 1110
1110 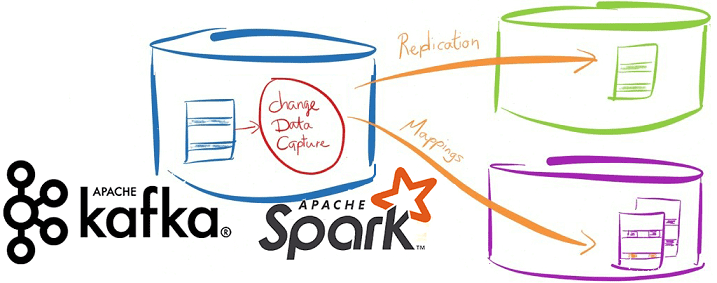
Содержание
Вчера мы упоминали про CDC-подход в проектировании транзакционных систем аналитики больших данных на базе Apache Kafka и Spark Streaming. Сегодня рассмотрим подробнее примеры такого применения технологий Big Data и лучшие практики Change Data Capture в потоковой обработке финансовых и других транзакций.
Зачем нужны потоковые конвейеры транзакционной обработки Big Data на Apache Kafka и Spark
Напомним, благодаря вычислениям в оперативной памяти Apache Spark намного ускоряет процессы обработки данных в таких Big Data хранилищах, как AWS S3 и Hadoop HDFS. А в рамках потокового конвейера Spark Streaming API позволяет обрабатывать данные в течение нескольких секунд по мере их поступления от источника, в качестве которого может выступать Kafka. Однако, разговор о аналитике больших данных в режиме реального времени не имеет смысла, если исходные данные, поступающие в конвейер Kafka-Spark, имеют возраст в несколько часов или дней. Решить эту проблему поможет подход сбора измененных данных (CDC, Change Data Capture), что особенно актуально для транзакций. CDC получает оперативные транзакции СУБД-источника и отправляет копии в конвейер с практически нулевой задержкой вместо медленных пакетных заданий. Это также снижает накладные расходы на вычисления и требования к пропускной способности сети. Чтобы наглядно показать, насколько такое решение выгодно бизнесу, далее ы рассмотрим пару практических примеров, а сейчас отметим лучшие практики реализации CDC-подхода с помощью Apache Kafka и Spark [1]:
- Kafka обеспечивает потоковый примем и агрегацию данных от множества источников, позволяя буферизовать входящие сообщения в течение настраиваемых периодов времени. Такое поведение (много источников, большие объемы данных и разные временные интервалы с целевым приемником) типичны для транзакций СУБД, которые генерируются непрерывно, а анализируются периодически.
- CDC-данные могут требовать дополнительной логики для установки точной согласованности транзакций и обеспечения ACID-соответствия на основе схем исходной СУБД и параметров записи. Эти накладные расходы на обработку быстро возрастают в случае нескольких потребителей и производителей, которые используют данные из разных топиков. Поэтому рекомендуется ограничивать количество целей и потоков Kafka.
- Упростить развертывание и управление сложным Big Data решением помогут облачные провайдеры. AWS, Azure и Google Cloud включают Apache Spark в свои IaaS/SaaS-решения, такие как Amazon EMR, Azure Data Lake Store (ADLS) и Google Dataproc. Кроме того, Databricks предоставляет платформу на основе Apache Spark как услугу, где можно настроить собственный конвейер и систему аналитики больших данных.
Как все эти и другие лучшие практики реализуются в бизнесе, рассмотрим далее.
3 примера CDC-конвейеров потоковой аналитики больших данных
Оперативная отчетность из ERP вместо ночных ETL-заданий
Крупному производителю пищевых продуктов требовалось оперативная аналитика и непрерывная интеграция данных о производственных мощностях, заказах клиентов и заказах на закупку. Сперва компания пыталась объединить различные большие наборы данных, распределенные по нескольким разрозненным хранилищам, в нескольких приложениях SAP ERP. Однако, ночная пакетная репликация не позволяла быстро сопоставлять заказы и данные о производственных линиях. Эти задержки замедляли график работы завода и снижали точность ежедневных отчетов о продажах.
Поэтому предприятие решило изменить подход к хранению и интеграции корпоративных данных, перейдя на Apache Hadoop. Было построено новое озеро данных (Data Lake) на Hadoop Hortonworks, включая Spark и CDC. CDC обеспечивает эффективное копирование изменений записей SAP каждые 5 секунд, извлекая эти данные из исходного пула ERP-системы и таблиц кластера. Далее CDC внедряет эти обновления источников данных вместе с обновлениями метаданных в очередь сообщений Kafka, которая буферизует эти большие объемы информации и отправляет их по запросу потребителям HDFS и HBase в Data Lake. Чтобы сократить накладные расходы на обработку и пересылку данных по сети, количество топиков Apache Kafka было ограничено до 10, по одной на исходную таблицу. После того, как данные поступают в HDFS и HBase, быстрые Spark-приложения сопоставляют заказы с производством в реальном времени, поддерживая ссылочную целостность для таблиц заказов на закупку. Таким образом, в результате замены пакетных ETL-процессов на потоковую CDC-передачу, компания ускорила продажи и доставку своей продукции за счет точной оперативной отчетности в реальном времени, чтобы работать более эффективно и прибыльно [1].
CDC с Kafka и Spark на MS Azure и Databricks
Другой интересный пример использования CDC-похода в построении Big Data конвейеров на Kafka и Spark — оперативная отчетность по финансовым показателям в реальном времени. Для этого американская компания, занимающаяся частным и венчурным капиталом, создала озеро данных для консолидации и анализа операционных показателей своих портфельных компаний. Чтобы не заниматься развертыванием и администрированием локальной Big Data инфраструктуры, предприятие разместило свое озеро данных в облаке Microsoft Azure. Далее процесс real-time консолидации больших данных построен следующим образом [1]:
- CDC удаленно собирает обновления и изменения из исходных СУБД (Oracle, SQL Server, MySQL и DB2) в четырех разных местах по всем США;
- далее эти данные отправляются через зашифрованное соединение на репликацию в облако MS Azure;
- механизм репликации MS Azure по запросу публикует обновления данных в Apache Kafka и в файловой системе Databricks, сохраняя сообщения в формате JSON;
- приложения Apache Spark подготавливают данные в микро-пакетах для озера данных HDInsight, SQL-хранилища и других внутренних и внешних подписчиков топиков Kafka, классифицированных по исходным таблицам.
Такая CDC-архитектура позволяет финансовой корпорации эффективно получать аналитику больших данных в реальном времени без ущерба текущим бизнес-процессам.
Change Data Capture в решениях Informatica
Благодаря преимуществам и относительной простоте CDC-подхода его активно используют вендоры корпоративных Big Data решений. В частности, компания Informatica выделяет следующие кейсы применения своего продукта Cloud Mass Ingestion Service, построенного на основе CDC с использованием Apache Kafka и Spark [2]:
- прием данных из различных источников (озера и корпоративные хранилища, файлы, потоковые данные, IoT, локальные СУБД) в облачное Data WareHouse и Data Lake с синхронизацией исходных и целевых данных;
- модернизация или миграция КХД: массовое извлечение данных из локальных СУБД (Oracle, IBM DB2, Microsoft SQL и пр.) в облачное хранилище данных. CDC обеспечивает синхронизацию источника и цели
- ускорение обмена сообщениями для потоковой аналитики больших данных и генерации комплексных отчетов в реальном времени.
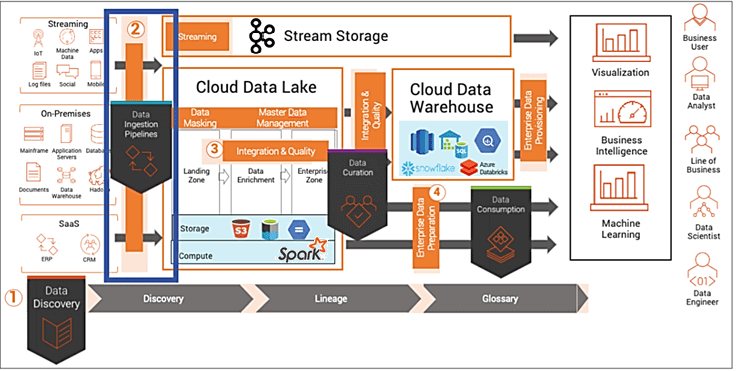
Как это работает на практике, мы рассмотрим завтра, заглянув под капот Big Data системы потоковой аналитики больших данных на базе Informatica и Databricks Delta Lake c CDC-реализацией в конвейере Kafka-Spark.
А научиться самостоятельно строить эффективные конвейеры аналитики больших данных с Apache Kafka и Spark вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для разработчиков
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Построение конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
Источники
- https://www.eckerson.com/articles/best-practices-for-real-time-data-pipelines-with-change-data-capture-and-spark
- https://www.informatica.com/content/dam/informatica-com/en/collateral/white-paper/change-data-capture-for-real-time-data-ingestion-and-streaming-analytics_white-paper_3914en.pdf

