
Продвигая наши курсы для разработчиков Spark с примерами реальных систем аналитики больших данных, сегодня рассмотрим библиотеку для чтения файлов формата DICOM от индийской компании Abzooba. Читайте далее, как автоматизировать поиск по миллиардам медицинских изображений с помощью машинного обучения и технологий Big Data: Apache Spark, Hadoop, Kafka, Elasticsearch и Kibana. Что...
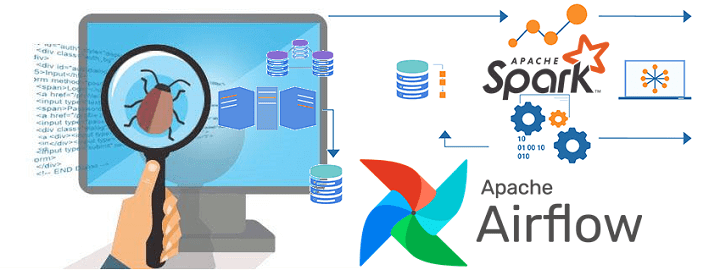
Поскольку курсы инженеров Big Data предполагают практическое обучение на реальных кейсах, сегодня поговорим про тестирование конвейеров обработки и аналитики больших данных и разберем несколько прикладных примеров для компонентов экосистемы Apache Hadoop. Читайте далее про проверку работоспособности, а также поиск ошибок в Spark-заданиях и DAG-цепочках Airflow. Конвейер для конвейера: сложности тестирования...

Чтобы показать, насколько разной бывает аналитика больших данных, сегодня рассмотрим кейс международной компании Spidertracks, которая с помощью технологий Big Data создает ИТ-решения для отслеживания, связи и управления безопасностью воздушных судов. Читайте далее, почему для потоковой обработки событий был выбран Kinesis Analytics for SQL, а не конвейер из Apache Kafka и...

Сегодня продолжим разбираться с реализацией CDC-подхода в современных Big Data решениях и погрузимся в Databricks Delta Lake – облачный уровень хранения и аналитики больших данных с поддержкой ACID-транзакций. Читайте далее про переход от ночных ETL-пакетов с Informatica к быстрому обновлению данных в Amazon S3 на конвейере Spark и Kafka. Возможности...
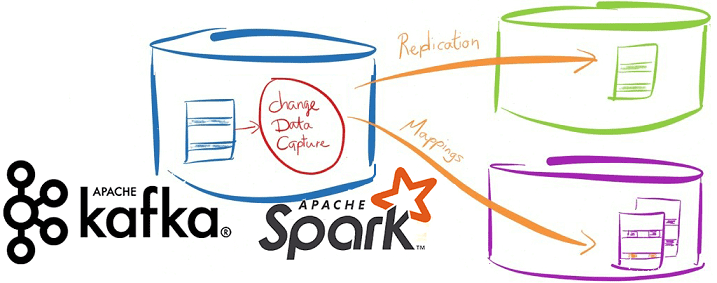
Вчера мы упоминали про CDC-подход в проектировании транзакционных систем аналитики больших данных на базе Apache Kafka и Spark Streaming. Сегодня рассмотрим подробнее примеры такого применения технологий Big Data и лучшие практики Change Data Capture в потоковой обработке финансовых и других транзакций. Зачем нужны потоковые конвейеры транзакционной обработки Big Data на...

В этой статье рассмотрим особенности совместного использования Apache Kafka и Spark Streaming для обработки финансовых транзакций в режиме онлайн. Читайте далее про типовые кейсы практического применения конвейера аналитики больших данных на базе Kafka и Spark, а также проблемы или технологические особенности такой Big Data системы и пути обхода этих ограничений....

Продолжая разговор про оптимизацию Apache Spark и повышение эффективности Big Data приложений, сегодня рассмотрим способы ускорения Shuffle-операций в Spark SQL, разберем, чем хороши широковещательные JOIN-операции и как количество разделов влияет на производительность запросов в распределенных приложениях аналитики больших данных. 4 способа оптимизации Shuffle-операций При аналитике больших данных с помощью Apache...

Недавно мы рассматривали, как повысить производительность конвейеров Apache Spark и повысить скорость распределенных приложений для аналитики больших данных. Сегодня разберемся, почему тормозят отдельные Spark-задачи и как их ускорить. Читайте далее про инициализацию Спарк-контекста, предзагрузку артефактов и применение клиентского режима. Почему некоторые задачи в быстром Apache Spark выполняются так медленно Напомним,...
Мы уже рассказывали, почему качество данных является важнейшим аспектом разработки и эксплуатации Big Data систем. Приемлемое для эффективного использования качество массивов информации достигается не только с помощью процессов подготовки датасета к машинному обучению и профилирования данных, но и за счет их согласования. Читайте далее, что такое Data reconciliation, зачем это...

Чтобы сделать ваше самостоятельное обучение Apache Kafka и прочим технологиям Big Data по статьям нашего блога еще более интересным, сегодня мы предлагаем вам открытый интерактивный тест по этой платформе потоковой обработки событий. Ответьте на 10 простых вопросов и узнайте, насколько хорошо вы знакомы с особенностями администрирования и эксплуатации этого популярного...