
Что такое WSL, Docker и как запустить веб-сервер Apache AirFlow в контейнере на локальной машине в Ubuntu поверх Windows вместо любимого Google Colab. Пошаговое руководство для начинающих дата-инженеров. Краткий ликбез по WSL и Docker для любителей Windows Обычно я всегда запускала веб-сервер Apache AirFlow в интерактивной среде Google Colab, которая...
Недавно я писала, как с помощью source-коннектора Debezium организовать потоковый захват изменения данных из таблицы PostgreSQL путем публикации CDC-событий в Apache Kafka. Продолжая эту тему, сегодня покажу пример визуализации аналитики этих данных в Kibana, предварительно загрузив их в Elasticsearch с sink-коннектором Aiven. Постановка задачи и проектирование конвейера Как обычно, в...
Зачем менять базу данных метаданных в производственном развертывании Apache AirFlow и как это сделать: пошаговое руководство для дата-инженера с примерами и рекомендациями. 5 шагов перехода от SQLLite к PostgreSQL: миграция базы данных метаданных Apache AirFlow Чтобы планировать и запускать конвейеры обработки данных, Apache AirFlow хранит сведения о задачах, DAG, исполнителях,...
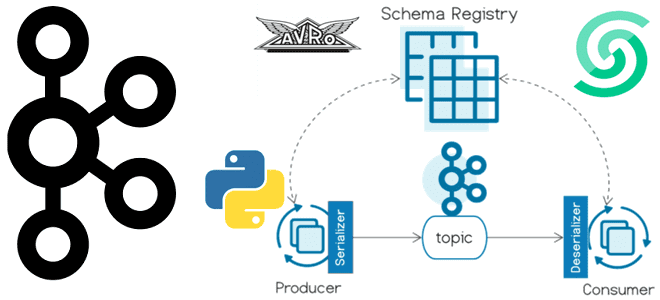
Сегодня я покажу пример использования реестра схем для Apache Kafka на платформе Upstash, API которого полностью совместим со Schema Registry от Confluent. Пишем продюсер на Python, используя библиотеку confluent_kafka. Еще раз о том, что такое реестр схем Kafka и чем он полезен Реестр схем (Schema Registry) – это модуль Confluent...

Когда журналирование событий может привести к OOM-ошибке, где отслеживать системные метрики приложения Apache Spark, зачем сжимать лог-файлы и как это сделать. Логирование системных метрик в приложении Apache Spark Поскольку фреймворк Apache Spark изначально предназначен для создания высоконагруженных распределенных приложений пакетной и потоковой обработки больших объемов данных, он позволяет отслеживать системные...
Зачем Databricks выпустил Arc, чем это отличается от Splink, и как эти инструменты позволяют решать проблему связывания данных с помощью алгоритмов машинного обучения. Как работает связывание данных Продолжая разговор про качество данных и разрешение сущностей (entity resolution) , сегодня подробно рассмотрим этап связывания записей с использованием логики на основе правил...
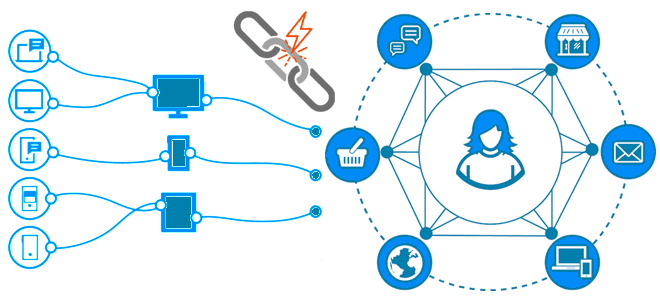
Как качество данных связано с разрешением сущностей, чем entity resolution отличается от identity resolution, зачем нужны графы идентичности, как их построить и где использовать. Борьба за качество данных с entity resolution Результаты аналитической обработки данных напрямую зависят от их качества, о ключевых показателях и задачах обеспечения которого мы писали здесь....
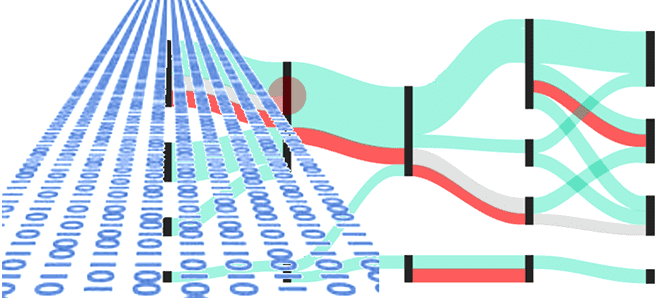
Чем пакетная парадигма обработки данных отличается от пакетной и как она реализуется на практике: принципы работы и воплощение в Big Data на примере Apache Spark, Kafka и Flink. Еще раз о разнице потоковой и пакетной парадигмы обработки данных Пакетная обработка и потоковая обработка — это две разные парадигмы обработки данных....

Зачем ограничивать доступ к папке с DAG и как это сделать: категории и роли пользователей в Apache AirFlow, способы входа в систему и конфигурации для настройки прав. Категории и роли пользователей Apache AirFlow Поскольку основным источником угрозы почти для любой информационной системы являются люди, при разработке методов обеспечения безопасности надо,...
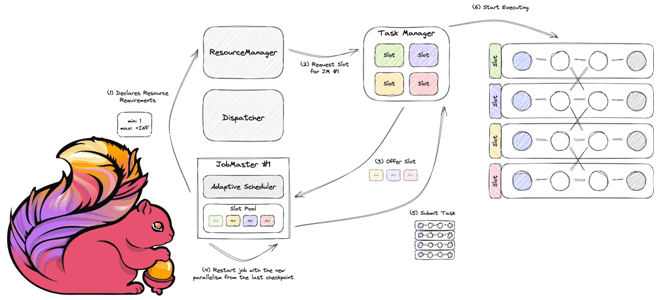
Как работает планировщик заданий в Apache Flink, чем разные реализации Scheduler отличаются друг от друга, и каковы преимущества адаптивных планировщиков. Как Apache Flink планирует выполнение заданий клиентской программы Архитектура Apache Flink, которую мы рассматривали здесь, включает несколько компонентов. Одним из них является планировщик заданий, которые отправляются клиентским приложением в диспетчер...