 1365
1365 
Сегодня я покажу на практическом примере, как реализовать потоковый захват изменения данных из таблицы PostgreSQL и их репликацию в Apache Kafka с помощью Debezium. Создаем и настраиваем свой коннектор на платформе Upstash.
Постановка задачи
Паттерн захвата измененных данных (CDC, Change Data Capture) является одним из самых распространенных в инженерии данных. Например, нужно отслеживать вставки и изменения записей в одной или нескольких таблицах реляционной БД. Как это реализовать в объектно-реляционной СУБД PostgreSQL и основанной на ней Greenplum с механизмами массово-параллельной загрузки, я недавно писала здесь.
Начиная с версии 9.4, в PostgreSQL есть механизм логической репликации на основе журнала упреждающей записи (WAL, Write Ahead Log) для взаимодействия по подписке. CDC предполагает, что приложение-подписчик выбирает PostgreSQL в качестве издателя и подписывается на ее журнал. Этот лог хранится на диске, и в нем сохраняются все события изменения данных, т.е. SQL-запросы INSERT, UPDATE и DELETE.
Если это нужно отслеживать выполнения этих запросов в реальном времени, можно публиковать события изменения данных в топик Kafka, чтобы приложение-потребитель реагировало на эти события. Для такой потоковой репликации изменений необходим брокер сообщений с высокой пропускной способностью. Таким брокером сообщений с возможностью длительного хранения данных является Apache Kafka. Использование Kafka снижает нагрузку на WAL-журнал и не нагружает СУБД. Для отслеживания изменений в базе данных, который записывает все изменения на уровне строк в таблице как упорядоченный поток событий, отправляя их в Kafka, используются сервис Debezium на основе Kafka Connect. Библиотека коннекторов Debezium создает сообщения в формате, независимом от исходной СУБД, позволяя работать с различными потребителями событий. Впрочем, этот коннектор — не единственный, который позволяет передать данные из PostgreSQL в Kafka. О JDBC-альтернативе я рассказываю в этой статье.
В качестве практического примера рассмотрим интернет-магазин, о проектировании и реализации которого я писала в блоге нашей Школы прикладного бизнес-анализа здесь и здесь. Механизм аутентификации реализован с помощью записи JWT-токена в cookie-файл заголовка HTTP-запроса, который клиент отправляет на сервер. Этот токен с ограниченным сроком действия выдается только пользователям с ролью менеджер при входе в систему, чтобы они могли выполнять операции изменения товаров и поставщиков. Он сохраняется в таблице jwts базы данных PostgreSQL, развернутой в облачной платформе Neon.
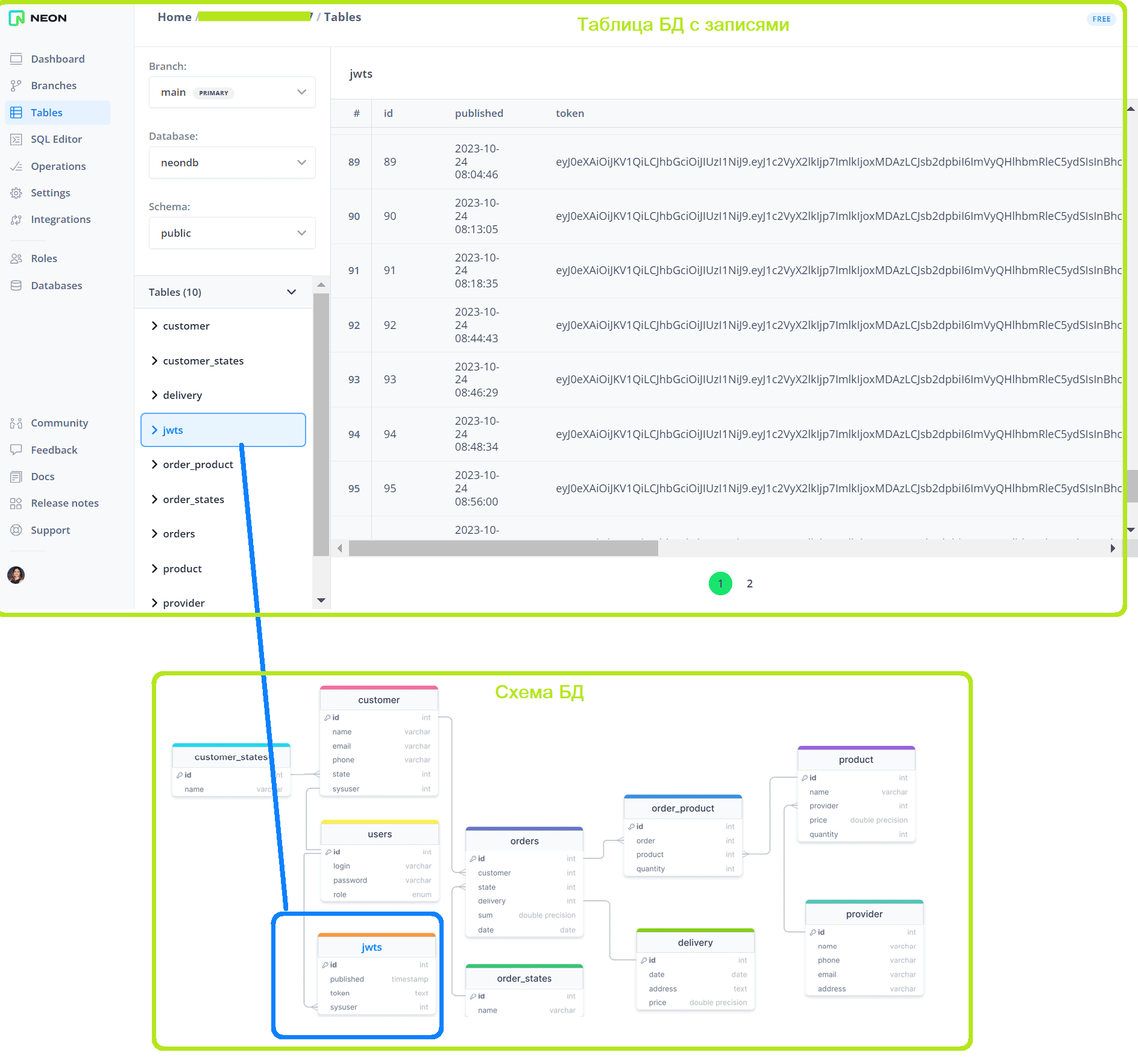
Таким образом, добавление в таблицу jwts свидетельствует о входе нового пользователя. Чтобы организовать оповещение об этом событии в режиме реального времени, подпишем на изменения в таблице jwts приложение-потребитель, которое будет отправлять оповещения в телеграмм. Приложение-потребитель считывает данные из топика Kafka, куда их отправляет коннектор Debezium. Далее рассмотрим, как реализовать этот коннектор на платформе Upstash, где развернут мой экземпляр Apache Kafka.
Потоковая передача из Kafka в PostgreSQL: реализация коннектора
Как уже было отмечено ранее, чтобы реализовать интеграцию PostgreSQL с Apache Kafka, надо не только создать коннектор Debezium, но и внести изменения в настройки самой БД. В частности, включить логическую репликацию. В Neon, где развернута моя БД, это делается в GUI.
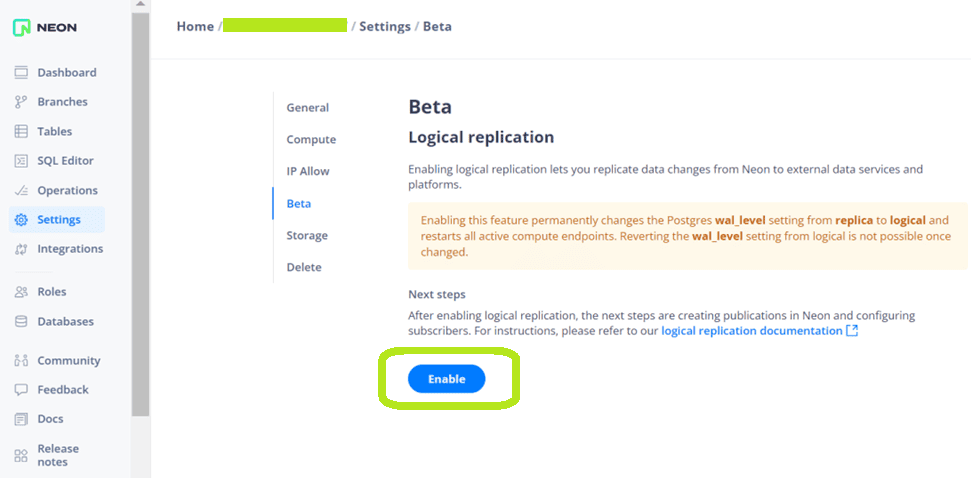 Включение логической репликации в PostgreSQL
Включение логической репликации в PostgreSQL
Далее необходимо создать публикацию для нужной таблицы с помощью команды CREATE PUBLICATION. В моем случае это будет:
CREATE PUBLICATION jwts_publication FOR TABLE jwts;
Эта команда создает публикацию с именем jwts_publication, которая будет включать все изменения таблицы jwts в потоке репликации.
Также нужно создать выделенный слот репликации, который нужен для коннектора Debezium. Для использования этого слота репликации следует настроить только один источник. Например, следующая команда создает слот репликации с именем debezium:
SELECT pg_create_logical_replication_slot('debezium', 'pgoutput');
Помимо слота репликации также указывается плагин логического декодера pgoutput, встроенный в PostgreSQL.
Выполнив необходимые действия на стороне базы данных, можно переходить к созданию коннектора Debezium. Вообще платформа Upstash позволяет создавать различные коннекторы, чтобы связать Kafka со множеством внешних систем как в качестве источников, так и приемников данных.
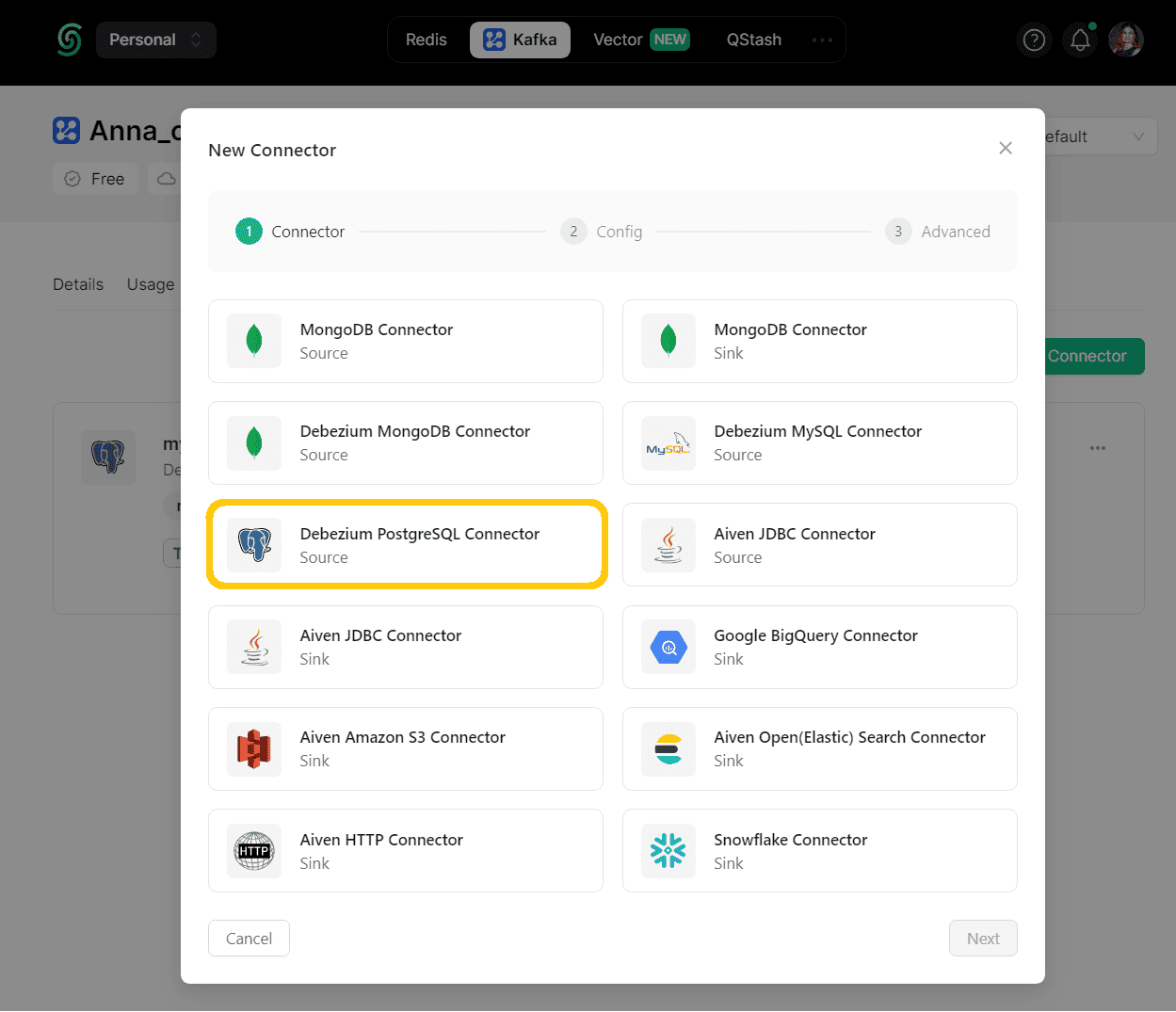
Для PostgreSQL есть только source-коннектор, т.е. PostgreSQL выступает в качестве источника данных, а Debezium фактически играет роль приложения-продюсера, публикуя в Kafka события изменения.
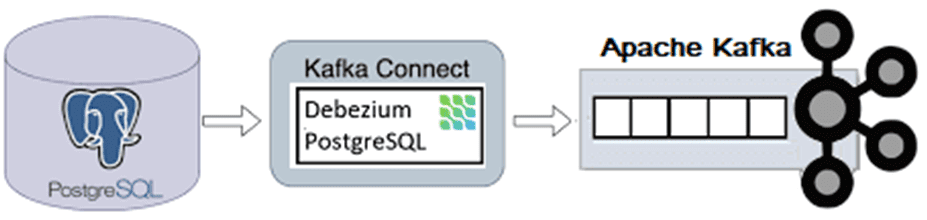
При создании коннектора надо внести учетные данные подключения к источнику, т.е. PostgreSQL.
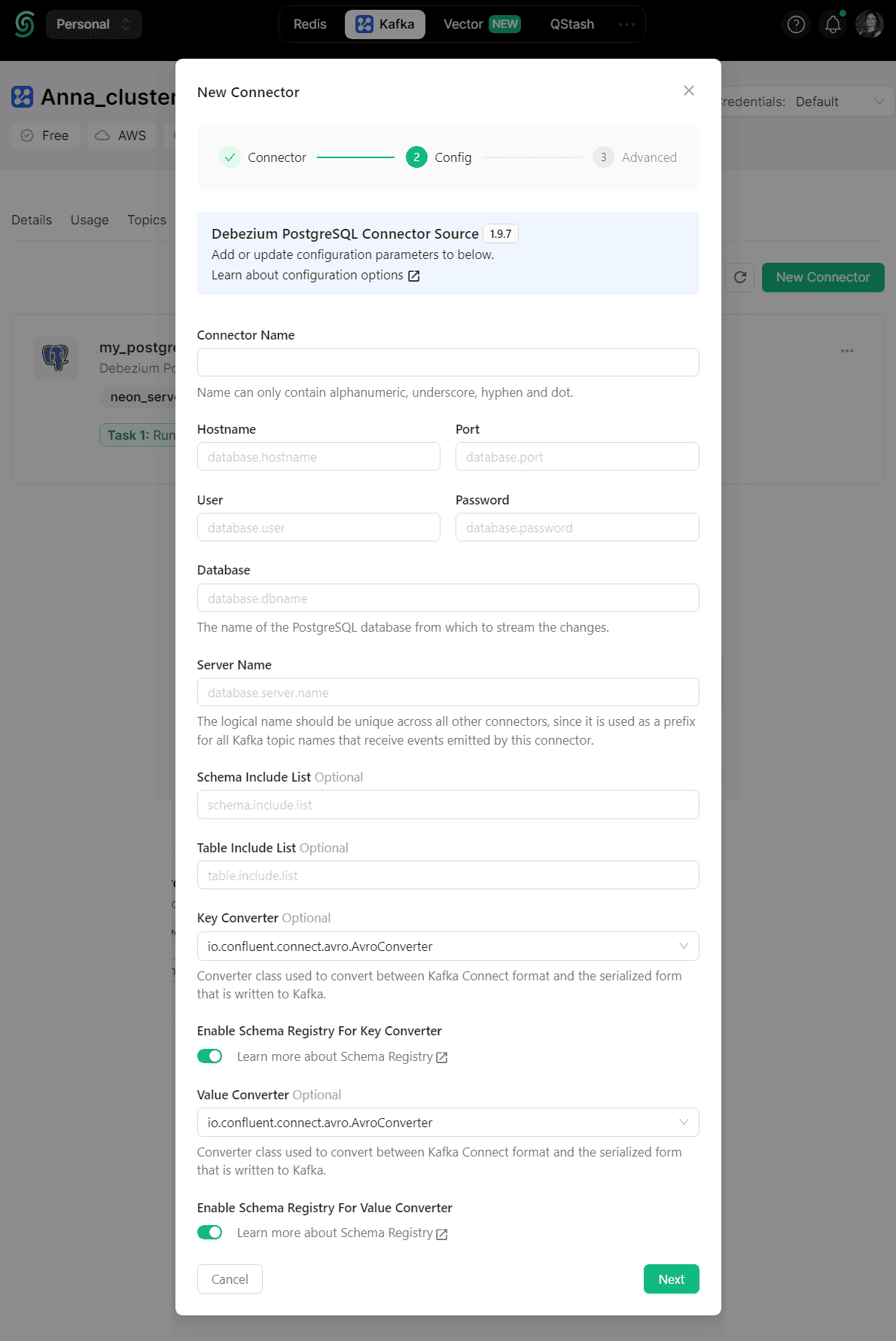
После создания коннектора можно и нужно вручную поправить его конфигурации:
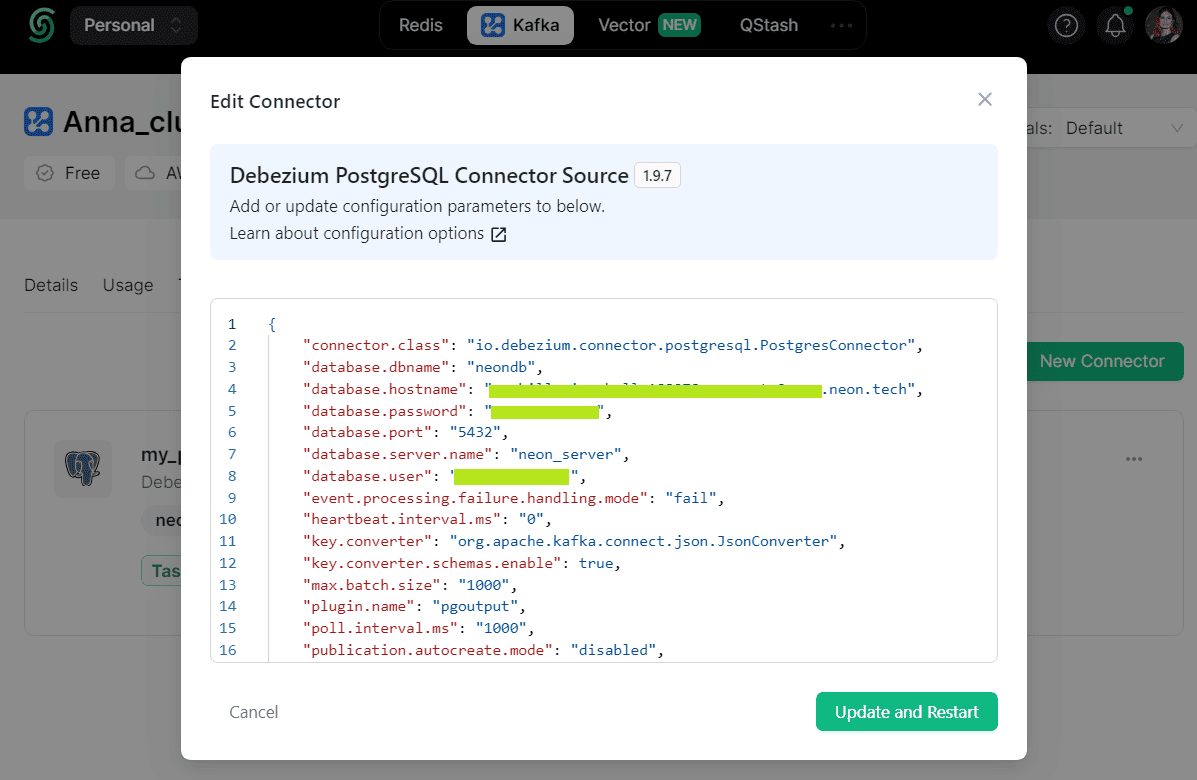
Например, я задала следующую конфигурацию:
{
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.dbname": "my-db",
"database.hostname": "my-pg-host",
"database.password": "my-passord",
"database.port": "5432",
"database.server.name": "neon_server",
"database.user": "my-username",
"event.processing.failure.handling.mode": "fail",
"heartbeat.interval.ms": "0",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": true,
"max.batch.size": "1000",
"plugin.name": "pgoutput",
"poll.interval.ms": "1000",
"publication.autocreate.mode": "disabled",
"publication.name": "jwts_publication",
"schema.include.list": "public",
"slot.name": "debezium",
"table.include.list": "public.jwts",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": true
}
В этой конфигурации помимо учетных данных подключения к источнику, очень важно настроить следующие ключи:
- plugin.name, установленный в значение pgoutput, поскольку используется именно этот плагин логической репликации PostgreSQL;
- poll.interval.ms – время в миллисекундах, которое Debezium будет ждать между попытками извлечения новых изменений из базы данных;
- publication.autocreate.mode, установленный в значение disabled, отключает автоматическое создание публикации для определения групп таблиц для логической репликации. В конфигурации коннектора я это отключила, поскольку заранее создала на стороне самой базы данных.
- publication.name — имя публикации, которую Debezium будет использовать для отслеживания изменений. У меня это jwts_publication, что я ранее создала на стороне PostgreSQL с помощью SQL-запроса.
- schema.include.list — список схем базы данных, который Debezium будет отслеживать;
- slot.name — имя ранее созданного слота репликации, который Debezium будет использовать;
- table.include.list — список таблиц, который Debezium будет отслеживать. Поскольку я хочу отслеживать изменения только в одной таблице jwts, а не во всей БД, это важно указать. При указании надо обязательно задать схему базы данных, т.е. в моем случае прописать public.jwts, т.к. слушается только таблица jwts из схемы public.
Для кодирования/декодирования ключей и значений записи я выбрала человекочитаемый формат JSON, указав значение org.apache.kafka.connect.json.JsonConverter для параметров key.converter и value.converter.
Если все данные указаны верно, коннектор будет создан и по прошествии некоторого времени запущен. Получаемые из PostgreSQL события изменения данных в таблице jwts будут публиковаться в топик Kafka neon_server.public.jwts с одним разделом. Этот топик создается автоматически.
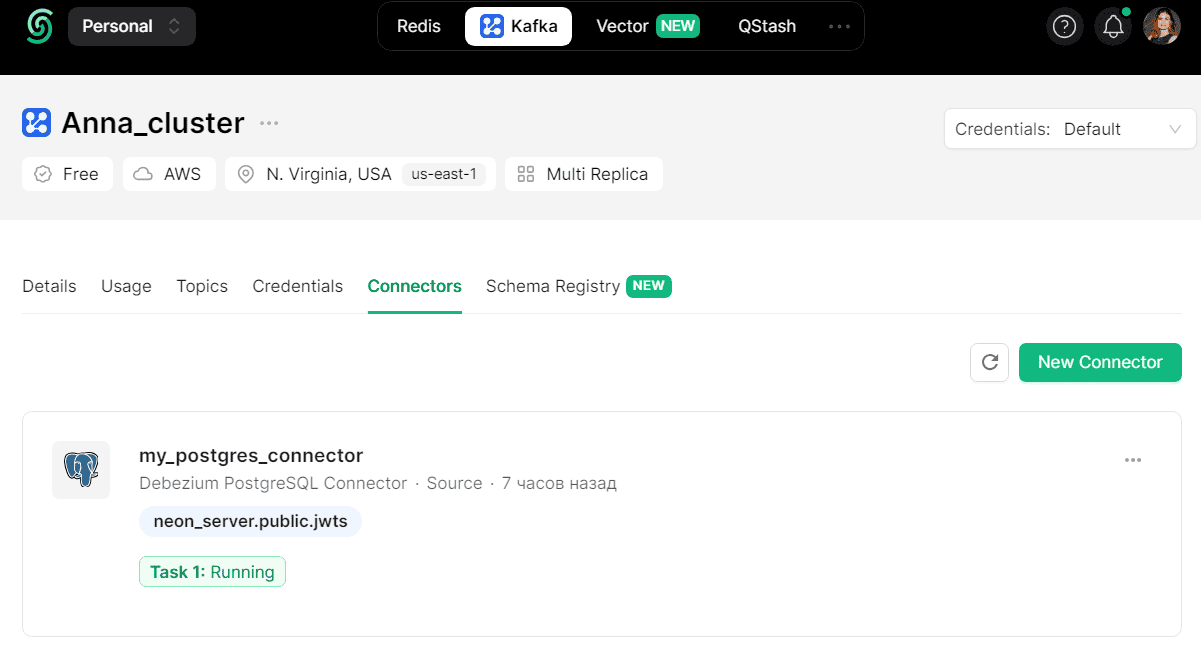
Стоит подчеркнуть, что при использовании плагина pgoutput важно выбрать подходящее значение для publication.autocreate.mode. Если оставить значение по умолчанию по умолчанию all_tables, нужно убедиться, что публикация создается заранее для конкретных таблиц, изменения в которых надо отслеживать. Если публикация не найдена, коннектор попытается создать ее. Именно поэтому, когда я не отключила эту автопубликацию и запустила созданный коннектор с такой конфигурацией, у меня в Kafka создалось множество топиков, куда началась репликация записей из всех таблиц БД. Пришлось остановить работу коннектора и изменить конфигурацию на disabled. В этом случае коннектор не будет сам создавать публикацию. А если при запуске не обнаружит ее, то выдаст исключение и остановится. Если задать параметру publication.autocreate.mode значение filtered, то коннектор сам создаст новую публикацию для всех таблиц, соответствующих текущей конфигурации фильтра, если не найдет заранее созданных.
После запуска коннектора можно проверить его работу. Например, пользователь с ролью менеджер входит в интернет-магазин, и ему выдается JWT-токен, который сохраняется в таблице jwts. При этом выполняется SQL-запрос:
INSERT INTO jwts (id, published, token, sysuser) values (203, '2024-02-02 16:53:14', 'eyJ0aklsdjlakjdkKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjp7ImlkIjoxMDAzLCJsb2dpbiI6ImVyQHlhbmRleC5ydSIsInBhc3N3b3JkIjoiMSIsInJvbGUiOiJtYW5hZ2VyIn0sImV4cCI6MTY5NzY5ODgyMn0.4YQIRG6luW94M_zdnXTMp40rWeqhKoH9FMyuR6Bctps',1003)
Эти изменения почти сразу отобразятся в топике Apache Kafka под названием neon_server.public.jwts.
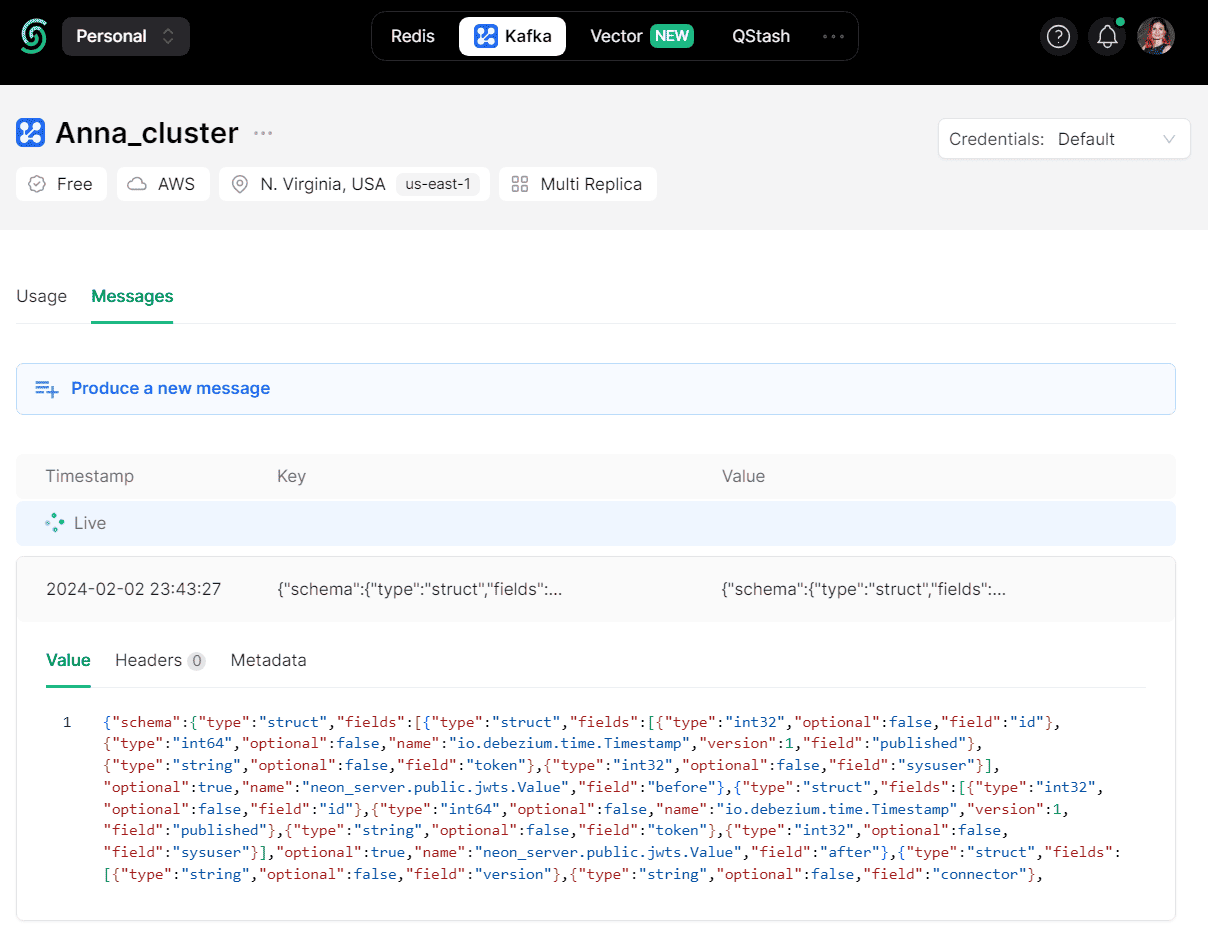
В Kafka опубликовано следующее сообщение:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "int64",
"optional": false,
"name": "io.debezium.time.Timestamp",
"version": 1,
"field": "published"
},
{
"type": "string",
"optional": false,
"field": "token"
},
{
"type": "int32",
"optional": false,
"field": "sysuser"
}
],
"optional": true,
"name": "neon_server.public.jwts.Value",
"field": "before"
},
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "int64",
"optional": false,
"name": "io.debezium.time.Timestamp",
"version": 1,
"field": "published"
},
{
"type": "string",
"optional": false,
"field": "token"
},
{
"type": "int32",
"optional": false,
"field": "sysuser"
}
],
"optional": true,
"name": "neon_server.public.jwts.Value",
"field": "after"
},
{
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "version"
},
{
"type": "string",
"optional": false,
"field": "connector"
},
{
"type": "string",
"optional": false,
"field": "name"
},
{
"type": "int64",
"optional": false,
"field": "ts_ms"
},
{
"type": "string",
"optional": true,
"name": "io.debezium.data.Enum",
"version": 1,
"parameters": {
"allowed": "true,last,false,incremental"
},
"default": "false",
"field": "snapshot"
},
{
"type": "string",
"optional": false,
"field": "db"
},
{
"type": "string",
"optional": true,
"field": "sequence"
},
{
"type": "string",
"optional": false,
"field": "schema"
},
{
"type": "string",
"optional": false,
"field": "table"
},
{
"type": "int64",
"optional": true,
"field": "txId"
},
{
"type": "int64",
"optional": true,
"field": "lsn"
},
{
"type": "int64",
"optional": true,
"field": "xmin"
}
],
"optional": false,
"name": "io.debezium.connector.postgresql.Source",
"field": "source"
},
{
"type": "string",
"optional": false,
"field": "op"
},
{
"type": "int64",
"optional": true,
"field": "ts_ms"
},
{
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "id"
},
{
"type": "int64",
"optional": false,
"field": "total_order"
},
{
"type": "int64",
"optional": false,
"field": "data_collection_order"
}
],
"optional": true,
"field": "transaction"
}
],
"optional": false,
"name": "neon_server.public.jwts.Envelope"
},
"payload": {
"before": null,
"after": {
"id": 203,
"published": 1706892794000,
"token": "eyJ0aklsdjlakjdkKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjp7ImlkIjoxMDAzLCJsb2dpbiI6ImVyQHlhbmRleC5ydSIsInBhc3N3b3JkIjoiMSIsInJvbGUiOiJtYW5hZ2VyIn0sImV4cCI6MTY5NzY5ODgyMn0.4YQIRG6luW94M_zdnXTMp40rWeqhKoH9FMyuR6Bctps",
"sysuser": 1003
},
"source": {
"version": "1.9.7.Final",
"connector": "postgresql",
"name": "neon_server",
"ts_ms": 1706892207637,
"snapshot": "false",
"db": "neondb",
"sequence": "[\"46633416\",\"46634832\"]",
"schema": "public",
"table": "jwts",
"txId": 400402,
"lsn": 46634832,
"xmin": null
},
"op": "c",
"ts_ms": 1706892207693,
"transaction": null
}
}
Схема данных встроена в сообщение, поскольку в конфигурации коннектора указано
value.converter.schemas.enable=true
Встраивать схему данных в каждое JSON-сообщение считается не очень хорошей практикой, поскольку она постоянно повторяется и занимает место. Как избежать этого, используя реестр схем, я показываю здесь, а пока отмечу, что помимо схемы данных и системных сведений об источнике данных в объекте «source», в этом JSON-документе в поле «payload» также содержится полезная нагрузка с данными об изменении. Поскольку была вставлена новая запись, ранее не существовавшая в таблице БД, ключ «before» равен null, а «after» содержит объект с id 203.
Если выполнить в БД SQL-запрос изменения записи, например,
UPDATE jwts SET token = 'new_token' WHERE id = 203;
Это также опубликуется в Kafka в виде JSON-сообщения с полями объекта payload следующего содержания:
"before": null,
"after": {
"id": 203,
"published": 1706892794000,
"token": "new_token",
"sysuser": 1003
}
При удалении записи из таблицы БД, т.е. выполнении SQL-запроса в PostgreSQL
DELETE FROM jwts WHERE id=203;
В Kafka опубликуется JSON-сообщение с такими полями полезной нагрузки:
"before": {
"id": 203,
"published": 0,
"token": "",
"sysuser": 0
},
"after": null
Поскольку запись удаляется из БД, после выполнения события ей присваивается значение null, а до удаления обнуляются значения всех полей.
В следующей статье я расскажу про sink-коннектор для Elasticsearch и визуализацию статистики по событиям входа в интернет-магазин, материализуемых в изменениях прослушиваемой таблице JWT, на дэшборде Kibana. А о том, как организовать простую передачу данных об изменениях таблицы PostgreSQL в Kafka через обратные HTTP-вызовы, т.е. веб-хуки, читайте здесь.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
Источники

