 1079
1079 
Содержание
Завершая цикл статей про мультирегиональную репликацию кластеров Apache Kafka, сегодня поговорим про стратегии развертывания топологий, предлагаемых компанией Confluent. Принципы архитектуры, сравнение, сценарии, критерии выбора.
Критерии выбора топологии репликации кластера Apache Kafka
Для повышения надежности и производительность потоковой обработки данных с использованием Apache Kafka кластера этой платформы рекомендуется располагать в разных географических регионах. При этом необходимо обеспечить синхронность данных между ними, что называется мультирегиональной георепликацией по нескольким центрам обработки данных (ЦОД). Для репликации в нескольких регионах кластер Kafka может иметь следующую топологию:
- растянутые кластеры (stretched clusters), когда один кластер Kafka устанавливается в нескольких ЦОД. При этом используется протокол синхронной репликации Kafka. В этом случае сохраняются смещения потребителей, а также обеспечивается быстрое аварийное восстановление и автоматическое переключение клиента при сбое без дополнительного кода.
- связанные кластеры (connected clusters) с асинхронной репликацией в разных географических регионах. Вместо одного кластера их несколько, и они управляются независимо.
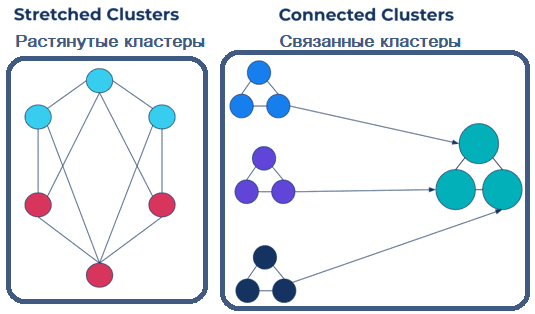
О том, что представляют собой эти топологии и как они реализуются с помощью решений Confluent, мы писали здесь.
Прежде чем сравнивать возможности и ограничения этих топологий, еще раз напомним про основную причину их появления – повышение надежности системы, ее отказоустойчивости и доступности. Для геораспределенной репликации Kafka это означает, что при аварии в основном ЦОД (primary region) все клиенты быстро переключаются на дополнительный (secondary region). При этом необходимо гарантировать, что потребители смогут продолжить работу с того места, на котором они остановились, не пропуская сообщений. Для Kafka это означает работы по согласованию смещения, чтобы приложения-потребители могли переключиться на потребление данных из других брокеров с минимальным временем простоя и дублированием сообщений. Также при аварийном переключении необходимо сократить потерю данных.
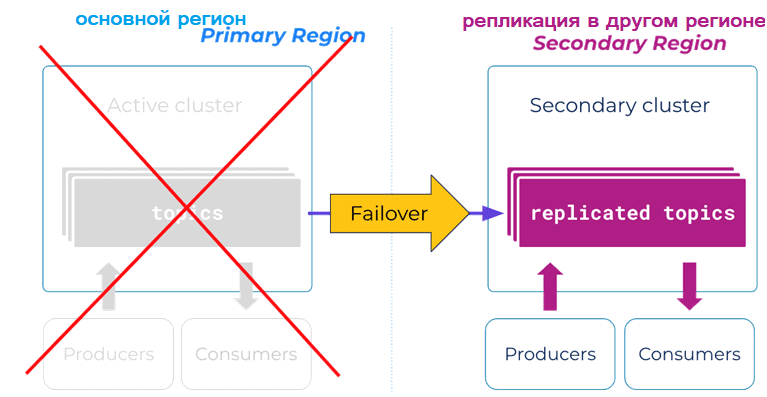
После восстановления основного кластера клиентам снова необходимо переключиться на него. Это означает, что между кластерами должен быть механизм согласования, чтобы публикация и потребление данных выполнялись корректно. Однако, на практике чаще всего исходный secondary-кластер становится новым primary, и наоборот, исходный primary-кластер становится новым secondary-кластером — по крайней мере, до следующей аварии. Чтобы оценить надежность такой системы в числовом выражении, можно использовать классические SRE-метрики (System Reliability Engineering):
- Целевая точка восстановления (RPO, Recovery Point Objective) – максимально допустимый период, данные за который могут быть потеряны после восстановления работоспособности системы;
- Целевое время восстановления (RTO, Recovery Time Objective) – период, в течение которого доступность системы должна быть восстановлена после аварии, в соответствии с согласованными с бизнесом соглашениями об уровне обслуживания (SLA, Service Level Agreement).
По сути, RPO можно рассматривать как максимальный объем данных, который может быть потерян во время аварии, а RTO — как количество времени, необходимое для возвращения к нормальному режиму работы после аварии. Эти два показателя являются ключевыми в плане обеспечения непрерывности бизнеса, поскольку они определяют, сколько времени есть на потерю данных и на восстановление.

Если рассматривать метрики RPO и RTO как критерии выбора между подходящей топологии кластера, составим рекомендательную таблицу с учетом характера репликации, сохранения смещений и толерантности к задержкам для сравнения растянутых и связанных кластеров.
|
Топология репликации |
Характер (синхронный или асинхронный) |
Сохранение смещений потребителей |
Толерантность к задержкам |
Сценарий использования |
Ограничения |
|
Растянутые кластеры |
Синхронный или асинхронный |
Да |
Нет |
Низкая задержка, нулевые RTO и RPO |
Небольшое расстояние между центрами обработки данных |
|
Связанные кластеры |
Асинхронный |
Да |
Да, при использование Confluent Server |
Большое расстояние между ЦОД (на разных контитентах) |
Высокие значения RTO и RPO |
В некоторых случаях подходящим решением будет использование не одной, а сразу обеих топологий. Например, растянутый кластер между центрами обработки данных для сценария с высокой доступностью, а связанный кластер для аварийного восстановления, совместного использования данных и агрегирования растянутого кластера. Однако, выбор подходящей топологии не единственный вопрос, который надо решить при организации мультирегиональной репликации. Также необходимо определиться со стратегией развертывания кластеров Kafka, реплицированных по разным регионам. Далее рассмотрим это более подробно.
4 стратегии мультирегионального развертывания кластеров
Одной из стратегий мультирегионального развертывания реплицированных кластеров Kafka является чтение реплики (Read Replica), когда один кластер выступает в качестве основного, а другой — в качестве резервного вторичного кластера. Запись осуществляется только в primary-кластер, но потреблять данные можно как из основного, так и из вторичного кластера. Эта стратегия подходит для обеих рассмотренных топологий, гарантирует высокую доступность чтения и восстановление после сбоев. Однако, для нее характерна избыточность данных.
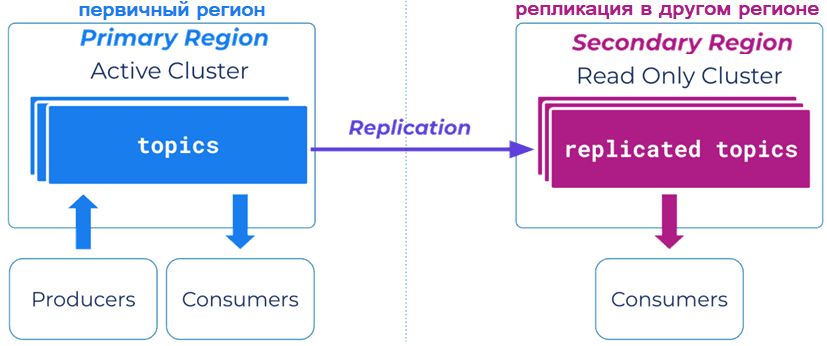
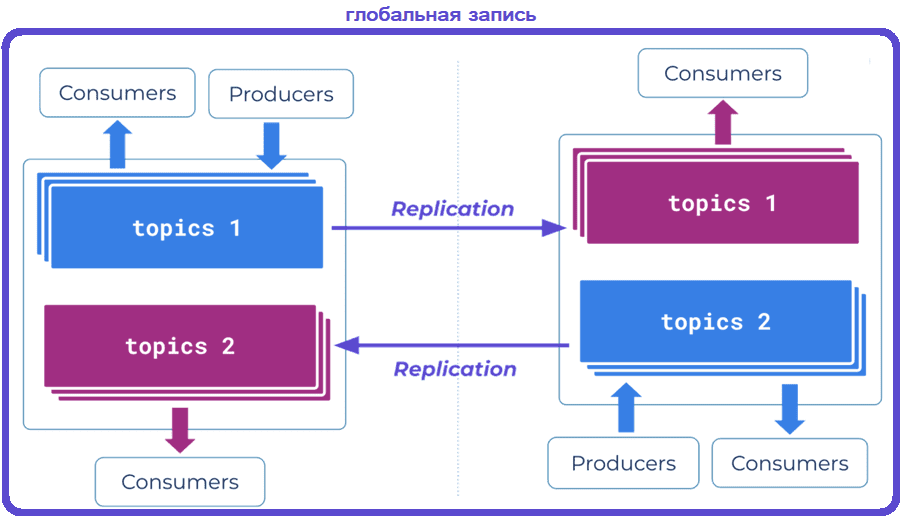
Стратегия глобальной записи (Global Write) предполагает два кластера взаимно реплицируемых кластера Kafka. В этом случае некоторые или все топики реплицируются в оба кластера и создаются в обоих из них. Это означает, что все записи сразу видны потребителям в обоих кластерах. Такая стратегия развертывания обычно используется для глобально распределенной архитектуры, где данные должны быть доступны на региональном уровне. Например, глобальный бизнес, которому необходимо, чтобы данные были доступны локально во всех центрах обработки данных по всему миру. Эта стратегия подходит для растянутых и связанных кластеров Kafka, гарантирует высокую доступность чтения и записи данных. Однако, для нее характерна избыточность данных и не очень быстрое восстановление после сбоев.
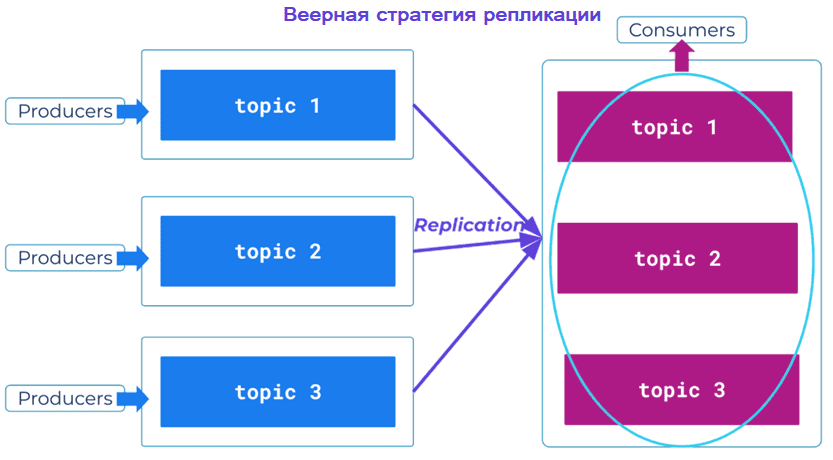
В стратегии веера или агрегация (Fan-In) несколько региональных кластеров записывают данные в один централизованный. Есть несколько способов его развертывания, в зависимости от ограничений кластеров:
- напрямую писать в один совокупный топик на централизованном кластере;
- реплицировать топики из других кластеров в централизованный, а затем агрегировать их с помощью Kafka Streams;
- использовать все реплицированные топики с шаблонами регулярного выражения.
Эта стратегия подходит для агрегации и/или аналитики больших данных из множества источников, а также Интернета вещей с периферийными кластерами. При настройке агрегации/аналитики данные записываются в один централизованный кластер, который обычно находится вдали от всех производственных, чтобы отделить аналитические операции от основных кластеров. Для IoT (Internet Of Things) периферийные кластеры запускают уменьшенные версии Kafka и записывают собранные данные обратно в основной кластер в облаке, который может использовать вычислительные ресурсы и AI/ML. Эта стратегия подходит только для топологии связанных кластеров.
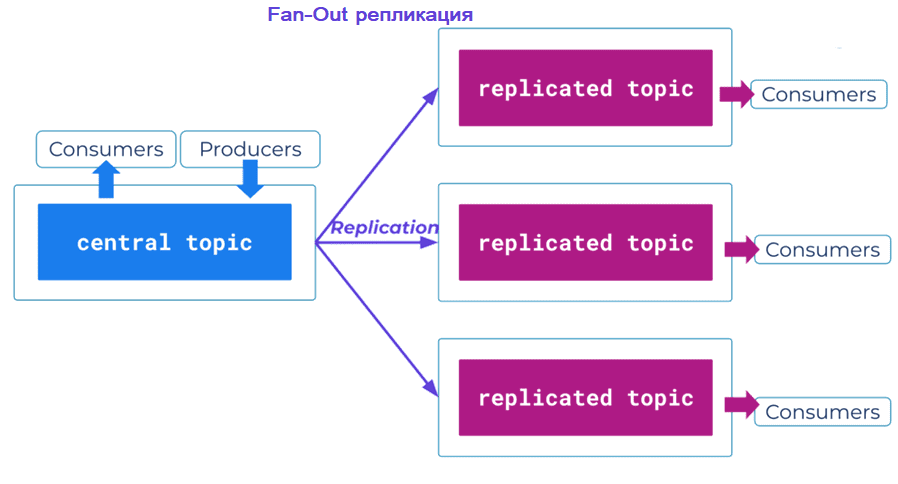
Стратегия ступица и спицы (Fan-out) противоположна стратегии веера: она предполагает не слияние, а разветвление кластеров Kafka. В этой стратегии один кластер записывает данные в несколько других кластеров. При таком развертывании активно создается только один кластер, а данные с него реплицируются на несколько других кластеров. Этот сценарий подходит для расширенной версии чтения реплик и Интернета вещей: когда одного пассивного кластера недостаточно, данные должны иметь локализацию потребления, но публикуются только из одного места. Например, в IoT-системах устройства получают обновления из централизованного кластера, куда записываются все данные. Это также можно объединить с шаблоном реплики чтения для формирования цепочки кластеров, где в середине находится центральный кластер, используемый для обмена данными между различными командами или направлениями бизнеса. Как и стратегия веера, этот вариант развертывания подходит только для топологии связанных кластеров.
Таким образом, выбор стратегии развертывания в нескольких регионах зависит от множества факторов, включая расходы, бизнес-требования, сценарии использования и нормативные ограничения. Также следует учитывать требования к отказоустойчивости и защите данных в нескольких кластерах Kafka, сформулировать которые помогут ответы на следующие вопросы:
- Нужно ли транслировать смещения потребителей?
- Какова потеря данных при сбое одного из кластеров?
- Насколько легко будет продолжить работу с клиентскими приложениями с того места остановки?
- Позволит ли развертывание защитить кластер от большинства угроз?
- Нужна ли специальная сетевая конфигурация для обеспечения безопасности?
- Как быть со списками управления доступом для всех клиентов в случае нескольких кластеров?
Помимо ответов на эти вопросы при выборе стратегии развертывания мультирегиональной репликации кластеров Kafka также следует учитывать их поддержку топологии, сценарии использования, возможности и ограничения. Представим это как критерии выбора в табличной форме.
|
Стратегия развертывания |
Топология репликации |
Сценарий использования |
|
Чтение реплики (Read Replica) |
· Растянутые кластеры · Связанные кластеры |
Высокая доступность чтения и восстановления после сбоев. Избыточность данных |
|
Глобальная запись (Global Write) |
Высокая доступность чтения и записи данных. Избыточность данных и не очень быстрое восстановление после сбоев |
|
|
Веер (Fan-In) |
Связанные кластеры |
Агрегация и/или аналитика больших данных из множества источников, системы Интернета вещей с периферийными кластерами |
|
Ступица (Fan-Out) |
Одного пассивного кластера недостаточно, данные должны иметь локализацию потребления, но публикуются только из одного места |
В заключение еще раз подчеркнем, что выбор стратегии развертывания зависит от многих факторов, но отказоустойчивость и безопасность являются главными критериями мультирегиональной репликации кластеров Apache Kafka.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
[elementor-template id=»13619″]
Источники

