 1218
1218 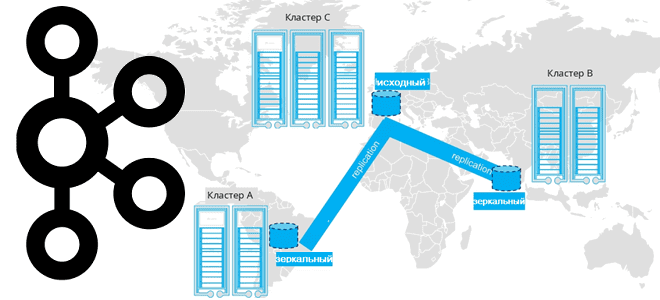
Содержание
Какую топологию может иметь кластер Apache Kafka при межрегиональной репликации по нескольким ЦОД и как это реализовать. Чем брокеры-наблюдатели отличаются от подписчиков в Confluent Server и при чем здесь конфигурация подтверждений acks в приложении-продюсере.
Принципы репликации данных в Apache Kafka
Будучи средством интеграции информационных систем в режиме реального времени, Apache Kafka является критически важным компонентом ИТ-архитектуры предприятия. Поэтому многие компании стараются повысить ее надежность, организуя не локальный кластер, а реплицируя эту платформу потоковой передачи событий по нескольким географически распределенным центрам обработки данных (ЦОД). Когда кластер Kafka развернут в одном регионе или в одном ЦОД, авария в центре обработки данных или сбой облачного провайдера может полностью вывести ИТ-инфраструктуру из строя. А если с Apache Kafka работают клиенты из разных регионов, возрастают затраты на передачу данных, которые и так составляют бОльшую часть эксплуатационных расходов, о чем мы недавно писали здесь.
Георепликация кластера Kafka на несколько регионов решает эти проблемы, обеспечивая высокую доступность и аварийное восстановление. Также географическая распределенность снижает сетевые расходы, позволяя размещать данные ближе к клиентам. Чтобы понять, как организовать георепликацию Kafka, сперва вспомним ключевые принципы работы этой платформы.
Брокер Kafka хранит сообщения в топике, который включает один или несколько разделов – лог-файлов на диске с последовательной записью. Kafka гарантирует порядок сообщений только внутри раздела, позволяя приложениям-продюсерам публиковать в них сообщения в реальном времени согласно стратегии разделения. В свою очередь, приложения-потребители считывают данные из этих разделов. Каждое сообщение в логе уникально идентифицируется смещением (offset), которое может быть нескольких категорий:
- Log Start Offset — первое доступное смещение;
- High Watermark — смещение последнего сообщения, которое было успешно записано и зафиксировано в логе брокерами;
- Log End Offset — смещение последнего сообщения, записанного в лог, которое может находиться дальше верхней отметки.
Kafka не просто записывает каждое сообщение на диск, а для надежности делает нескольких копий данных в зависимости от значения фактора репликации. Реплики для каждого раздела распределяются равномерно, при этом одна реплика выбирается ведущей, а остальные — ведомыми. Ведущие реплики записываются на брокер-лидер, а ведомые, которые ее копируют сохраняются на брокерах-подписчиках.
Конфигурация продюсера acks определяет количество подтверждений, которые он ждет от лидера, прежде чем считать запрос завершенным. Это контролирует долговечность отправляемых записей. Допускаются следующие значения конфигурации acks:
- 0, когда приложение-продюсер не ждет подтверждения от сервера – каждая отправленная запись немедленно добавляется в буфер сокета и считается отправленной. Это быстрее, но не очень надежно, т.к. нет гарантии, что сервер получил запись.
- 1, когда брокер-лидер сохраняет запись в свой локальный журнал и сообщает об этом продюсеру, не дожидаясь подтверждения об успешной репликации от брокеров-подписчиков. Это чуть медленнее, чем предыдущий вариант, но чуть более надежно. Однако, если брокер-лидер выйдет из строя сразу после подтверждения записи, но до ее репликации подписчиками, запись будет потеряна.
- all – брокер-лидер ожидает, пока полный набор синхронизированных реплик подтвердит запись. Это гарантирует, что запись не будет потеряна, пока существует хотя бы одна синхронизированная реплика. Такой вариант медленнее предыдущих, но дает самую надежную гарантию долговечности.
Kafka использует модель репликации на основе извлечения, когда выделенные потоки выборки периодически извлекают данные между парами брокеров. Каждая реплика представляет собой побайтовую копию друг друга, что обеспечивает сохранение смещения репликации. Лидер поддерживает набор синхронных реплик (ISR, In Sync Replica), фиксируя сообщения после его репликации в наборе ISR. Если брокер-подписчик перестает отвечать на запросы, набор ISR сокращается. Но пока есть хотя бы минимальное количество доступных синхронизируемых реплик, что настраивается с помощью конфигурации min.insync.replicas, раздел будет по-прежнему доступен для записи. По умолчанию значение min.insync.replicas равно 1. Kafka отслеживает лидера раздела с помощью монотонно возрастающего целого числа, называемого эпохой, которое увеличивается контроллером кластера Kafka при выборе нового лидера.
Вспомнив основные принципы репликации данных в пределах одного кластера, далее рассмотрим, как это реализуется при географической распределенности на несколько зон доступности.
Репликация в разных топологиях кластера Apache Kafka
Для репликации в нескольких регионах кластер Kafka может иметь следующую топологию:
- растянутые кластеры (stretched clusters), когда один кластер Kafka устанавливается в нескольких ЦОД. При этом используется протокол синхронной репликации Kafka.
- связанные кластеры (connected clusters) с асинхронной репликацией в нескольких регионах. В этом случае может использоваться внешняя система для копирования данных из одного или нескольких кластеров в другой.
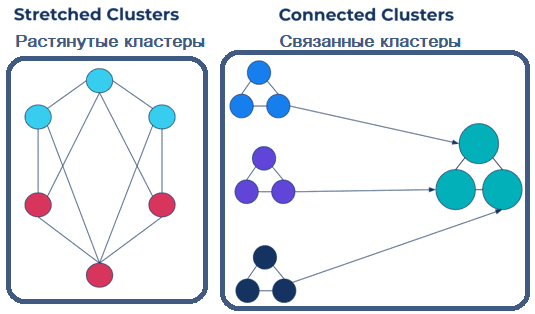
Преимущество растянутого кластера в том, что он сохраняет смещения, а также обеспечивает быстрое аварийное восстановление и автоматическое переключение клиента при сбое без дополнительного кода. Благодаря KIP-392 Apache Kafka позволяет потребителям читать из ближайшей реплики, чтобы сократить затраты на передачу данных по сети и снизить задержку их обработки. Однако, для растянутых кластеров нужна предсказуемая и стабильно низкая задержка между брокерами в кластере, что ограничивает расстояние между центрами обработки данных.
Confluent Server представляет новый тип брокеров, называемых наблюдателями, которые являются асинхронными репликами. Они копируют разделы лидера так же, как это делают подписчики, но не участвуют в ISR и никогда не становятся лидерами раздела. Когда количество синхронизованных реплик раздела падает ниже значения конфигурации min.insync.replicas, продюсер с acks=all больше не может публиковать данные. В этом случае для включения в список ISR будет выбран один из наблюдателей. Это восстановит доступность раздела и позволит продюсеру снова публиковать данные. В это время наблюдатель действует как синхронная реплика: он должен получить данные, прежде чем продюсер сможет снова успешно публиковать их. Как только вышедший из строя брокер-подписчик восстановится и присоединится к списку ISR, повышенный до уровня подписчика брокер-наблюдатель будет автоматически понижен: исключен из списка ISR и снова станет асинхронной репликой. Наблюдатели обеспечивают надежность и доступность в случае сбоя центра обработки данных, а автоматическое переключение при сбое ограничивает время простоя. При этом такое нововведение не влияет на публикацию или сквозную задержку во время обычных операций.
Связанные кластеры представляют собой 2 или более кластера в разных географических регионах. В отличие от предыдущей топологии, вместо одного кластера их несколько, и они управляются независимо. Такие кластеры можно развернуть с помощью Kafka Connect или без нее с использованием решения Cluster Linking, встроенного в Confluent Server. Как это работает, мы рассмотрим в следующий раз. А здесь вы узнаете про стратегии развертывания мультирегиональной репликации.
Узнайте больше про администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
[elementor-template id=»13619″]
Источники

