 1034
1034 
Содержание
Продвигая наши курсы для разработчиков Spark с примерами реальных систем аналитики больших данных, сегодня рассмотрим библиотеку для чтения файлов формата DICOM от индийской компании Abzooba. Читайте далее, как автоматизировать поиск по миллиардам медицинских изображений с помощью машинного обучения и технологий Big Data: Apache Spark, Hadoop, Kafka, Elasticsearch и Kibana.
Что такое DICOM-файлы: аналитика больших данных в медицине
Сегодня DICOM (Digital Imaging and Communications in Medicine) считается основным отраслевым стандартом, который поддерживается производителями медицинского оборудования и программного обеспечения для создания, хранения, передачи и визуализации цифровых медицинских изображений и документов обследованных пациентов. Он опирается на ISO-стандарт OSI и разработан Национальной ассоциацией производителей электронного оборудования (National Electrical Manufacturers Association). DICOM определяет 2 информационных уровня [1]:
- файловый – объектный файл с теговой организацией для представления кадра изображения (или серии кадров) и сопровождающей или управляющей информации (в виде тегов);
- коммуникационный (сетевой DICOM-протокол) для передачи файлов и управляющих команд по TCP/IP сетям.
Стандарт Digital Imaging and Communications in Medicine используется во множестве областей медицины для визуализации исследований: радиологии, кардиологии, онкологии, акушерстве, стоматологии и пр. DICOM-изображения состоят из собственно графических изображений и метаданных, связанных с ними: информация о пациенте, устройстве, медицинском учреждении и персонале, дате, времени, виде, условиях и параметрах обследования и т.д. Таким образом, благодаря наличию подробных метаданных об объекте и предмете исследований, DICOM-изображения позволяют автоматизировать поиск и их аналитику с помощью технологий Big Data.
Представим типичный кейс аналитики больших данных в медицине, например, для фундаментальных исследований необходимо проанализировать множество МРТ-снимков пациентов мужского пола в возрасте 20-30 лет. При этом входные данные могу находиться в нескольких разных источниках. Автоматизировать поиск DICOM-файлов, отвечающих таким условиям, можно с помощью технологий Big Data: Apache Spark, Hadoop, Kafka, Elasticsearch и Kibana, о чем мы расскажем далее.
Архитектура Big Data системы для анализа медснимков
Итак, для реализации вышеописанной системы быстрого поиска и аналитики больших данных по данным медицинских исследований в формате DICOM подойдет следующая архитектура Big Data системы [2]:
- DCOM-файлы из различных источников собираются в топиках Apache Kafka;
- Spark-приложение с помощью библиотеки от индийской компании Abzooba, о которой мы поговорим далее, ищет изображения, метаданные которых соответствуют заданным условиям;
- найденные значения метаданных со ссылкой на изображение сохраняются в некотором хранилище, например, Apache HBase, откуда их можно загружать напрямую в любую поисковую систему, такую как Solr или Elasticsearch.
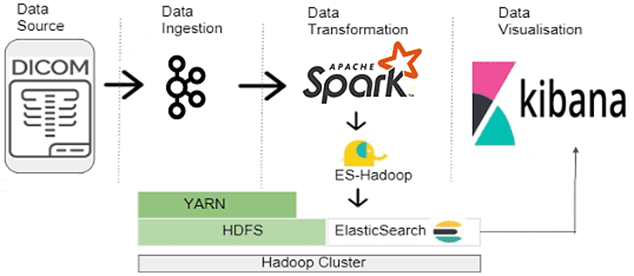
Справедливости ради стоит отметить, что Apache Spark предоставляет API для чтения многих форматов (CSV, JSON, Parquet), а также изображений JPEG и PNG. Однако, API для непосредственного чтения DICOM-изображений по умолчанию не было. Поэтому в феврале 2020 года инженеры Big Data компании Abzooba создали библиотеку Spark-Scala для анализа DICOM-файлов через API Dataframe в Spark SQL, чтобы повысить эффективность аналитики больших данных в медицинских исследованиях. Как она устроена, рассмотрим далее.
Spark-библиотека для анализа DICOM-файлов через SQL Dataframe
Dicom Data Source, библиотека от Abzooba, выпущена для Scala 2.11 и Java 1.8.0_221. Для разработки библиотеки также использовалась сторонняя библиотека с именем dcm-4che source code. Для этого пакета еще нет выпусков, опубликованных в репозитории Spark Packages, или с указанием Maven-координат. Поэтому, чтобы использовать ее на практике, разработчику Spark придется собрать пакет из исходного кода с помощью команды maven package. Также его можно установить в локальном репозитории Maven с помощью команды maven install: install-file. Собранный JAR-архив можно использовать как внешнюю зависимость, добавив его в путь к классам.
Dicom Data Source для Spark поддерживает чтение DICOM-изображений в датафрейме Spark SQL и возвращает отдельный Dataframe, содержащий сведения о поврежденных файлах. Схема датафрейма содержит три столбца [3]:
- origin – путь к DICOM-файлу;
- metadata – метаданные пациента (Пациент, Устройство) в формате JSON;
- pixeldata – данные пикселей в виде массива байтов.
Схема датафрейма с поврежденными данными содержит два столбца:
- origin – путь к DICOM-файлу;
- exception – сообщение, отображающее исключение, возникшее при чтении DICOM-файла.
Впрочем, сама идея автоматизированной аналитики медицинских снимков с помощью распределенных Spark-приложений отнюдь не нова. Можно сказать, что библиотека Dicom Data Source от Abzooba дополняет и расширяет решение предиктивной аналитики DICOM-файлов, представленное компанией Intel на форуме Spark-Summit в 2017 году. Демо-версия продукта от Intel построена на базе следующих компонентов [4]:
- PyDicom – Python-пакет для работы с DICOM-файлами;
- dcm-4che – Java-коллекция медицинских open-source приложений и утилит;
- Matplotlib – Python-библиотека для визуализации данных;
- ML-библиотека TensorFlow с алгоритмами машинного обучения для анализа данных;
- Apache Spark;
- Коннектор Spark-TensorFlow.
Таким образом, архитектура Big Data системы от Abzooba развивает идеи Intel, предлагая заменить некоторые элементы Machine Learning в TensorFlow встроенными в Elasticsearch поисковыми алгоритмами. А визуализацию данных выполнять в другом компоненте ELK-стека – Kibana, вместо отдельных ML-библиотек. О возможностях машинного обучения в Elasticsearch мы рассказывали здесь. На практике оба решения имеют право на существование, поскольку любое из них потребует существенного дополнения в случае реального применения к конкретному кейсу медицинской аналитики больших данных.
Узнайте больше о практических примерах построения эффективных конвейеров аналитики больших данных в экосистеме Apache Hadoop с помощью Spark-приложений на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Hadoop для инженеров данных
- Построение конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
Источники
- https://ru.wikipedia.org/wiki/DICOM
- https://bd-practice.medium.com/dicom-read-library-apache-spark-third-party-contribution-e6cb269e5c3c
- https://github.com/abzoobabd/spark-dicom
- https://github.com/397090770/spark-summit-2017-SanFrancisco/blob/master/ppt/A-Predictive-Analytics-Workflow-on-DICOM-Images-using-Apache-Spark-with-Anahita-Bhiwandiwalla-and-Karthik-Vadla-iteblog.pdf

