 1119
1119 
Продолжая разговор про межрегиональную репликацию Apache Kafka, сегодня рассмотрим 4 способа ее реализации: мультирегиональный кластер, MirrorMaker 2, Cluster Linking в Confluent Server и Confluent Replicator. Чем георепликация Kafka с MirrorMaker 2 отличается от решений Confluent и что выбирать для различных сценариев.
Мультирегиональный кластер Confluent
Геораспределенная репликация реплицирует данные по кластерам Kafka, расположенным в разных регионах. Эта межкластерная репликация отличается от внутрикластерной репликации Kafka, которая реплицирует данные внутри того же кластера Kafka. Репликация кластера Apache Kafka позволяет повысить надежность потоковой системы обработки данных и снизить задержку за счет сокращения путей передачи благодаря KIP-392, что позволяет потребителям читать данные из ближайшей реплики. Существует несколько способов межрегиональной репликации кластера Kafka по нескольким ЦОД:
- мультирегиональный кластер;
- MirrorMaker 2;
- Cluster Linking в Confluent Server;
- Confluent Replicator.
Эти способы отличаются характером (синхронный или асинхронный), возможность сохранять смещения потребителей, толерантностью к задержкам и расположением относительно кластера (внутри или снаружи).
Администратор Kafka может определять потоки данных, которые пересекают границы отдельных кластеров Kafka, ЦОД или географических регионов. Это нужно не только для геораспределенной репликации, но и для аварийного восстановления, включения краевых кластеров в центральный общий кластер, физической изоляции кластеров, например, в тестовой и производственной средах, миграция в облако или развертывание гибридного облака. Также причиной определения и настройки межкластерных потоков могут стать требования законодательства или внутренние нормы компании.
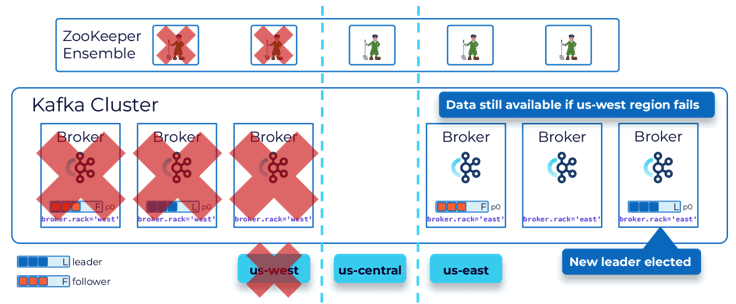
Начнем с мультирегионального кластера Confluent (MRC, MultiRegional Cluster). Он позволяет развертывать Kafka на платформе Confluent в региональных центрах обработки данных с автоматическим переключением клиентов в случае сбоя. MRC обеспечивает синхронную и асинхронную репликацию по топикам с сохранением смещения потребителей. Это решение отлично подходит для таких сценариев, где недопустима потеря данных и простой более минуты.
При проектировании многорегионального кластера обязательно нужно учитывать плоскость управления на основе консенсуса. Если будет только два кластера Kafka, также понадобится третий ЦОД для размещения узла ZooKeeper или контроллера KRaft, чтобы в случае выхода из строя одного региона иметь большинство для достижения консенсуса.
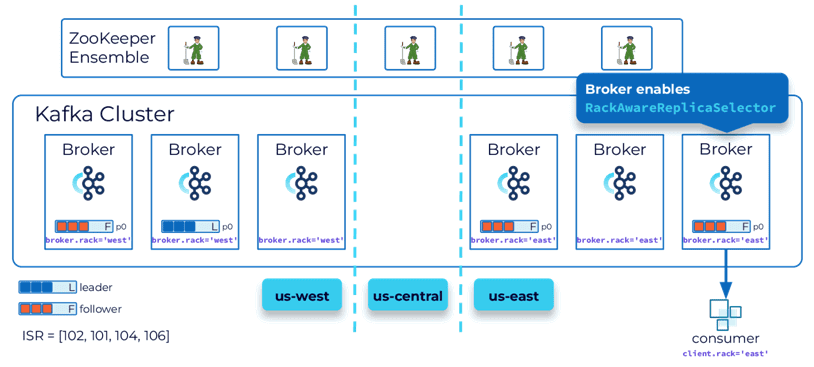
Как уже было отмечено, благодаря KIP-392 можно добиться лучшей локализации в нескольких регионах. Это улучшение позволяет приложениям-потребителям получать данные из ведомой реплики, если она находится ближе, чем ведущая. Включить эту функцию поможет настройка RackAwareReplicaSelector и конфигурация брокеров brocker.rack. Также нужно настроить конфигурацию потребителя в конфигурации client.rack.
Если для приложения низкая задержка важнее согласованности и долговечности данных, что соответствует теореме PACELС, то можно использовать наблюдателей — брокеров в удаленном кластере, не входящих в набор синхронизированных реплик (ISR, InSync Replica). Они реплицируются асинхронно, что обеспечивает меньшую задержку, когда потребители настроены на получение данных от брокеров-подписчиков. Но они лишь обеспечивают конечную согласованность. События, которые читают потребители, могут быть не самыми последними. Наблюдателя можно повысить до полноценного подписчика и он может даже стать лидером на основе политики ObserverPromotionPolicy.
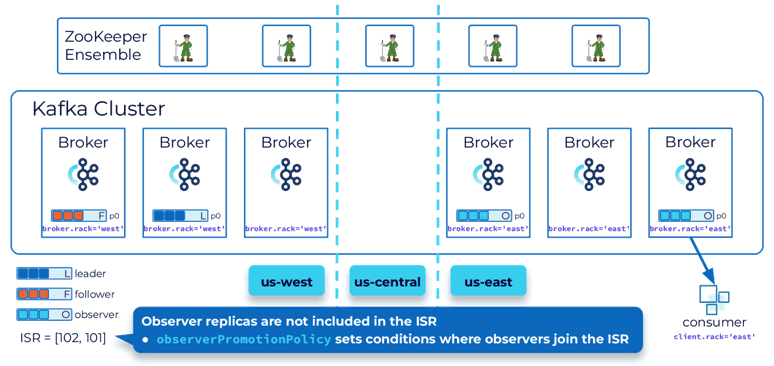
Повышение наблюдателя до подписчика и лидера может привести к возможной потере данных. Впрочем, это допустимый вариант по теореме PACELC, которая основана на CAP-теореме, но, помимо согласованности, доступности и устойчивости к разделению также включает временную задержку (L, Latency) и логическое исключение между сочетаниями этих понятий. Согласно PACELC, в случае сетевого разделения (P) в распределенной системе необходимо выбирать между доступностью (A) и согласованностью (C), как и в CAP- теореме, но в остальном (E, ELSE), даже при нормальной работе системы без разделения, нужно выбирать между задержкой (L) и согласованностью (C). PACELC расширяет и уточняет CAP-теорему за счет поиска компромисса между временной задержкой и согласованностью данных. Подробнее об этом мы писали здесь.
Kafka MirrorMaker 2 и решения Confluent
Мультирегиональный кластер хорошо работает, когда регионы расположены относительно близко друг к другу. Для больших расстояний, например, по разным континентам следует рассмотреть варианты на основе инструмента Kafka Connect, о работе которого мы рассказывали в этом материале. Одним из них является MirrorMaker 2 – 2-я версия утилиты Apache Kafka для зеркального копирования данных: топиков, конфигураций, смещения групп потребителей и ACL-списков. При этом, в отличие от MRC, смещения топиков не сохраняются. Поэтому в случае аварийного переключения потребуется восстанавливать смещения вручную. Однако, MirrorMaker 2 сохраняет разделение топиков, автоматически обнаруживает новые топики и разделы.
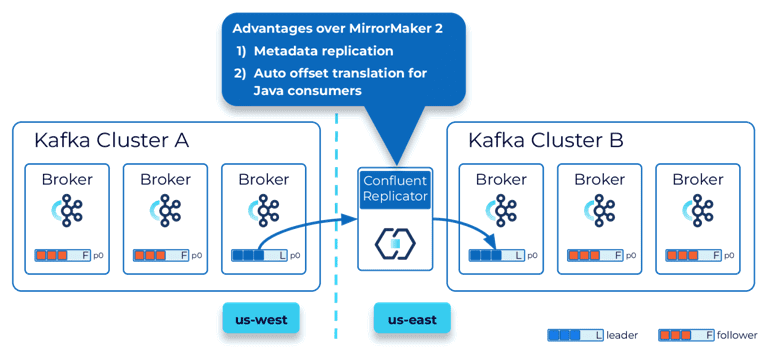
Кроме MirrorMaker 2 можно воспользоваться Confluent Replicator, который поддерживает репликацию метаданных, автоматическое создание топиков и автоматический перевод смещения для потребителей Java. Подробнее об этом решении мы писали в прошлой статье.
Еще одним решением Confluent является Cluster Linking. Топология связанных кластеров создает связь между исходным и целевым кластером частью самих кластеров Kafka. При этом нет отдельного процесса для запуска репликации. Данные передаются напрямую из источника в пункт назначения без необходимости их использования и воспроизведения, в отличие от предыдущих решений на основе Kafka Connect. Это обеспечивает более эффективную передачу данных и сохранение смещений. Cluster Linking также позволяет соединять кластеры Confluent Cloud и локальные кластеры Confluent Platform.
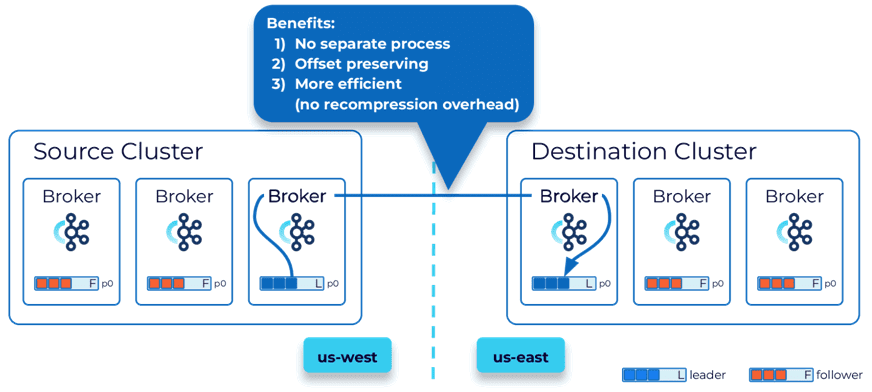
Когда пункт назначения инициирует соединение, источнику придется открыть порты брандмауэра, чтобы разрешить это. Если это запрещено по требованиям безопасности, соединение будет инициировать сам источник, а целевой кластер использует его для получения данных.
В заключение составим таблицу, агрегирующую выбор между различными способами репликации по наиболее важным критериям:
- характер (синхронный или асинхронный);
- возможность сохранять смещения потребителей;
- толерантность к задержкам;
- расположение относительно кластера – встроен в кластер или стороннее решение.
|
Способ репликации |
Характер (синхронный или асинхронный) |
Сохранение смещений потребителей |
Толерантность к задержкам |
Встроен в кластер или стороннее решение |
|
Мультирегиональный кластер |
Синхронный или Асинхронный |
Да |
Нет |
Встроен в кластер |
|
Mirro Maker 2 |
Асинхронный |
Нет, придется переводить смещения вручную |
Да |
Стороннее решение |
|
Confluent Replicator |
Асинхронный |
Нет, только автоматический перевод смещений для Java-потребителей |
Да |
Стороннее решение |
|
Cluster Linking в Confluent Server |
Асинхронный |
Да |
Да |
Встроен в кластер |
Помимо выбора способа мультирегиональной репликации кластера Kafka также надо решить вопрос со стратегией развертывания, что мы рассматриваем в новой статье.
Узнайте больше про администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
[elementor-template id=»13619″]
Источники

