Одной из причин быстрой работы ClickHouse являются движки таблиц, оптимизированные на конкретные операции с данными. Сегодня рассмотрим, чем они отличаются и какой из них выбирать для разных сценариев. Движки БД ClickHouse Прежде чем разбираться с движками таблиц ClickHouse, вспомним само назначение этого термина. Движок БД или механизм хранения отвечает за...

Что необходимо реализовать в собственном процессоре, написанном на Python, чтобы запускать его в Apache NiFi. Классы и методы для настройки свойств, а также отношения и состояния жизненного цикла. Классы и методы для настройки свойств Предустановленные обработчики данных или процессоры (processor) Apache NiFi, написанные на Java, можно настроить прямо в GUI,...

Какие инфраструктурные компоненты самые дорогие в эксплуатации популярной платформы потоковой передачи сообщений и как снизить затраты на сетевые ресурсы и хранилища данных при использовании Apache Kafka. TCO для Apache Kafka: что учитывать в расчете затрат Поскольку Apache Kafka используется для интеграции информационных систем в режиме реального времени, она становится критически...
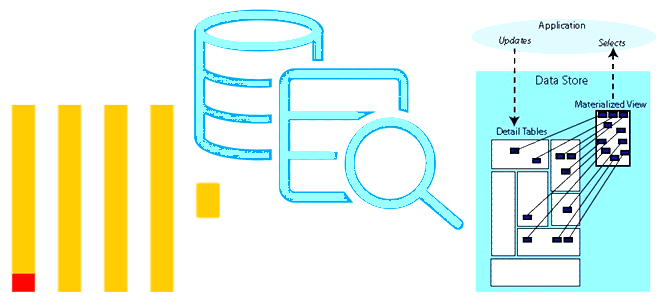
Чем материализованное представление в ClickHouse отличается от обычного, зачем нужны LIVE-представления и как их использовать. Примеры SQL-запросов с VIEW для самой популярной колоночной аналитической СУБД. Представления vs словари в ClickHouse Поскольку ClickHouse, как типовая колоночная СУБД, используется для аналитической обработки огромных объемов данных в реальном времени, вопрос ускорения вычислений для...

Продолжая разговор про рассмотренные в прошлой статье принципы взаимодействия процессов Python с Java, на которой написан Apache NiFi, сегодня разберем, как использовать это на практике. Пишем свои процессоры, используя классы FlowFileTransform и RecordTransform. Python-процессор Apache NiFi на базе FlowFileTransform Хотя Apache NiFi предоставляет более 300 процессоров для вычислительных операций и...
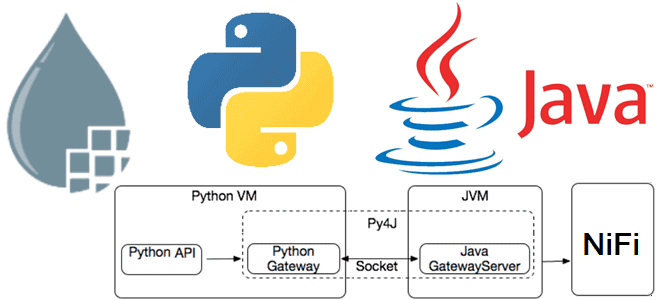
Недавно мы писали про Nifi-Python-Api —клиентский SDK, поддерживающий Python для работы с Apache NiFi. Сегодня на примере разработки процессоров более подробно разберем принципы взаимодействия процессов Python с Java, на которой написан Apache NiFi. Принципы работы Python-кода в Java-среде Apache NiFi Поскольку Apache NiFi написан на Java, именно этот язык предпочтителен...
Большинство ETL-конвейеров извлекают данные из реляционных баз в пакетном или микропакетном режиме. Читайте далее, по каким шаблонам реализовать операции извлечения. Моментальные снимки: периодическая выгрузка данных из исходных таблиц Полная периодическая выгрузка данных из одной или нескольких таблиц – это, пожалуй, самый простой метод извлечения изменяемых данных. По своей сути результат полной...
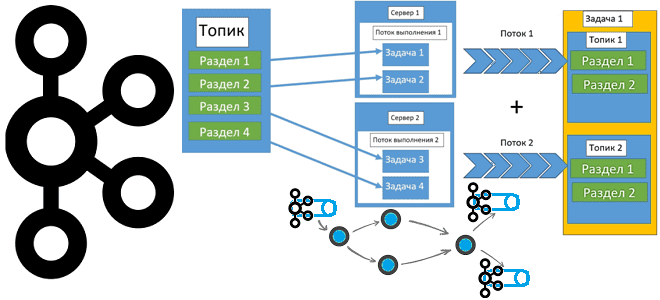
Почему нельзя просто взять и соединить потоки Kafka Streams с разным числом разделов, и как это все-таки сделать без изменения конфигурации топика. Почему нельзя просто взять и соединить потоки Kafka Streams с разным числом разделов Kafka Streams – это клиентская Java-библиотека для разработки потоковых приложений, которые работают с данными, хранящимися...
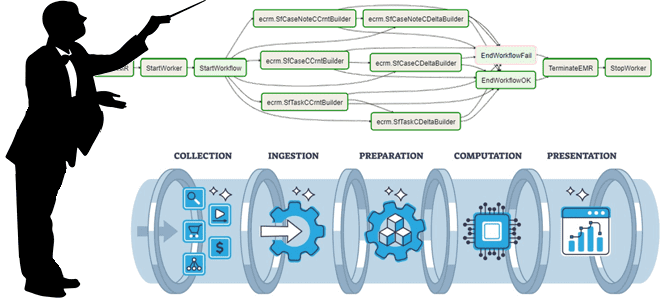
Как организовать упрощенное и продвинутое управление зависимостями между разными ETL-конвейерами, когда нужна централизованная оркестрация рабочих процессов и чем хороша стандартизация активов данных, отчетов и вычислительных процедур. Лучшие практики проектирования конвейеров для дата-инженера. Проектирование дата-конвейеров с минимальными зависимостями Для многих компаний, выстроивших процессы обработки данных в виде конвейеров, актуальна проблема управления...
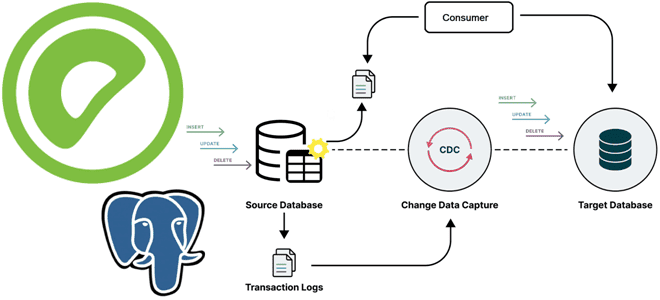
Методы отслеживания изменений в реляционных базах данных: столбцы аудиты, триггеры DDL-событий и WAL-журналы. Плюсы и минусы этих подходов, а также примеры реализации в Greenplum и PostgreSQL. 3 подхода к извлечению данных из реляционных баз Извлечение данных из реляционных баз является наиболее распространенной операцией в ETL-процессах. Поэтому при проектировании конвейеров обработки...