-аналитики с широкими возможностями визуализации.
Для реализации Lakehouse рекомендуется применять следующие архитектурные принципы:
- разделение вычислений и хранения данных, что обеспечивает гибкость развертывания вычислительных сервисов по запросу и их масштабирования. Хранение дешевое и постоянное. Вычисления дорогие и эфемерные.
- Наличие целевых уровней хранения – данные будут проявляться в различных формах и формах. Способ хранения данных должен быть гибким, чтобы соответствовать различным формам и назначениям данных. Гибкость включает наличие различных уровней хранения (реляционных, графовых, на основе документов и больших двоичных объектов) в зависимости от типа данных и способа их обслуживания.
- модульная архитектура. Основанный на сервис-ориентированной архитектуре (SOA), этот принцип гарантирует, что данные останутся в ядре. Различные типы сервисов, такие как службы приема, обработки и каталогизации данных, а также аналитические сервисы, будут доставляться к данным, а не наоборот.
- Фокус на функциональности, а не на технологиях, что обеспечит гибкость. Функциональность постепенно меняется. Технологии меняются быстрее. Важно сосредоточиться на одной задаче, которую выполняет компонент, чтобы легко заменить техническую часть по мере развития технологии.
- Активная каталогизация, чтобы озеро данных не превратилось в болото. Наличие четких принципов управления каталогизацией важно для надлежащего документирования данных в озере данных. Обычно каталогизируются источники данных, сами данные, хранящиеся в озере или на уровне обслуживания, и происхождение того, как данные преобразуются из источника в уровень обслуживания.
Прежде чем перейти к инструментам практической реализации этих архитектурных принципов, отметим, что идея Lakehouse совпадает с концепцией сетки данных (Data Mesh) – парадигмы децентрализованного доменно-ориентированного управления данными, о которой мы писали здесь и здесь. В сетке данных, впервые предложенной в 2019 году, предлагается предметно-ориентированный дизайн самообслуживания разных групп данных множеством распределенных команд. Это помогает решить проблемы, которые часто возникают при быстром масштабировании централизованного подхода к данным с опорой на озеро данных или хранилище данных. Потребление, хранение, преобразование и вывод данных децентрализованы, и каждая группа данных домена обрабатывает свои собственные данные. Однако, сетка данных как концепция сегодня пока не имеет полноценного инструментального воплощения, в отличие от Lakehouse, технологии реализации которого мы рассмотрим далее.
Практическая реализация: инструменты и технологии
Одним из средств реализации Lakehouse является соответствующая платформа Databricks, которая интегрирована с сервисами Microsoft Azure Synapse Analytics. Другие управляемые сервисы, такие как BigQuery и Redshift Spectrum, имеют некоторые из функций Lakehouse, хотя являются примерами, ориентированными в первую очередь на BI-системы и другие SQL-приложения. Для реализации собственных систем можно использовать форматы файлов с открытым исходным кодом, такие как Delta Lake, Apache Iceberg, Hudi и пр.
Объединение озер данных и хранилищ данных в единую систему означает, что команды обработки данных смогут работать быстрее, используя данные по мере необходимости без обращения к нескольким источникам. Поддержка SQL и интеграция с инструментами бизнес-аналитики среди LakeHouse достаточны для большинства традиционных DWH. Доступны материализованные представления и хранимые процедуры. Также пользователи имеют доступ к множеству стандартных инструментов (Spark, Python, R, библиотеки машинного обучения) для рабочих нагрузок, не связанных с BI, таких как Data Science и Machine Learning. Исследование и уточнение данных являются стандартными для многих аналитических приложений и приложений для обработки и анализа данных. Delta Lake позволяет пользователям постепенно улучшать качество данных в LakeHouse, пока они не будут готовы к использованию.
В то время как распределенные файловые системы могут использоваться для уровня хранения, хранилища объектов чаще используются в новой гибридной архитектуре, обеспечивая недорогое, высокодоступное хранение, которое превосходно справляется с массовым параллельным чтением. Важно, что Lakehouse ускоряет доступ к информации, сокращая перемещение данных между разными системами и поддерживая прием как потоковых, так и пакетных данных в одну и ту же структуру. Это устраняет необходимость в дополнительном шаге для консолидации пакетных и потоковых данных, приводит к более оптимизированному конвейеру с наименьшим количеством переходов и более быстрым временем окупаемости. Таким образом, с Lakehouse в большинстве случаев требуется менее 5 минут, чтобы получить данные от момента их создания до визуализации на дэшборде.
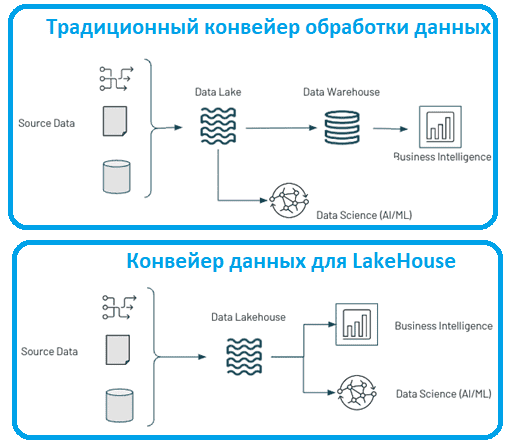
Благодаря интеграции хранилищ данных и озер данных в единый источник истины, поддерживающий как SQL, так и Python, Data Scientist’ы и аналитики могут запрашивать Lakehouse как одно окно достоверных данных для всего предприятия. Это упрощает и ускоряет процесс создания отчетов BI, а также моделей AI/ML. Наконец, открытый исходный код и отсутствие привязки к конкретному провайдеру делают Lakehouse лучше обычного озера данных. Вместо того, чтобы хранить данные в простых удобочитаемых форматах типа CSV или JSON, в Lakehouse данные хранятся в сжатом открытом Parquet-формате, который лучше подходит для быстрого чтения и записи. Для доступа к этим данным со своего компьютера через Python-методы не нужно платить провайдеру.
Помимо хранения данных в Parquet-формате, можно также отслеживать метаданные этих файлов и логировать все операций с файлами, чтобы лучше организовывать данные внутри самих файлов и управлять ими. Это делает процесс управления данными в LakeHouse намного проще и эффективнее. В настоящее время существует три основных проекта с открытым исходным кодом, которые помогут построить LakeHouse: Delta Lake, Apache Iceberg и Hudi. Каждый из этих форматов поддерживается крупными компаниями, а также отдельными разработчиками сообщества.
Наконец, стоимость хранения данных в LakeHouse вполне доступно, т.к. физически данных хранятся в дешевых облачных системах типа AWS S3, Azure ADLS или GCP GCS. Стоимость вычислений сводится к цене кластера Apache Spark или Flink, который используется для рабочих нагрузок. А в случае небольших вычислений нет необходимости в крупном кластере – можно запрашивать данные со своего ноутбука или виртуальной машины в облаке, используя Python. В отличие от хранилищ данных, которые обычно всегда включены, даже если не используются, в архитектуре LakeHouse кластер включается только тогда, когда нужно запросить данные. Таким образом, LakeHouse помогает упростить обработку данных и демократизировать использование данных в организации при минимально возможных затратах. Это особенно важно для мелкого и среднего бизнеса.
Пример практической реализации архитектуры LakeHouse на Greenplum и Cloudian HyperStore Object Storage смотрите в нашей новой статье. А здесь мы рассказываем о важности отслеживания времени событий в источниках и их приеме в LakeHouse с точки зрения информационной безопасности.
Как внедрить современные архитектурные модели в свои ИТ-проекты аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

