Как выполнение нескольких stateful-операторов в одном потоке снижает стоимость обработки данных: возможности и ограничения Spark Structured Streaming. Про водяные знаки и состояния в потоковой передаче событий.
Stateful-операторы и водяные знаки в потоковой обработке данных
Благодаря распределенной обработке микропакетов в памяти Spark Structured Streaming позволяет обрабатывать огромные объемы данных очень быстро. А проект Lightspeed, о котором мы писали здесь и здесь, позволяет Spark Structured Streaming выполнять классические ETL-операции с данными в одном потоке. Начиная с версии 3.5.0, поток может содержать несколько stateful-операторов. Это позволяет записывать данные в приемник (sink) после соединения и снова считывать их в другой поток для агрегации. Выполнение соединений и агрегаций в одном потоке вместо разбиения его на несколько снижает сложность, задержку и стоимость вычислений.
Spark Structured Streaming рассматривает поток данных в реальном времени как таблицу, к которой постоянно добавляются новые данные. Для обработки таких данных разработчику надо выразить потоковые вычисления в виде стандартного пакетного запроса, как к статической таблице, а Spark сам запустит их как инкрементный запрос в неограниченной входной таблице. Механизм фреймворка считывает последние доступные данные из источника потоковых данных, постепенно обрабатывает их для обновления результата, а затем отбрасывает исходные данные. Сохраняются только необходимый минимум данных о промежуточном состоянии, нужные для обновления результата, например, промежуточные значения. При этом Spark сам отвечает за обновление таблицы результатов при появлении новых данных, избавляя разработчика следить за этим.
Все функции или операторы в Spark Structured Streaming можно разделить на две категории:
- без сохранения состояния (stateless), которые выполняют локальные операции только над данными в пределах текущего микропакета. Им не нужно ничего знать о данных из предыдущих микропакетов. Например, фильтрация записей для сохранения строк со значениями одного из столбцов больше 10 не сохраняет состояние, поскольку не требует дополнительных данных, кроме тех, над которыми ведется работа в текущий момент.
- с сохранением состояния (stateful), которые выполняют операции с использованием дополнительных данных помимо тех, что уже есть в текущем микропакете. Например, нужно вычислить скользящее среднее или количество запросов, поступивших из разных городов в течение 5-минут.
Итак, чтобы вычислить количество запросов, поступивших из разных городов в течение 5-минут, в Spark-приложении с использованием пакета Structured Streaming надо определить 5-минутное окно и сохранить текущий счетчик для каждого города, т.е. ключа агрегации для записей в течение этого окна. Это делается независимо от количества микропакетов, по которым распределены записи, поступившие в течение анализируемого окна. Эти сохраненные данные называются состоянием (state) и их обрабатывают stateful-операторы. Самыми распространенными операторами с отслеживанием состояния являются агрегации, соединения и устранение дублей (дедупликация).
Все stateful-операторы в Spark Structured Streaming требуют указания водяного знака (watermark). Это понятие впервые введено в версии фреймворка 2.1, чтобы автоматически отслеживать текущее время события в данных и соответственно очищать устаревшее состояние. Это необходимо из-за задержек в поступлении данных, которые могут возникнуть по причине перегрузки сети и/или проблем на стороне источника данных.
Разработчик может определить водяной знак запроса, указав столбец отметки времени события и пороговое значение ожидаемой задержки данных. Для определенного окна, заканчивающегося в определенный момент времени, движок будет поддерживать состояние и позволять запоздавшим данным обновлять состояние до тех пор, пока не будет превышен допустимый порог разницы между разными отметками времени. Таким образом, данные с опозданием в пределах допустимого порога будут агрегированы, а состояния с превышением этого лимита будут удаляться.
Водяной знак дает контроль над допустимой задержкой данных и сроком хранения состояния. Например, в наборе данных каждая запись содержит отметку времени события, которая учитывается для агрегации в пределах 5-минутного окна. Некоторые записи могут приходить не по порядку, например, запись с отметкой времени 12:04 поступила после обработки записей с отметкой времени 12:11. Хранить данные о состоянии бесконечно нельзя, т.к. это заполнит память и приведет к снижению производительности Spark-приложения. Чтобы избежать этого, в Structured Streaming есть метод withWatermark(), который позволяет указать допустимый период задержки данных. Например, данные будут приниматься с опозданием до 5 минут, в зависимости от столбца отметки времени event_timestamp:
.withWatermark("event_timestamp", "5 minutes")
Возможности и ограничения применения watermark в stateful-операторах Spark Structured Streaming с помощью
Как уже было отмечено, возможность объединения нескольких stateful-операторов, появившаяся в Spark 3.5, снижает сложность, задержку и стоимость обработки потоковых данных. Раньше каждому оператору с отслеживанием состояния требовался собственный поток. Поэтому приходилось делать поток для соединения и второй поток для оконной агрегации, которая использовала выходные данные первого потока в качестве входных данных. Даже если оба потока выполнялись в одном и том же кластере Spark, у каждого из них были свои собственные накладные расходы, такие как смещение контрольных точек и логи фиксации, а также метрики отслеживания для построения графиков в пользовательском интерфейсе фреймворка. Взаимодействие между потоками выглядело так:
- первый поток считывает исходные данные;
- первый поток объединяет исходные данные;
- первый поток записывает в приемник на внешнем хранилище;
- второй поток считывает объединенные данные;
- второй поток выполняет оконную агрегацию;
- второй поток записывает результат в другой приемник.
На диаграмме последовательности это выглядит так:
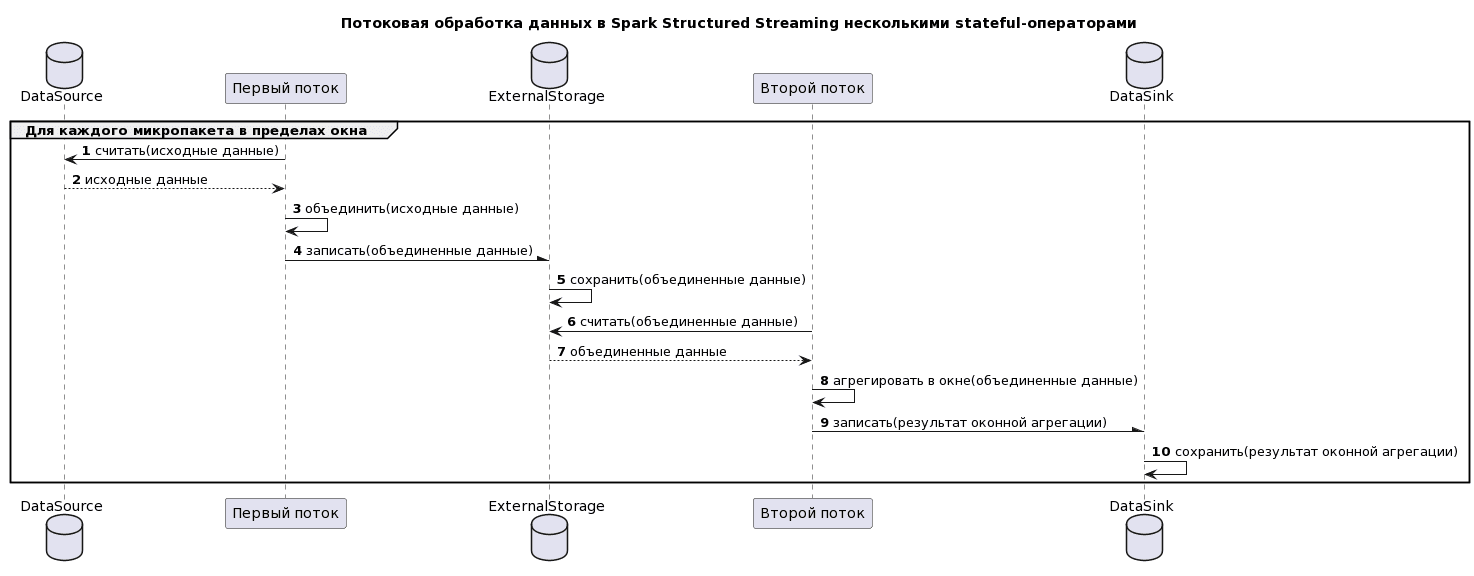
Эта диаграмма создана с помощью PlantUML-скрипта:
@startuml title Потоковая обработка данных в Spark Structured Streaming несколькими stateful-операторами autonumber group Для каждого микропакета в пределах окна Database DataSource participant "Первый поток" as FSt Database ExternalStorage participant "Второй поток" as SSt Database DataSink FSt -> DataSource: считать(исходные данные) DataSource -->FSt: исходные данные FSt -> FSt: объединить(исходные данные) FSt -\ ExternalStorage: записать(объединенные данные) ExternalStorage -> ExternalStorage: сохранить(объединенные данные) SSt -> ExternalStorage: считать(объединенные данные) ExternalStorage --> SSt: объединенные данные SSt ->SSt: агрегировать в окне(объединенные данные) SSt -\ DataSink: записать(результат оконной агрегации) DataSink -> DataSink: сохранить(результат оконной агрегации) end @enduml
Таким образом, при работе с несколькими stateful-операторами оба потока приходилось отслеживать, и управлять зависимостью между ними при каждом логическом изменении любого из потоков. В Spark 3.5.x можно комбинировать несколько stateful-операторов, поэтому соединение и оконная агрегация могут находиться в одном потоке. Последовательность обработки становится намного короче:
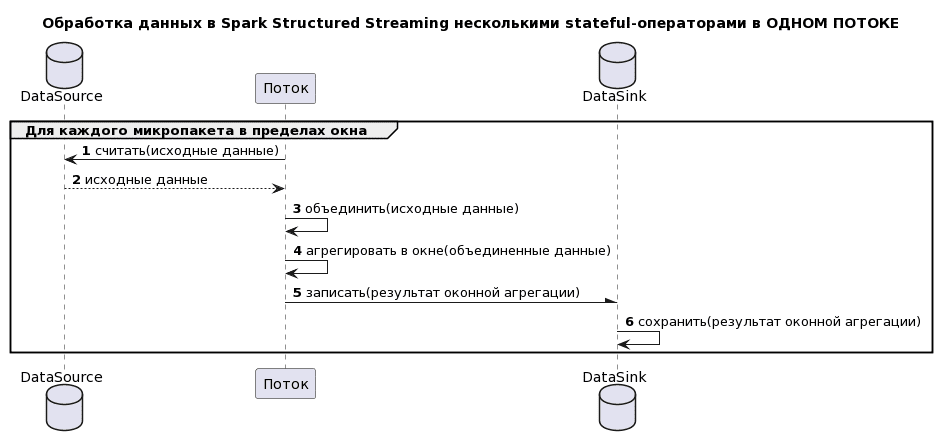
Эта диаграмма создана с помощью PlantUML-скрипта:
@startuml title Обработка данных в Spark Structured Streaming несколькими stateful-операторами в ОДНОМ ПОТОКЕ autonumber group Для каждого микропакета в пределах окна Database DataSource participant "Поток" as St Database DataSink St -> DataSource: считать(исходные данные) DataSource -->St: исходные данные St -> St: объединить(исходные данные) St ->St: агрегировать в окне(объединенные данные) St -\ DataSink: записать(результат оконной агрегации) DataSink -> DataSink: сохранить(результат оконной агрегации) end @enduml
Сложность разработки снижается, поскольку нужно отслеживать только один поток, и нет зависимостей, которыми требуется управлять. Кроме того, сокращается объем данных, т.к. сохраняется только один набор данных. Задержка уменьшается, поскольку исключается запись промежуточного набора данных после объединения и его чтение перед оконной агрегацией. Помимо исключения этих операций сокращаются накладные расходы на потоковую передачу данных, снижается объем вычислений и затраты на хранение. В результате потоковая обработка данных становится дешевле.
Spark Structured Streaming вычисляет и сохраняет отметку времени водяного знака в конце каждого микропакета, вычитая из последней полученной временной метки события временной интервал, указанный в параметрах метода withWatermark(). В начале каждого микропакета отметки времени событий входящих записей сравниваются с метками водяных знаков данных текущего состояния. Входные записи и состояние с отметками времени, которые предшествуют значениям водяных знаков, удаляются. Этот механизм позволяет Spark Structured Streaming правильно обрабатывать просроченные записи и состояние независимо от количества stateful-операторов в одном потоке.
В заключение отметим, что при использовании нескольких stateful-операторов в одном потоке необходимо помнить, что это допустимо с режимом вывода Append – добавление данных, при котором в приемник будут выводиться только новые строки, добавленные в таблицу результатов с момента последнего триггера. Это поддерживается только для тех запросов, где строки, добавленные в таблицу результатов, никогда не изменяются. Append-режим гарантирует, что каждая строка будет выведена только один раз при условии отказоустойчивого приемника. А вот режимы вывода Complete (полный), когда вся таблица результатов выводятся в приемник после каждого триггера и Update (обновление), когда в приемник выводятся только те строки из таблицы результатов, которые были обновлены с момента последнего триггера, использовать нельзя. Это ограничение не снимает даже поддержка режимов Complete и Update в целевом приемнике данных. Подробнее про режимы вывода в Spark Structured Streaming мы писали здесь. Ограничение обусловлено тем, что в режиме добавления выходные данные не записываются в приемник для оконной агрегации до тех пор, пока отметка времени окончания окна не станет меньше водяного знака. Несовпадающая строка внешнего соединения не будет записана до тех пор, пока ее временная метка события не станет меньше водяного знака.
Кроме того, операторы mapGroupsWithState(), FlatMapGroupsWithState() и ApplyInPandasWithState() можно комбинировать с другими stateful-операторами, только если произвольный stateful-оператор является последним в потоке. Если нужно выполнить другие операции с отслеживанием состояния после этих операторов, надо сначала записать произвольные stateful-операции в приемник, а затем использовать другие операторы с отслеживанием состояния во втором потоке.
Наконец, при сохранении большого количества состояний для управления ими рекомендуется использовать внешнее хранилище вместо встроенного механизма по умолчанию. Например, key-value NoSQL-СУБД RocksDB может поддерживать в 100 раз больше ключей состояния, чем встроенный движок Spark Structured Streaming. Подробнее об этом читайте в нашей новой статье.
Узнайте больше про возможности Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Архитектура данных с Apache Spark
Источники

