Чтобы сделать наши курсы для дата-инженеров еще более интересными, сегодня рассмотрим практический пример построения инфраструктуры для автоматической диагностики и исправления ошибок пакетной и потоковой обработки данных в Netflix. Комплексная система на базе Apache Spark, Kafka, Flink, Druid, сервисов AWS и других технологий Big Data.
Предыстория: зачем Netflix разработал Pensive
Обработка данных в Netflix в пакетном и потоковом режиме выполняется в сложной облачной инфраструктуре. По мере поста количества пользователей, увеличивается количество пакетных рабочих процессов и конвейеров обработки данных в реальном времени. Изначально платформа данных Netflix была построена на основе нескольких распределенных систем, что давало периодические сбои на высоких нагрузках. Чтобы вовремя идентифицировать такие проблемы и устранить их причины, необходимо проанализировать логи и метрики из нескольких разных систем. В корпоративном масштабе даже небольшой процент сбоев может создать существенную нагрузку на команду дата-инженеров при ручном исправлении неполадок. Кроме того, подобные отказы влияют на работу пользователей производительность пользователей и негативно отражаются на бизнес-показателях.
Поэтому перед Netflix стала задача автоматической диагностики сбоев в потоковой и пакетной обработке данных и их исправления без вмешательства человека по мере возможности. Для этого в компании была разработана собственная платформа под названием Pensive, способная выявлять общие проблемы в режиме реального времени и диагностировать их влияние на рабочие нагрузки. Pensive состоит из двух отдельных систем для поддержки пакетных и потоковых рабочих нагрузок, которые рассмотрены далее.
Пакетная обработка
Пакетные рабочие процессы запускаются с использованием службы планировщика. Она запускает контейнеры на платформе Netflix под названием Titus для выполнения пакетных процессов, в рамках которых запускаются задания в кластерах с Apache Spark и TrinoDb через Genie.
Genie – это распределенный движок, созданный Netflix, который отделяет запуск заданий от конфигурации, что позволяет гибко масштабировать Big Data системы и освободить пользователей от поиска нужного им кластера. Например, когда есть много пользователей, которым нужно отправлять различные задачи в облако, содержащее большое количество кластеров Hadoop разных размеров. Genie предоставляет унифицированные RESTful API для автономной отправки заданий.
Если шаг рабочего процесса завершается с ошибкой, планировщик сообщает об этом Pensive, запрашивая его диагностировать ошибку шага. Pensive собирает логи невыполненных заданий, запущенных на этом шаге, из соответствующих компонентов платформы данных, трассируя к стеку использованных технологий. Pensive использует движок правил на основе регулярных выражений. Правила кодируют информацию о причине ошибке: вызвана она платформой данных или пользователем, а также характере сбоя — является ли ошибка временной или нет. Если регулярное выражение из одного из правил совпадает, то Pensive возвращает планировщику информацию об этой ошибке. Если ошибка является временной, планировщик повторит этот шаг с экспоненциальной задержкой еще несколько раз.
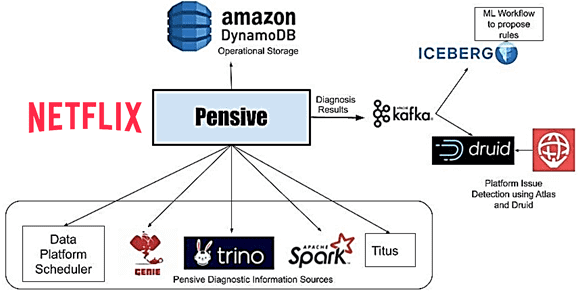
Наиболее важной частью Pensive является набор правил для классификации ошибок. Этот набор правил следует развивать и поддерживать по мере развития платформы, чтобы процент ошибок, которые Pensive не может классифицировать, оставался низким. Сперва правила добавлялись на разовой основе по мере поступления запросов от владельцев компонентов платформы и пользователей. Но по мере развития платформы внедрен более систематический подход, когда неизвестные ошибки передаются в процесс машинного обучения. Алгоритмы Machine Learning выполняют кластеризацию, чтобы предлагать новые регулярные выражения для часто встречающихся ошибок, которые далее классифицируются по источнику проблемы и частоте ее возникновения. В будущем Netflix планирует полностью автоматизировать этот процесс.
Хотя Pensive классифицирует ошибки на отдельных этапах рабочего процесса, анализируя ошибки в реальном времени, обнаруженных с помощью Apache Kafka и Druid, можно быстро выявить проблемы платформы, влияющие на многие рабочие процессы. Как только отдельные диагнозы сохраняются в таблице Druid, система мониторинга и оповещения под названием Atlas каждую минуту агрегирует их и отправляет оповещения в случае внезапного увеличения числа сбоев из-за ошибок платформы. Это значительно сократило время для обнаружения проблем с оборудованием или ошибок в недавно развернутом ПО платформы данных. Про совместное использование Kafka и Druid в Netflix читайте здесь.
Несмотря на достигнутые успехи, в будущем разработчики Netflix планируют улучшить Batch Pensive, чтобы не только диагностировать невыполненные задания, но и определять причину этого и факторы их замедления. Еще необходима автоматическая настройка пакетных процессов, чтобы они успешно завершались или становились быстрее, а также использовали меньше ресурсов. Например, это актуально для заданий Spark, где настройка памяти является серьезной проблемой. Наконец, можно расширить возможности Pensive с помощью классификаторов машинного обучения.
Потоковая передача данных с Flink и Kafka
Основным компонентом потоковой обработки данных в Netflix является Apache Flink. Большинство заданий Flink выполняются на управляемой платформе под названием Keystone, которая абстрагирует основные сведения о них и позволяет пользователям получать данные из потоков Apache Kafka и публиковать их в различных хранилищах данных, таких как Elasticsearch и Apache Iceberg, на AWS S3.
Поскольку платформа данных управляет конвейерами Keystone, поэтому пользователи ожидают, что возникшие проблемы обработки данных будут обнаружены и устранены автоматически. Но данные в потоках Kafka имеют конечный срок хранения. Это устанавливает временные ограничения для решения проблем, чтобы избежать потери данных. Потому для каждого задания Flink, выполняемого в рамках конвейера Keystone, дата-инженеры Netflix отслеживают, насколько потребитель Flink отстает от продюсера Kafka. Если этот показатель превышает пороговое значение, Atlas отправляет уведомление в Streaming Pensive.
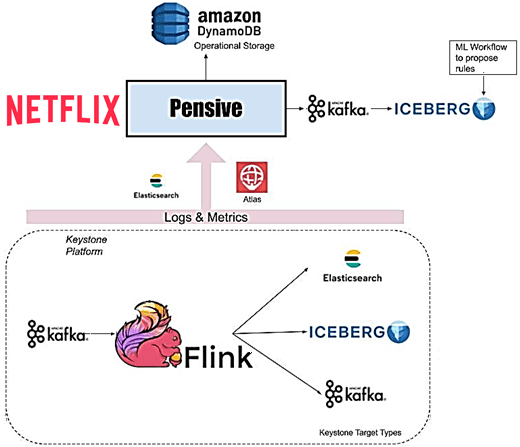
Аналогично пакетной обработке, в Streaming Pensive также есть механизм правил для диагностики ошибок. Но в дополнение к логам еще присутствуют правила проверки различных значений метрик для нескольких компонентов в конвейере Keystone. Проблема может возникать в исходном потоке Kafka, основном задании Flink или приемниках, которые получают данные. Streaming Pensive диагностирует это и пытается автоматически исправить проблему, когда она возникает. Например, если Streaming Pensive обнаружит, что одному или нескольким диспетчерам задач Flink не хватает памяти, он может повторно развернуть кластер Flink с дополнительными диспетчерами задач.
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
1 августа, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Или, когда Streaming Pensive обнаружит неожиданное увеличение скорости входящих сообщений в исходном кластере Kafka, он может увеличить размер и период хранения темы, чтобы не потерять данные, пока потребитель отстает. При исчезновении всплеска Streaming Pensive может отменить изменения хранения. Иначе владельцу задания Flink будет отправлено сообщение, чтобы выяснить причину ошибки, которая вызывает повышенную скорость, или необходимость перенастроить потребителей для обработки более высокой скорости. А когда требуется ручное вмешательство, Streaming Pensive сообщит команде ответственных дата-инженеров о необходимости принять своевременные меры для решения проблемы.
В будущем разработчики Netflix планируют охватить с помощью Pensive недавно созданную децентрализованную по разным доменам архитектуру данных 4-го поколения Data Mesh. Распределенная архитектура Data Mesh имеет централизованное управление и единые стандарты, которые обеспечивают интегрируемость данных, а также централизованную инфраструктуру с возможностью использования в режиме самообслуживания. Поскольку Data Mesh активно использует потоковую парадигму обработки данных, следует расширить Streaming Pensive.
Узнайте больше про администрирование и эксплуатацию Apache Flink, Spark и Kafka для разработки распределенных приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для разработчиков
- Потоковая обработка данных с помощью Apache Flink
- Hadoop для инженеров данных
- Потоковая обработка в Apache Spark