 1563
1563 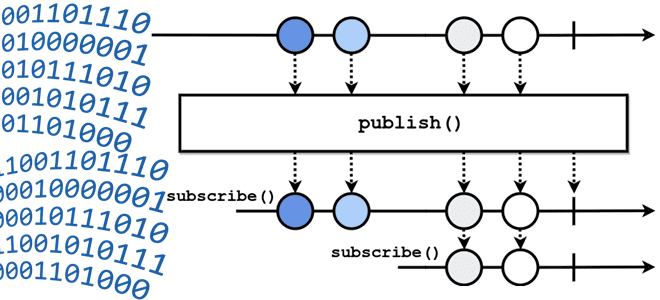
Содержание
Что означает термин backpressure и зачем создавать обратное давление в streaming-системах: разбираемся с методами управления пропускной способностью потоковой передачи событий на примере Apache Kafka, Flink, Spark и NiFi.
Что такое обратное давление: backpressure в конвейерах потоковой обработки данных
Понять, как работает сложная концепция, проще всего на простых примерах. Это общее правило работает и в ИТ. Например, потоковую парадигму обработки информации можно объяснить на примере бесконечного потока жидкости через трубу. Если скорость поступления жидкости намного больше скорости ее отведения, в трубе создается избыточное давление и может возникнуть разрыв. Чтобы избежать этого, необходимо сопоставлять скорость поступления со скоростью отведения потока или иметь накопитель для излишней жидкости, которая поступила, но еще не отведена. Это называется обратное давление (backpressure).
Аналогичное понятие есть и в потоковой парадигме обработки данных, где одни приложения (продюсеры) непрерывно генерируют данные, а другие (потребители) их обрабатывают. Для асинхронной интеграции продюсеров и потребителей в качестве места временного накопления опубликованных, но еще не потребленных данных используется канал. В роли канала может использоваться файл, база данных или топик/очередь брокера сообщений, когда данных очень много.
Если скорость публикации намного выше скорости потребления данных, приложение-продюсер не успевает их обрабатывать и в объем занятого пространства в канале растет. Если размер канала ограничен, это чревато потерями данных. Например, в Apache Kafka сработает политика очистки топика, когда он превысил максимально допустимый раздел, заданный в конфигурации retention.size. А в случае RabbitMQ сообщения просто не будут отправляться в нужную очередь и потеряются, если не настроена гибкая маршрутизация с dlq-обменниками и очередями подобно тому, как я рассказывала здесь.
Поэтому при проектировании streaming-системы очень важно учитывать пропускную способность каждого звена, чтобы обеспечить высокую скорость всей системы. Для этого есть следующие техники:
- прекратить публикацию данных, остановив продюсера специального вызова или заблокировав его;
- масштабировать канал, например, добавив еще один раздел топика для Kafka;
- использовать буфер в виде очереди недоставленных сообщений, файла или базы данных, куда будут записываться все сообщения, которые не удалось опубликовать в канале. Это легко сделать не для всех платформ: как я уже отметила, в случае RabbitMQ настроить dlq-маршрутизацию довольно просто средствами самого фреймворка. А вот для Kafka придется настраивать конфигурации повторной публикации на продюсере: timeout.ms, retry.backoff.ms и max.in.flight.requests.per.connection.
- масштабировать потребителя, оперативно развернув еще один экземпляр в моменты пиковой нагрузки. Это удобно при развертывании экземпляров приложения-потребителя по требованию в облачной платформе.
Наилучшим способ реализации обратного давления считается управление скоростью публикации. Это не накладывает никаких ограничений, кроме накладных расходов на сам механизм управления. Не придется использовать избыточную буферизацию памяти, а также работать с потерями и удалять данные.
Стратегия буферизации опасна, если она не имеет ограничений по размеру или времени буфера. Именно неограниченные буферы являются частым источником сбоев памяти на серверах. Как с этим работать в Kafka, читайте в нашей новой статье.
Спецификация Reactive Streams и ее реализация в Apache NiFi, Flink и Spark Streaming
На практике многие приложения потоковой обработки больших данных реализованы на Java. В частности, фреймворки Apache Flink, Spark и NiFi поддерживают этот язык, позволяя создавать высокопроизводительные и надежные конвейеры потоковой передачи событий. В Java, начиная с версии 9 есть встроенный механизм управления обратным давлением через FlowAPI. FlowAPI поддерживает спецификацию Reactive Streams, которую можно рассматривать как стандарт асинхронной обработки потоков с неблокирующим обратным давлением. Это означает возможность управлять обменом потоковыми данными через асинхронную границу, например, передавать элементы в другой поток или пул потоков, гарантируя, что принимающей стороне не придется буферизовать произвольные объемы данных.
Спецификацию Reactive Streams описывает следующие классы:
- Publisher – издатель (продюсер), который публикует данные;
- Subscriber – подписчик (потребитель), который реагирует на получение данных;
- Subscription – подписка, которая связывает издателя и подписчика;
- Processor – обработчик.
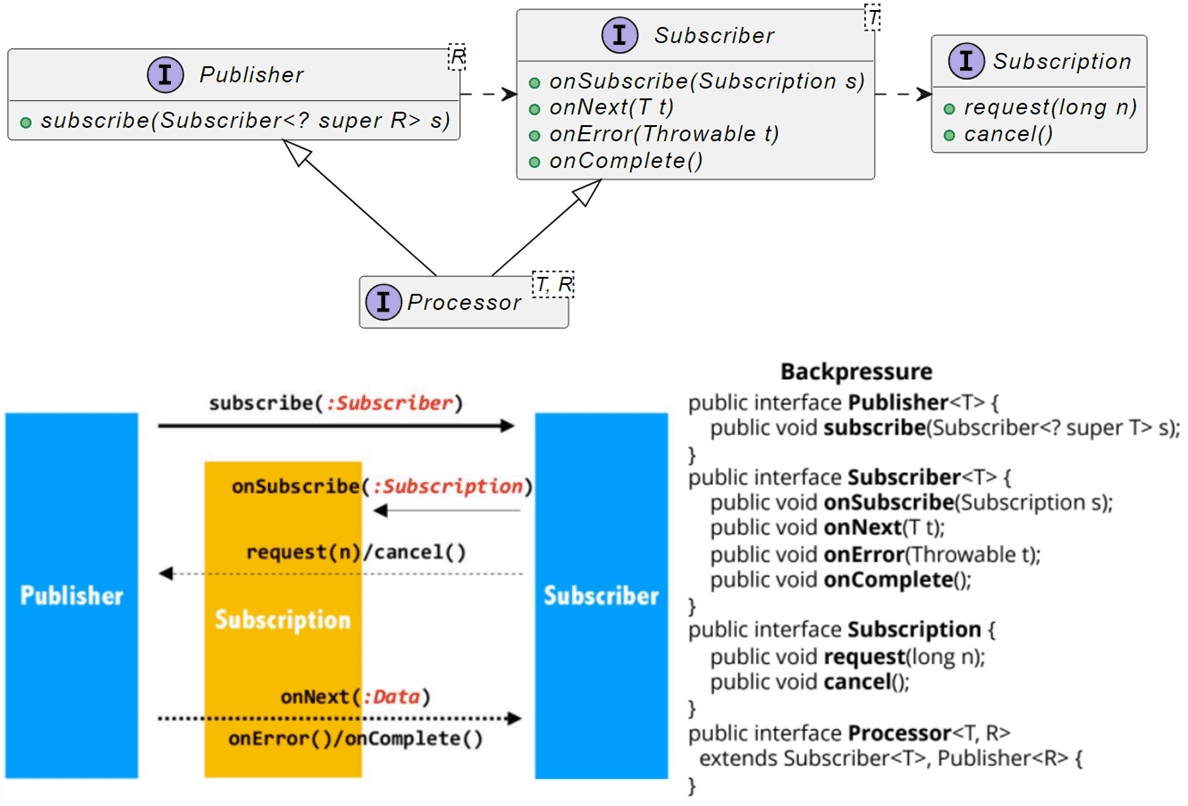
Согласно спецификации Reactive Streams для JVM, подписка является параметром метода обратного давления request(). Subscriber должен обязательно просигнализировать через Subscription.request(long n) для получения сигналов в методе onNext(). Это означает, что подписчик несет ответственность за решение, когда и сколько элементов данных он может и желает получить. Чтобы избежать переупорядочения сигналов, вызванного методами подписки, для синхронных реализаций подписчика настоятельно рекомендуется вызывать методы подписки в самом конце любой обработки сигнала. Также рекомендуется, чтобы подписчики запрашивали верхний предел того, что они могут обработать, поскольку запрос только одного элемента за раз приводит к неэффективному протоколу stop-and-wait.
Многие эти концепции Reactive Streams уже реализованы во фреймворках потоковой передачи событий. Например, в Apache NiFi есть элементы конфигурации обратного давления, о чем мы уже писали здесь. Эти пороговые значения указывают, какой объем данных должен находиться в очереди, прежде чем запуск компонента, являющегося источником соединения, больше не будет запланирован. Это позволяет системе избежать переполнения данными. Конфигурация Back pressure object threshold определяет количество FlowFile, которое может находиться в очереди до применения обратного давления. А конфигурация Back pressure data size threshold определяет максимальный объем данных (по размеру), который должен быть поставлен в очередь перед применением обратного давления. Это значение настраивается путем ввода числа, за которым следует размер данных.
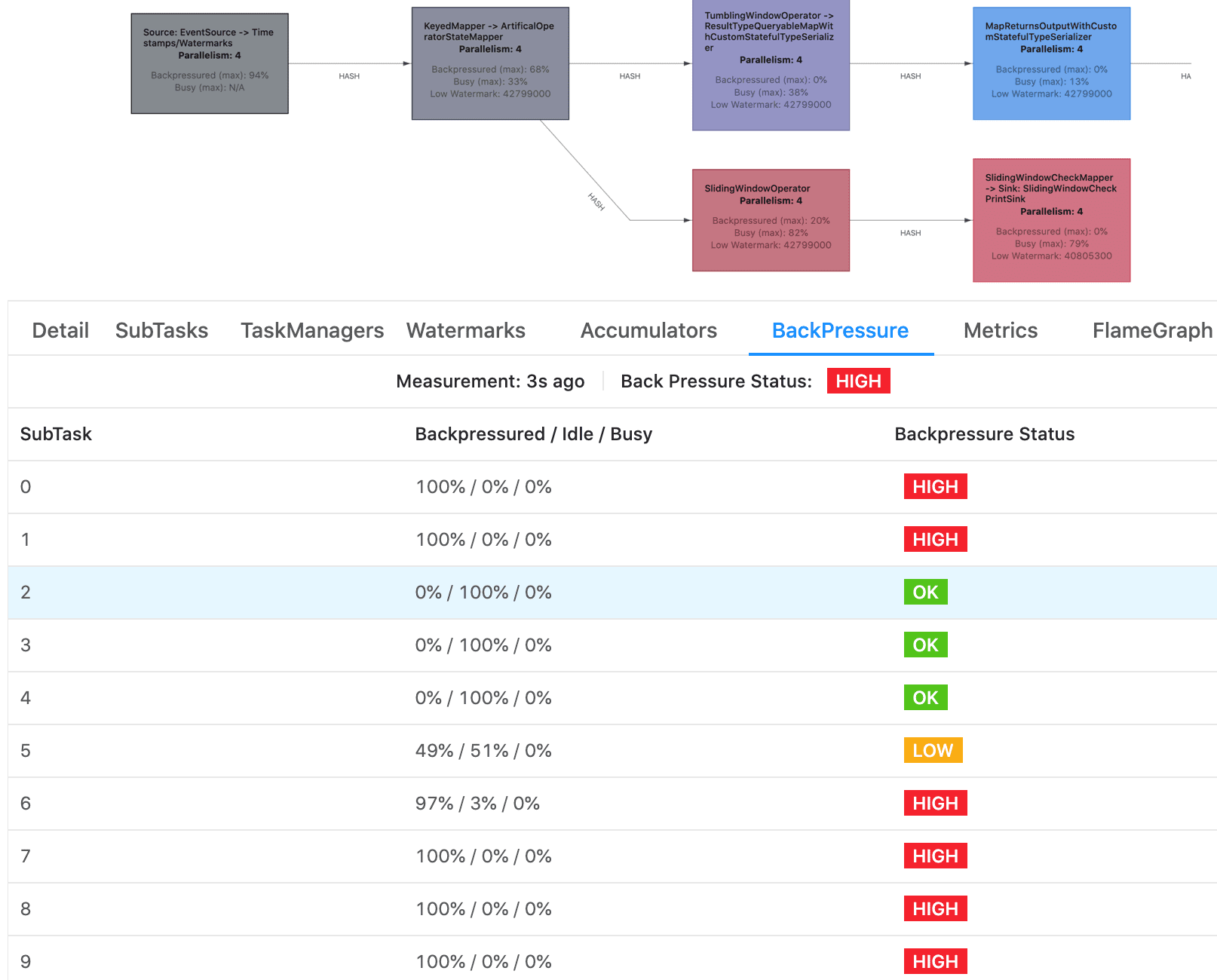
В Apache Flink значение Backpressure вообще выводится визуально в веб-GUI внутри элементов графа задания. Помимо отображения необработанных значений, задачи также имеют цветовую маркировку:
- синим цветом показаны задачи в режиме ожидания;
- черным — задачи с полной нагрузкой;
- красным — полностью занятые задачи.
Подробное значение статуса обратного давления также можно посмотреть в веб-GUI. Для подзадач со статусом ОК индикация обратного давления отсутствует. А маркировка HIGH означает, что подзадача находится под давлением. Статус задачи определяется следующим образом:
- ОК : 0 % <= Backpressure <= 10 %
- Low : 10% < Backpressure <= 50%
- HIGH: 50% < Backpressure <= 100%
Наконец, в Spark Streaming есть конфигурация spark.streaming.backpressure.enabled, установка которой в значение true включает обратное давление. Это функция доступна с версии 1.5 и она устраняет необходимость устанавливать ограничение скорости приемников, поскольку Spark Streaming автоматически определяет и динамически корректирует их при изменении условий обработки.
Узнайте больше про потоковую обработку и аналитику больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Потоковая обработка данных с помощью Apache Flink
- Потоковая обработка в Apache Spark
- Эксплуатация Apache NIFI
Источники

