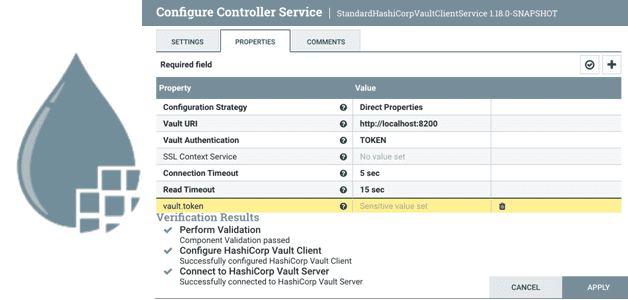
Что такое Controller Service в Apache NiFi и как дата-инженеру создать собственный набор настроек для совместного и повторного использования в потоковом конвейере обработки данных. Что такое Controller Service в Apache NiFi Apache NiFi реализует потоковую парадигму обработки информации, выполняя ETL-операции над FlowFile с помощью обработчиков, называемыми процессорами. Если какие-то процессоры...

Что такое Ververica Runtime Assembly, чем GeminiStateBackend лучше RocksDB и еще несколько отличий коммерческого облачного решения от открытого Apache Flink. Что такое Ververica Cloud и при чем здесь Apache Flink Технологии с открытым исходным кодом развиваются намного быстрее при поддержке крупных корпораций. Например, компания Confluent продвигает Apache Kafka, Astronomer –...
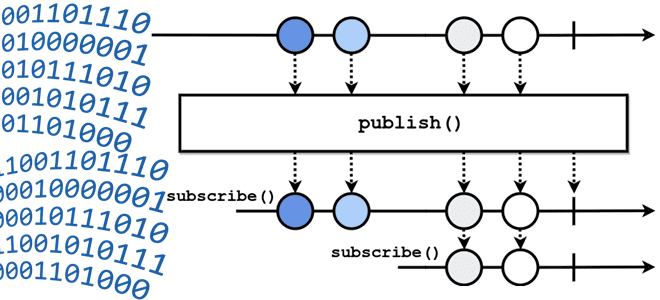
Что означает термин backpressure и зачем создавать обратное давление в streaming-системах: разбираемся с методами управления пропускной способностью потоковой передачи событий на примере Apache Kafka, Flink, Spark и NiFi. Что такое обратное давление: backpressure в конвейерах потоковой обработки данных Понять, как работает сложная концепция, проще всего на простых примерах. Это общее...
Завершая цикл статей про мультирегиональную репликацию кластеров Apache Kafka, сегодня поговорим про стратегии развертывания топологий, предлагаемых компанией Confluent. Принципы архитектуры, сравнение, сценарии, критерии выбора. Критерии выбора топологии репликации кластера Apache Kafka Для повышения надежности и производительность потоковой обработки данных с использованием Apache Kafka кластера этой платформы рекомендуется располагать в разных...
Сегодня я покажу на практическом примере, как реализовать потоковый захват изменения данных из таблицы PostgreSQL и их репликацию в Apache Kafka с помощью Debezium. Создаем и настраиваем свой коннектор на платформе Upstash. Постановка задачи Паттерн захвата измененных данных (CDC, Change Data Capture) является одним из самых распространенных в инженерии данных....
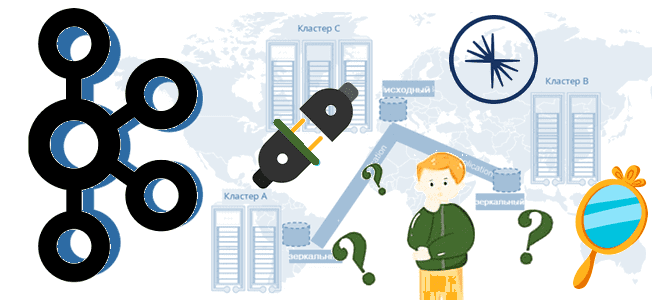
Продолжая разговор про межрегиональную репликацию Apache Kafka, сегодня рассмотрим 4 способа ее реализации: мультирегиональный кластер, MirrorMaker 2, Cluster Linking в Confluent Server и Confluent Replicator. Чем георепликация Kafka с MirrorMaker 2 отличается от решений Confluent и что выбирать для различных сценариев. Мультирегиональный кластер Confluent Геораспределенная репликация реплицирует данные по кластерам...
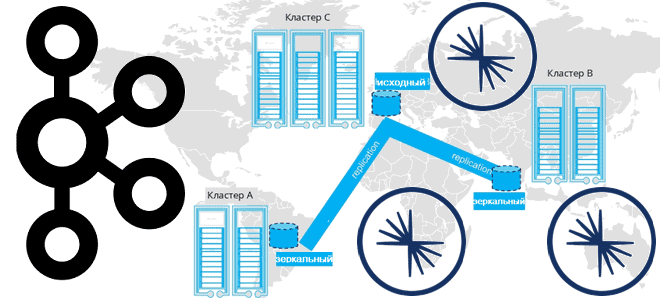
Недавно мы писали про мультирегиональную репликацию Apache Kafka. Сегодня рассмотрим, как выполнить геораспределенную репликацию с помощью Cluster Linking в Confluent Server и Kafka Connect с Confluent Replicator. Cluster Linking для Apache Kafka Связанные кластеры представляют собой 2 или более кластера в разных географических регионах. В отличие от топологии растянутого кластера,...

Как спроектировать DAG и выбрать способ обмена данными между задачами, где определить подключения и запросы к БД и что поможет избежать ада Python-зависимостей при использовании Apache AirFlow. Сегодня я расскажу своем личном опыте наступания на грабли при работе с этим оркестратором batch-процессов и уроках, которые из этого вынесла. 5 советов...
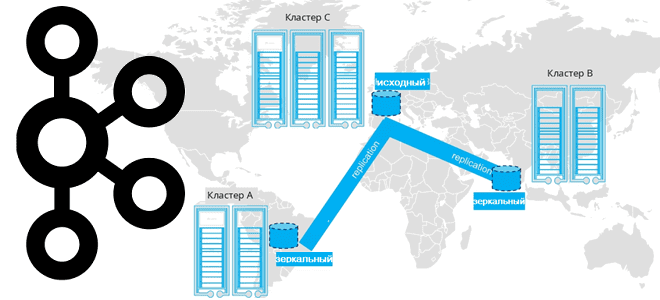
Какую топологию может иметь кластер Apache Kafka при межрегиональной репликации по нескольким ЦОД и как это реализовать. Чем брокеры-наблюдатели отличаются от подписчиков в Confluent Server и при чем здесь конфигурация подтверждений acks в приложении-продюсере. Принципы репликации данных в Apache Kafka Будучи средством интеграции информационных систем в режиме реального времени, Apache...
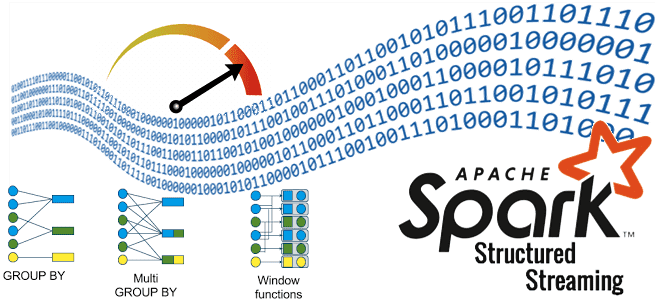
Как выполнение нескольких stateful-операторов в одном потоке снижает стоимость обработки данных: возможности и ограничения Spark Structured Streaming. Про водяные знаки и состояния в потоковой передаче событий. Stateful-операторы и водяные знаки в потоковой обработке данных Благодаря распределенной обработке микропакетов в памяти Spark Structured Streaming позволяет обрабатывать огромные объемы данных очень быстро....