 1150
1150 
Содержание
Как спроектировать DAG и выбрать способ обмена данными между задачами, где определить подключения и запросы к БД и что поможет избежать ада Python-зависимостей при использовании Apache AirFlow. Сегодня я расскажу своем личном опыте наступания на грабли при работе с этим оркестратором batch-процессов и уроках, которые из этого вынесла.
5 советов новичку по работе с AirFlow
Apache AirFlow – замечательный инструмент оркестрации конвейеров пакетной обработки данных с довольно низким порогом входа. Простота работы с AirFlow достигается НЕ за счет наглядного GUI, хотя графический веб-интерфейс у этого фреймворка тоже имеется, а благодаря тому, что все его компоненты – это Python-приложения. Их можно разворачивать по-разному и расширять. Поэтому каждый дата-инженер, знакомый с Python может написать код конвейера обработки данных в виде набора задач (DAG, Directed Acyclic Graph) и запускать его по расписанию с помощью планировщика Apache AirFlow.
В официальной документации и учебниках, а также различных статьях в т.ч. на нашем сайте, описано множество лучших практик использования этой платформы, которые охватывают разные сценарии и ориентированы на все категории пользователей: от начинающих до профессионалов с глубоким знанием фреймворка. Однако, при изучении AirFlow новичок сталкивается с довольно ограниченным кругом задач, которые можно решить разными способами. Но на практике начинающие специалисты выбирают самые простые методы. Но даже при их использовании можно столкнуться с рядом проблем. Некоторые из них я собрала в этой статье и дополнила советами, как избежать этих ошибок. Сначала кратко перечислю их, а затем рассмотрю каждый более подробно и с примерами. Итак, мои личные топ-5 советов новичку по работе с AirFlow:
- спроектируйте DAG как последовательность шагов аналогично цепочке действий бизнес-процесса;
- выберите подходящий способ обмена данными между задачами;
- определите периодичность и расписание запуска DAG;
- описывайте каждую задачу и запросы к БД в отдельном файле, а также отдельно описывайте подключения к внешним системам, отделяя это от кода самого DAG;
- при установке фреймворка обязательно указывайте версию и зависимости.
1. Спроектируйте DAG
Прежде всего, начнем с проектирования. Хотя AirFlow обязательно включает разработку Python-кода для задач и самого DAG, сначала необходимо определить состав этого конвейера. Поэтому мой первый совет: нарисуйте схему своего направленного ациклического графа как последовательность шагов аналогично цепочке действий в бизнес-процессе. Для большинства случаев это набор типичных ETL-операций: извлечение данных из источника, их преобразование и загрузка в приемник. Рекомендую в начало и конец этой цепочки задач ставить пустой оператор EmptyOperator подобно стартовой и финишной точке в процессной диаграмме. Этот оператор входит в комплект базовой поставки AirFlow и фактически не исполняет никакой работы: задача оценивается планировщиком, но никогда не обрабатывается исполнителем.
Небольшие затраты на оценку этого оператора планировщиком настолько малы, что их практически незаметно. Зато сам EmptyOperator улучшает семантику представления DAG и пригождается при отладке. Например, если EmptyOperator успешно выполнился, а следующая за ним задача завершилась с ошибкой (результат failure), проблема именно в ней, а не в самой установке AirFlow.
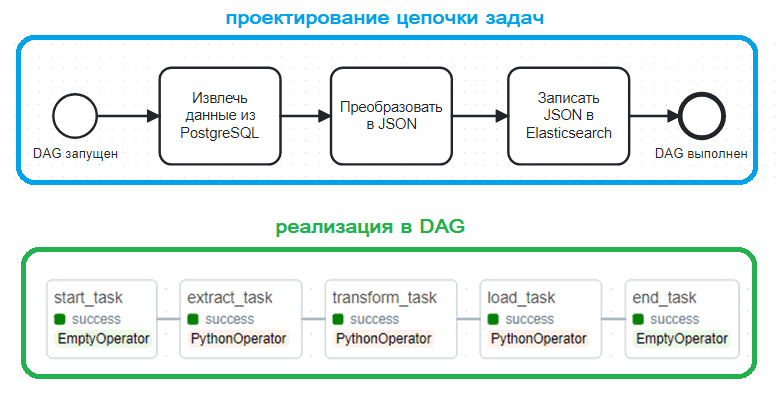
Также именно на этапе проектирования определяется порядок запуска задач: последовательно или параллельно. Это реализуется в DAG через указание названий задач, разделенных символом >>.
В частности, этот участок кода из этого примера запускает задачи последовательно:
start_task >> extract_task >> transform_task >> load_task >> send_notification_task >> end_task
А этот – параллельно:
start_task >> extract_hist_task extract_hist_task >> make_report_HIST_task make_report_HIST_task >> send_notification_task start_task >> extract_circle_task extract_circle_task >> make_report_CIRCLE_task make_report_CIRCLE_task >> send_notification_task send_notification_task >> end_task
2. Выберите способ обмена данными между задачами
Поскольку задачи связаны в цепочку для последовательного или параллельного запуска, наверняка, выходы одной из задач идут на вход другой или сразу нескольким. Реализовать обмен передачу данных между задачами в AirFlow можно двумя способами: через объекты XCom и переменные (variables).
Технология XCOM (Cross Communication) позволяет обмениваться небольшим количеством данных между задачами, сохраняя эти промежуточные данные в базе данных метаданных фреймворка. Это обусловливает главное ограничение такого способа обмена: предельный размер XCom-объекта в Apache AirFlow зависит от базы данных, которая используется для хранения метаданных. Например, для встроенной базы данных SQLite лимит равен 2 ГБ, для PostgreSQL 1 ГБ и 64 КБ для MySQL. Если передавать между задачами большие датафреймы через XCOM-объект, будут проблемы с памятью и производительность фреймворка сильно снизится.
Эти ограничения также характерны и для API TaskFlow – механизма, впервые выпущенного во 2-ой версии фреймворка. Он упрощает создание нескольких DAG, абстрагируя уровень управления задачами и зависимостями от пользователей, но полностью основан на технологии XCom. В Airflow 2.0 операция создания XCom-объекта скрыта внутри Python-оператора и полностью абстрагируется от разработчика DAG. Таким образом, знание возможностей и ограничений этой технологии позволяет сделать правильный выбор способа обмена данными между задачами. В этом примере я использую именно XCom, т.к. данных немного.
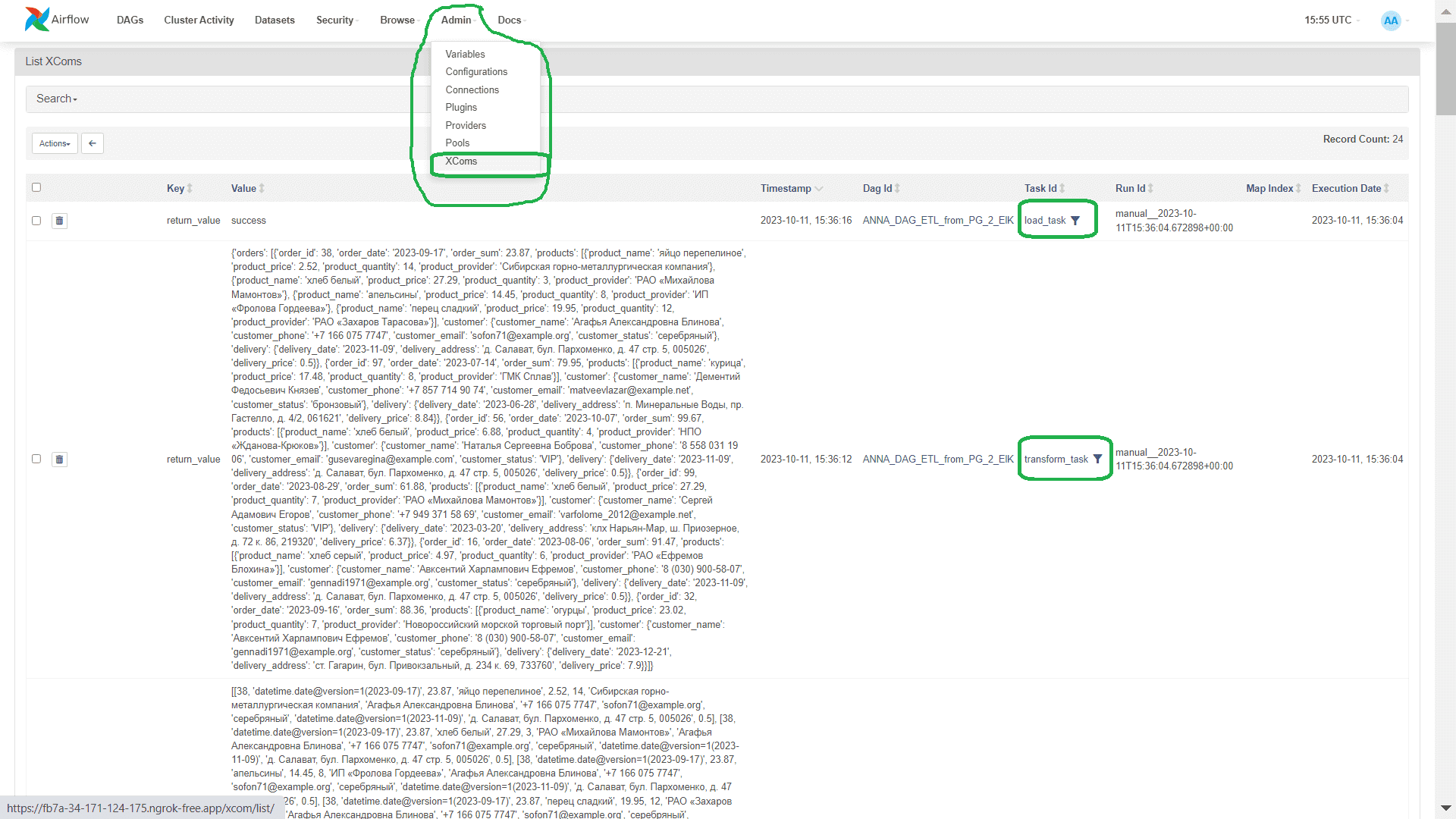
Кроме ограничения размера, стоит помнить о локальном характере XCom-объекта. Эта технология, прежде всего, предназначена для взаимодействия внутри одного DAG, поэтому организовать взаимодействие между несколькими конвейерами с ее помощью не получится. Для этого нужно использовать переменные (variables), которые являются глобальными, предназначены для общей конфигурации и существуют только во время выполнения (runtime). Подробнее об этом мы писали здесь.
Наконец, можно задействовать внешнее хранилище, записав результаты выполнения одной задачи в файл или базу данных, откуда их будет считывать другой оператор. Но это требует больше времени и увеличивает вероятность отказа за счет роста количества компонентов. Впрочем, для некоторых случаев это является единственно возможным сценарием, например, когда нужно обработать большое количество данных несколькими задачами.
3. Определитесь с периодичностью и расписанием запуска DAG
Поскольку главное назначение AirFlow – это запуск задач обработки данных по расписанию, дата-инженеру нужно выяснить, как использовать эту возможность согласно требованиям бизнеса. Например, каждую ночь в 02:00 запускать DAG с ETL-операциями для наполнения корпоративного хранилища/озера данных или проверять статус внешнего задания раз в полчаса. При этом также необходимо учитывать, как текущий конвейер зависит от других. Как это сделать, используя типовые практики проектирования, мы ранее рассматривали в этой статье.
Вообще за расписание запуска DAG в AirFlow отвечают параметры schedule_interval и start_date. При создании DAG его schedule_interval определяется явно или неявно, т.е. по умолчанию раз в день ежедневно. Также можно использовать параметр end_date, чтобы указать планировщику, когда прекратить планирование новых запусков DAG. Рекомендуется явно установить статическое значение start_date. Это также пригодится при отладке и развитии кода конвейера обработки данных, позволяя дата-инженеру сравнить версии DAG и увидеть изменения расписания его запуска. Сам DAG запускается после наступления schedule_interval. Например, если этот параметр установлен в значение @hourly, DAG будет запускаться каждый час от стартовой даты. Когда schedule_interval равен @daily, DAG будет запускаться раз в день.
Если start_date ссылается на более раннее время, чем фактическое время выполнения запуска DAG, надо включить перехват (Catchup) на уровне DAG с помощью конфигурации catchup=True. Благодаря этому планировщик запустит DAG заново для каждого интервала, который не был запущен во время триггера. Это позволит запускать рабочие процессы на основе временных интервалов и сохранять модульность цепочки задач, что особенно полезно при работе с атомарными наборами данных, которые можно разделить на определенные временные периоды. Подробнее про особенности запуска DAG в Apache Airflow по расписанию мы писали здесь. А в этой статье вы узнаете, что такое гонка данных в ETL-конвейерах, и как ее избежать.
4. Разделяй и властвуй
Модульное разделение и принцип единой ответственности вообще считается хорошей практикой в проектировании систем и разработке ПО. Для AirFlow эти принципы реализуются в виде рекомендаций не включать в код DAG следующее содержимое:
- параметры подключения к внешним системам, например, файловое хранилище, СУБД или сервис отправки сообщений;
- текст SQL-запроса, который необходимо выполнить оператору, взаимодействующему с базой данных в рамках задачи извлечения или вставки записей;
- непосредственно код самих задач.
Например, включение SQL-запроса непосредственно в Python-файл задачи DAG считается плохой практикой. Намного удобнее локально тестировать и заменять SQL-запрос, когда он описан в локальном sql-файле, который используется как параметр задачи оператора работы с базой данных. Разумеется, у AirFlow должен быть доступ к этому файлу с SQL-запросом, поэтому его надо размещаться в той же среде, где работает AirFlow. По умолчанию SQL-файлы ищутся в папке dags и ее дочерних директориях или в папке, указанной в настройках sql для Airflow.
Аналогичное отделение задачи и параметров подключения к внешним системам от самого DAG улучшает их тестирование, замену, расширение и удаление. Пример такой реализации я описывала в этом материале.
5. Управляй зависимостями
Наконец, стоит отдельно сказать про зависимости. Поскольку AirFlow основан на Python, каждый, кто писал код на этом языке программирования, сталкивался с т.н. «адом зависимостей», когда одна библиотека используется функции другой и эта совместимость нарушается со сменой версии одного из компонентов. Например, веб-сервер Apache AirFlow написан с использованием фреймворка Flask, который позволяет достаточно быстро разработать веб-приложение в архитектурном стиле REST API. Однако, из-за обновления версии AirFlow с 2.7.3 до 2.8 в январе 2024 года я, как и множество других пользователей, устанавливающие библиотеку apache-airflow с помощью общей команды менеджера пакетов pip install без указания версии, столкнулась с ошибкой TypeError: SqlAlchemySessionInterface.__init__(). Эта ошибка не позволяла запустить фреймворк из-за невозможности инициализировать базу данных метаданных.
Кроме того, новая версия Flask-Session нарушает интерфейс AirflowDatabaseSessionInterface, добавляя новые аргументы в конструктор sid_length, последовательность, схему и ключ привязки и делая все аргументы обязательными, включая ранее необязательные use_signer и константы. Поскольку я не указала версию и файл ограничений с помощью
pip install "apache-airflow==2.7.3" --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.7.3/constraints-3.8.txt"
при установке AirFlow в Google Colab команда
!pip install apache-airflow
установила мне последнюю версию, которая в итоге не заработала из-за несовпадения зависимостей. На отладку этой довольно глупой ошибки у меня ушло несколько часов. Поэтому использование общей команды установки точно нельзя назвать хорошей практикой. Обеспечить воспроизводимость установки поможет указание номера версии и ограничений с помощью опции –constraint. Эти ограничения с привязкой к версии описаны в текстовых файлах на Github. Также можно создать собственный файл ограничений и при установке указать ссылку на него.
Также рекомендую после установки проверять наличие конфликтов между зависимыми Python-пакетами с помощью команды
pip check
Чтобы установленные Python-пакеты не конфликтовали с другими библиотеками, рекомендуется разворачивать AirFlow в виртуальной среде, созданной с помощью virtualenv или venv. Такая установка изолирует установленные пакеты от других сред и предотвращает конфликты между ними. Для производственного развертывания лучше всего создать образ Docker-контейнера, который потом можно будет заменить на другой.
Разумеется, в этой статье я собрала не все грабли, на которые может наступить начинающий дата-инженер при знакомстве с AirFlow. Однако, надеюсь, что эта статья поможет вам избежать распространенных, но довольно неприятных ошибок. А освоить на практике лучшие приемы использования этого оркестратора пакетных процессов в задачах реальной дата-инженерии вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

