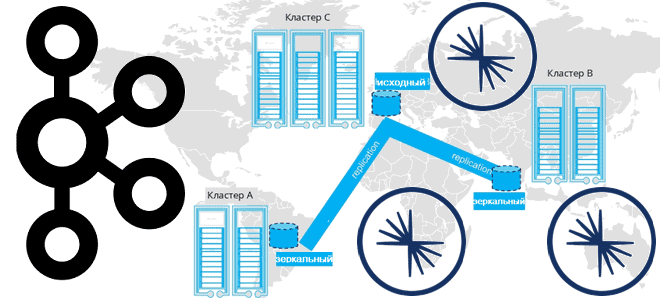
Недавно мы писали про мультирегиональную репликацию Apache Kafka. Сегодня рассмотрим, как выполнить геораспределенную репликацию с помощью Cluster Linking в Confluent Server и Kafka Connect с Confluent Replicator.
Cluster Linking для Apache Kafka
Связанные кластеры представляют собой 2 или более кластера в разных географических регионах. В отличие от топологии растянутого кластера, о которой мы писали здесь, связанные кластеры управляются независимо. Их можно развернуть с помощью Kafka Connect или с использованием решения Cluster Linking, встроенного в Confluent Server.
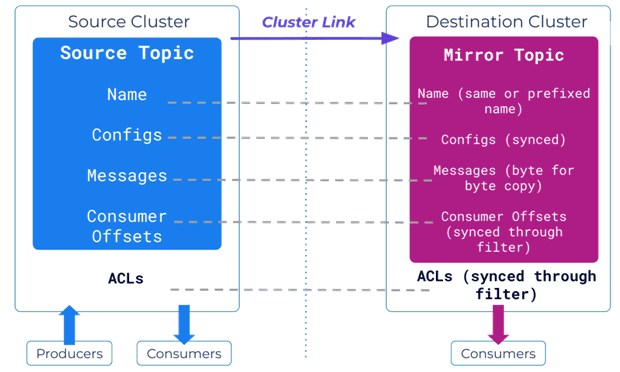
В основе Cluster Linking лежит существующий протокол выборки реплик, который в т.ч. работатет между кластерами. Аналогично тому, как подписчики реплицируют данные с брокера-лидера в одном кластере, лидеры целевых разделов реплицируются из исходных лидеров. Cluster Linking содержит всю информацию, необходимую для связи целевого кластера с исходным: bootstrap-сервер, конфигурация безопасности. Топик в целевом кластере, куда извлекаются данные из исходного, называется зеркальным. Он является побайтовой копией исходного топика, поддерживая четность смещений между кластерами и устраняя необходимость их трансляции. Зеркальный топик имеют такое же количество разделов и конфигурацию, что и исходный. Вместо того, чтобы принимать запросы на публикацию, лидер зеркального раздела распознает, что он является зеркальным, и непрерывно осуществляет выборку данных из соответствующего исходного раздела.
Также можно синхронизировать метаданные: конфигурации топиков, смещения потребителей и ACL-списки управления доступом. Синхронизация конфигурации встроена в зеркальный топик, гарантируя в нем отражение любых изменений в критических конфигурациях исходного топика, например, время хранения или политика удаления. Синхронизация смещений потребителя важна в случае сбоя в исходном кластере, чтобы приложения-потребители исходного кластера могли возобновить свою работу при переключении на целевой кластер. Поскольку связывание кластеров имеет согласованное смещение, заданное смещение в исходном кластере совпадает с целевым кластером, что упрощает переход потребителей из одного кластера в другой. Наконец, синхронизация ACL-списков обеспечивает согласованный уровень безопасности во всех кластерах, устраняя операционную нагрузку и накладные расходы, связанные с их ручным созданием и удалением. А если включено автоматическое создание зеркальных топиков, ссылка на кластер автоматически создаст зеркальные топики в целевом кластере с определенным префиксом или названием, соответствующим исходному.
Отработка отказа в Cluster Linking используется в случаях, когда в исходном кластере происходит сбой и все клиентские приложения необходимо как можно быстрее перенести на целевой кластер. В этой ситуации используется команда аварийного переключения, чтобы немедленно изменить состояние зеркального топика с АКТИВНОГО состояния (ACTIVE) на ОСТАНОВЛЕННОЕ (STOPPED). Перевод зеркального топика в состояние STOPPED позволяет использовать его для активной публикации. После выполнения команды аварийного переключения происходит фиксация смещений потребителей. Любые смещения потребителей, которые были синхронизированы из исходного кластера, фиксируются до смещений конца журнала зеркального топика, а состояние зеркального топика изменяется с ACTIVE на STOPPED. В случае миграции из локальной среды в облако состояние зеркального топика также меняется с ACTIVE на STOPPED, перед этим выполняя окончательную синхронизацию с исходным кластером. После выполнения продвижения происходит следующее:
- синхронизируются конфигурации топиков и смещений потребителей с исходным кластером;
- все смещения потребителей усекаются до смещений конца журнала целевого зеркального топика;
- меняется состояние зеркального топика с ACTIVE на STOPPED.
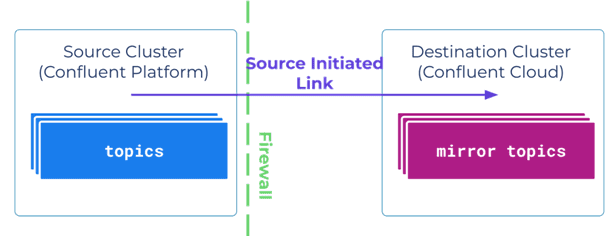
По умолчанию ссылка на целевой кластер инициирует подключение к исходному. Однако, если исходный кластер находится за строгим брандмауэром или не может легко принимать новые подключения по соображениям безопасности, Cluster Linking позволяет источнику инициировать соединение с целевым зеркальным кластером. Как только соединение будет установлено, целевые зеркальные разделы смогут получать данные по установленному каналу. Это полезно, когда исходный кластер Confluent Platform работает за брандмауэром, и данные необходимо перенести в Confluent Cloud.
Использование Kafka Connect с Confluent Replicator
Confluent Replicator позволяет реплицировать топики из одного кластера Kafka в другой. Помимо копирования сообщений, Replicator создает топики по мере необходимости, сохраняя конфигурацию в исходном кластере: количество разделов, коэффициент репликации и пр. Confluent Replicator реализован в виде коннектора платформы Kafka Connect, которая включает следующие ключевые компоненты:
- worker — работающий процесс, который выполняет коннекторы и свои задачи;
- коннектор (connector) —абстракция высокого уровня, которая координирует потоковую передачу данных путем управления задачами;
- задача —фактическая реализация копирования данных в кластер Kafka или из него.
В Kafka Connect существует два типа коннекторов:
- source-коннектор передает данные из внешнего хранилища данных в кластер Kafka с помощью продюсера, встроенного в каждую задачу;
- sink-коннектор, который передает данные из кластера Kafka во внешнее хранилище данных с помощью встроенного потребителя.
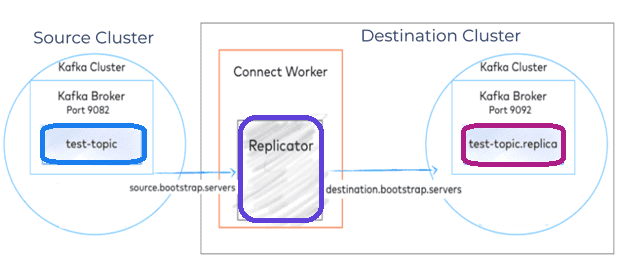
Confluent Replicator реализован как коннектор источника. Source-коннектор загружается в целевой кластер и сохраняет свое состояние в трех различных сжатых топиках, которые содержат важные метаданные:
- Connect-configs хранится последние настройки коннектора;
- Connect-Offsets хранится последние смещения, использованные коннектором;
- Connect-Status хранит последнее состояние коннектора, а также его задачи.
Топик Connect-Offsets особенно важен, когда коннектору при запуске или перезапуске необходимо знать, откуда возобновить обработку записей. Confluent Replicator имеет исходного потребителя, который потребляет записи из исходного кластера, а затем передает эти записи в платформу Connect. Платформа Connect имеет встроенный продюсер, который затем отправляет эти записи в целевой кластер. В дополнение к этому также есть два отдельных AdminClient, по одному для каждого кластера. Клиенты AdminClients отвечают за общие обновления метаданных между кластерами, такие как синхронизация конфигурации топиков и их создание/расширение.
Чтобы использовать сдвиг смещения в Replicator, потребители должны иметь перехватчик ConsumerTimestampsInteceptor. Перехватчик фиксирует смещение и соответствующую ему отметку времени в топике __consumer_timestamps исходного кластера. Confluent Replicator считывает смещение и соответствующую отметку времени, чтобы найти зафиксированное для нее смещение. Затем фиксирует это смещение в целевом топике __consumer_offsets. В случае отказа потребитель будет знать, откуда начать потребление, поскольку Confluent Replicator преобразует смещения для всех групп потребителей с перехватчиками ConsumerTimestampsInteceptor.
Репликатор можно развернуть в кластерах и в нескольких центрах обработки данных, чтобы предоставить пользователям доступ к ближайшему ЦОД, снизив задержку и повысив производительность. Еще это улучшает общую надежность потоковой системы в случае частичного или полного сбоя одного из региональных кластеров, а также позволяет использовать Kafka для синхронизации данных между локальными приложениями и облачными развертываниями.
Читайте в нашей новой статье о том, что выбрать из этих и других способов геораспределенной мультирегиональной интеграции кластеров Kafka.
Узнайте больше про администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
Источники

