 947
947 
Содержание
В этой статье разберем, что такое прикладная аналитика больших данных на примере практического использования Apache Kafka и Druid в Netflix для обработки и визуализации метрик пользовательского поведения. Читайте далее, зачем самой популярной стриминговой компании отслеживать показатели клиентских устройств и как это реализуется с помощью Apache Druid, Kafka и других технологий Big Data.
Big Data Pipeline на Apache Kafka и Druid
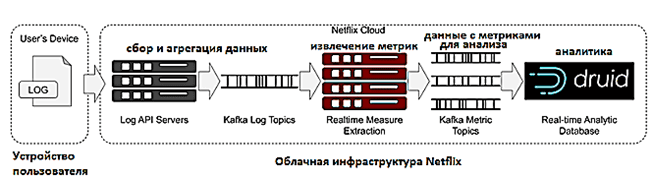
Напомним, бизнес Netflix, по сути, представляет собой интернет-кинотеатр, где можно в режиме онлайн смотреть видеозаписи: фильмы, передачи и пр. Чтобы понимать, как обновления и другие нововведения воспринимаются пользователями, Netflix отслеживает метрики о клиентских устройствах, классифицируя последние по типу: Smart TV, iPad, Android-телефон и т.д. Анализируя логи с этих устройств в реальном времени в качестве источника событий, аналитики Big Data могут понять и количественно оценить, насколько качественно (просто и без ошибок) выполняются просмотр и воспроизведение на разных типах девайсов. Так, например, можно определить проблемы, которые характерны только для определенных типов устройств, стран или зависят от версии приложения. Данные поступают со скоростью более 2 миллионов событий в секунду, поэтому для их анализа необходима соответствующая Big Data технология, такая как Apache Druid [1].
Apache Druid — это быстрая высокопроизводительная масштабируемая СУБД для обработки, аналитики и визуализации данных в реальном времени. Она выполняет потоковую передачу данных из брокеров сообщений, в частности, Apache Kafka и Amazon Kinesis, а также обеспечивает пакетную загрузку файлов из озер данных, HDFS и Amazon S3. Druid поддерживает самые популярные форматы файлов для обработки структурированных и полуструктурированных данных. Благодаря современным подходам к хранению, индексации, а также реализации запросов, Druid с высоким уровнем параллелизма позволяет оперативно (меньше чем за секунду) получить согласованные результаты для анализа рисков, выявления мошенничества, аналитики потока посещений, цепочек поставок, сетевой телеметрии, цифрового маркетинга, и многих других кейсов обработки множества данных в реальном времени [2].
Аналитика больших данных для руководителей
Код курса
BDAM
Ближайшая дата курса
20 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Таким образом, конвейер (pipeline) аналитики больших данных на базе Apache Kafka и Druid можно представить в следующем виде [1]:
- события, т.е. метрики считываются прямо из Apache Kafka по принципу 1 топик для одного источника данных;
- задачи индексации Kafka создают несколько рабочих процессов, которые распределяются между узлами реального времени;
- каждый индексатор подписывается на топик Kafka и считывает свою долю событий из потока;
- индексаторы извлекают значения из сообщений о событиях в соответствии со спецификацией приема и накапливают созданные строки в памяти;
- как только строка создана, ее можно запросить с помощью Druid SQL и или собственного механизма запросов (native quires) собственные запросы, которые отправляются как JSON в конечную точку REST.
Как устроен Apache Druid: архитектура и принципы работы
Хотя Druid не является классической реляционной СУБД, некоторые термины этой концепции можно применить здесь. некоторые концепции можно переносить. Например, логическая группировка однотипных данных в виде столбцов. Но, как мы недавно упоминали, в Druid нет полноценной поддержки JOIN, а вместо таблиц – источники данных. Поэтому перед тем, как фильтровать или группировать столбцы, следует убедиться, что они включены в каждый источник данных. Обычно в источнике данных есть столбцы трех категорий: время, измерения и метрики.
Все в Druid зависит от времени. У каждого источника данных есть столбец с отметкой времени, который является основным механизмом разделения. Измерения — это значения, которые можно использовать для фильтрации, запроса или группировки. Метрики — это значения, которые можно агрегировать, и они почти всегда являются числовыми [1].
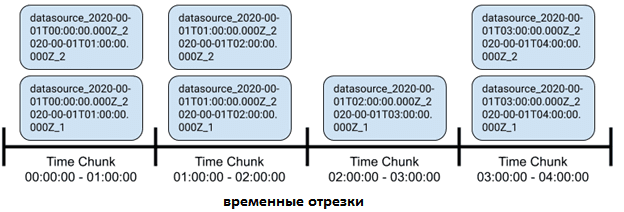
Привязав данные к временной метке (timestamp), Druid оптимизирует их хранение, распределение и обработку запросов. Это позволяет масштабировать источник данных до триллионов строк, обеспечивая время ответа на запрос за десятки миллисекунд. Для достижения такого уровня масштабируемости Druid делит хранимые данные на временные отрезки (Time Chunk) с настраиваемой продолжительностью. Данные временного отрезка хранятся в одном или нескольких сегментах. Каждый сегмент содержит строки данных, попадающие во временной отрезок, который определен ключевым столбцом timestamp’а. Размер сегментов может быть настроен так, чтобы существовала верхняя граница количества строк или общего размера файла сегмента [2].
При запросе данных Druid отправляет запрос всем узлам в кластере, которые содержат сегменты для временных отрезков в пределах диапазона запроса. Каждый узел обрабатывает запрос перед отправкой промежуточных результатов обратно брокеру, параллельно с вычислениями над данными, которые он хранит. Брокер выполнит окончательное слияние и агрегирование перед отправкой набора результатов обратно клиенту [2].
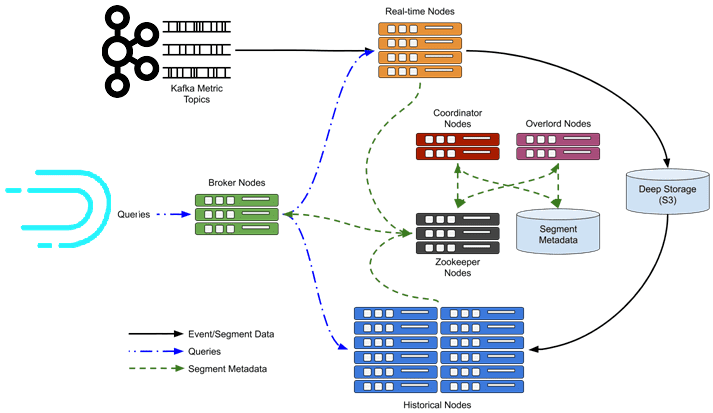
Возвращаясь к кейсу Netflix, отметим, что узнать, когда были получены все события для конкретного отрезка времени, не так просто. Данные могут поступать в топики Kafka с опозданием, или индексаторам может потребоваться время, чтобы передать сегменты историческим узлам. Чтобы обойти эти ограничения, дата-инженеры Netflix отбрасывают данные, которые поступили слишком поздно и уплотняют строки для формирования аналитических запросов [1]. Еще пару интересных кейсов по практическому применению Apache Kafka для интерактивной аналитики больших данных мы описываем здесь и здесь. А про автоматическую диагностику и исправление ошибок в платформе данных Netflix читайте в нашей новой статье.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Больше примеров по практической аналитике больших данных, а также администрированию и эксплуатации Apache Kafka в проектах цифровизации частного бизнеса или цифровой трансформации государственных и муниципальных предприятий вы узнаете на наших специализированных курсах в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

