 1043
1043 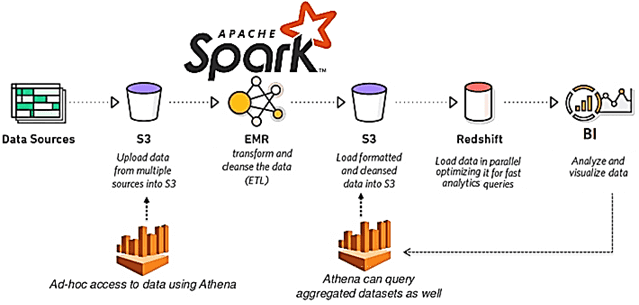
Содержание
Мы уже рассказывали, почему качество данных является важнейшим аспектом разработки и эксплуатации Big Data систем. Приемлемое для эффективного использования качество массивов информации достигается не только с помощью процессов подготовки датасета к машинному обучению и профилирования данных, но и за счет их согласования. Читайте далее, что такое Data reconciliation, зачем это нужно для бизнеса и как оно реализуется в Apache Spark и AWS.
Что такое согласование данных и при чем здесь Big Data
Как правило, реализация комплексной Big Data системы, в т.ч. на базе облачных сервисов, например, кластер Hadoop в Google DataProc или аналитика больших данных на веб-сервисах Amazon, начинается c репликации данных из исходных реляционных СУБД в единый репозиторий — озеро данных (Data Lake). Однако, прежде чем приступить к анализу агрегированных данных, их следует проверить их качество и целостность.
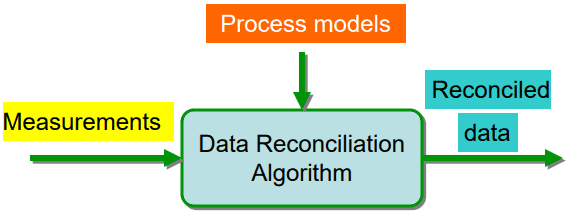
Такая комплексная проверка больших объемов данных называется согласование или сверка данных (Data Reconciliation) – процесс верификации данных во время миграции. При этом целевые данные сравниваются с исходными, чтобы убедиться, что архитектура миграции передает их корректно. В процессе миграции данных возможны ошибки в логике сопоставления и преобразования. Также к повреждению Big Data могут привести сбои заданий во время выполнения, отключение сети или прерванные транзакции. Валидация и согласование данных (Data validation and reconciliation, DVR) используют математические модели для обработки информации. Cогласование помогает извлечь точную и надежную информацию о реальных показателях бизнес-процессов из необработанных данных, позволяя создать единый согласованный датасет, который наиболее вероятен для анализируемых бизнес-процессов. Data Reconciliation оперирует следующими основными понятиями [1]:
- грубая ошибка (Gross Error) в измерениях — отражает ошибки смещения, отказы средств измерения или аномальные всплески шума в коротком периоде усреднения;
- наблюдаемость (Observability) — информация о том, какие переменные могут быть определены для данного набора ограничений и измерений;
- дисперсия (Variance) — мера изменчивости средства измерения;
- избыточность (Redundancy), которая помогает определить, какие измерения следует оценивать на основе других переменных через выражения ограничений.
Итак, процесс согласования данных направлен на исправление ошибок измерения и сведение грубых ошибок к нулю. Общий подход согласования данных основан на простом подсчете записей для отслеживания того, было ли перенесено целевое количество записей или нет. В целом выделяют 3 метода согласования данных [1]:
- согласование мастер-данных между источником и целью. Как правило, мастер-данные (или основные) обычно неизменны или меняются очень медленно и с ними не выполняется никаких операций агрегирования. При согласовании мастер-данных обычно проверяются следующие параметры: общее количество строк, количество элементов в источнике и цели, общее количество строк на основе конкретного условия. При этом следует убедиться в валидности и корректности транзакций, а также проверить правильность их авторизации. Подробнее о том, что такое мастер-данные, мы рассказывали в этом материале.
- согласование транзакционных данных, которые составляют основу систем бизнес-аналитики и BI-отчетов. Обычно этот метод выражается в терминах общей суммы, рассчитанной от источника и цели. Это предотвращает любое несоответствие, вызванное изменением степени детализации квалифицируемых измерений. Например, сумма общего дохода или сумма всего проданного товара, рассчитанные от источника и цели.
- автоматическая сверка данных как часть ETL-процесса в системе управления хранилищем данных. Это позволит вести отдельные таблицы метаданных загрузки и держать всех стейкхолдеров в курсе достоверности отчетов.
Чаще всего прикладные решения для миграции данных предоставляет возможности согласования и функции создания прототипов данных, которые обеспечивают задачи Data Reconciliation в полном объеме. Например, OpenRefine, TIBCO Clarity, Winpure и прочие инструменты для дата-инженера [1]. Однако, при построении комплексных Big Data систем и сложных конвейеров аналитической обработки больших данных функциональных возможностей готовых прикладных средств может оказаться недостаточно. Или возникнут сложности при их интеграции в многозадачный data pipeline. В этом случае стоит обратить внимание на средства Data Reconciliation, уже интегрированные в Big Data инфраструктуру, например, Apache Spark в Amazon EMR и Amazon Athena, о которых мы поговорим далее.
На практике согласование данных широко используется для мониторинга производственных и технологических процессов в нефтегазовой, ядерной и химической промышленности. В частности, в этой статье разберем кейс американской энергетической корпорации Direct Energy, которая обслуживает более 4 миллионов частных клиентов и предприятий. В рамках цифровой трансформации компания переносит собственные локальные хранилища данных и сервисы в облака AWS, чтобы повысить эффективность отслеживания, понимания и контроля предоставляемых потребителям ресурсов (электроэнергии и природного газа) [2].
Практический пример бизнес-потребности в Data Reconciliation: кейс Direct Energy
В Direct Energy переход от локальных хранилищ данных на базе SQL Server к озерам данных AWS строится следующим образом:
- команда менеджмента информационных системам (Management Information Systems, MIS) управляет базовой инфраструктурой AWS, включая AWS Identity and Access Management (IAM), конфигурацией Amazon EMR, приемом необработанных данных из хранилищ исходных данных и биллинговых систем на SQL Server, Oracle и MySQL;
- команда дата-инженеров собирает необработанные исходные данные после того, как они попадают в Amazon S3, преобразует типы данных, объединяет данные для выбранных таблиц и трансформирует их для создания корпоративного хранилища бизнес-данных, витрины данных и датасеты с помощью Spark-приложений на PySpark в Amazon EMR. Это включает в себя оркестровку зависимостей на каждом этапе.
- Заполненные витрины и наборы данных становятся доступными для бизнеса через Amazon Redshift и Microsoft Power BI для отчетов и аналитического моделирования, например, исследование трендов оттока клиентов (Churn Rate), эластичности цен, сегментации пользователей, показателей ценности (LTV, customer lifetime value) и прочих бизнес-метрик.
Из-за разных уровней детализации данных и сложности зависимостей между ними, для построения окончательных бизнес-дэшбордов, необходимо тестирование каждого из перечисленных этапов. Таким образом, команде дата-инженеров Direct Energy требовался автоматизированный способ проверки качества следующих данных:
- строк и полей для данных, хранящихся в Amazon S3;
- данных, созданных AWS Glue — бессерверным сервис подготовки данных и реализации ETL-операций, который позволяет извлекать, очищать, дополнять, нормализовать и загружать данные [3];
- данных, просматриваемых в локальных исходных системах через AWS Athena — интерактивный бессерверный сервис запросов, позволяющий анализировать данные в Amazon S3 с помощью стандартного механизма SQL. В Athena предусмотрена встроенная интеграция с каталогом данных AWS Glue, что позволяет создавать единый репозиторий метаданных для различных сервисов, сканировать источники данных для обнаружения схем, наполнять каталог новыми или измененными таблицами и определениями разделов, а также обеспечивать версионность схем [4].
Как это было реализовано на практике, рассмотрим далее.
Техника согласования данных с Apache Spark в Amazon EMR
Сперва команда MIS проводила ежедневный подсчет строк по источнику данных и AWS Athena, придерживаясь SLA на уровне 99%, учитывая возможные проблемы со сроками. Однако, это обеспечивало только проверку совпадения количества строк в разных системах, не позволяя адекватно профилировать данные или полностью измерить их качество. Кроме того, в Amazon S3 целевые данные должны точно совпадать с исходной системой, но выполнять проверки на уровне строк и полей для больших объемов данных слишком затратно. Поэтому в результате вывода из эксплуатации одного из основных хранилищ клиентских данных сотрудники Direct Energy переписали более 350 хранимых процедур SQL Server в PySpark.
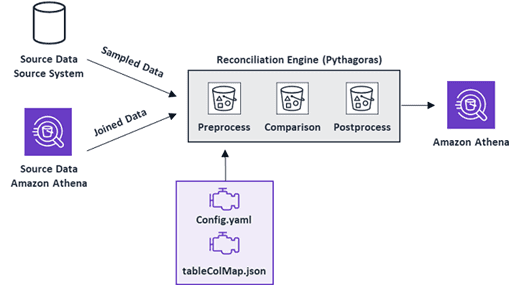
Также была необходимость добавления еще одного уровня тестирования для отладки кода и обеспечения того, чтобы ETL-процессы в облаке давали те же результаты, что и раньше на локальном сервере. Это включает тестирование промежуточных и финальных таблиц. С учетом огромного объема данных ручное тестирование невозможно. Потребовалось решение для автоматизации процедур тестирования качества данных на уровне строк и полей. Поэтому специалисты Direct Energy спроектировали и разработали собственный механизм согласования (Pythagoras). Каждый день он запускает процедуру случайной выборки записей для проверки совпадения отдельных значений в таблицах Amazon S3 и в исходных системах.
Движком Pythagoras является Apache Spark в Amazon EMR, который выполняет все этапы согласования данных: предварительную обработку (preprocess), сравнение (comparision) и постобработку (postprocess). В конфигурационном файле config.yaml определены исходные базы данных, таблицы, способы подключения к системам-источникам, задачи согласования и другие настроечные параметры. В отдельном файле tableColMap.json определены сопоставления столбцов между локальными таблицами сервера и таблицами, которые должны быть показаны при запросе через AWS Athena. Механизм согласования выводит отчет, который сохраняется непосредственно в Amazon S3 и может быть просмотрен с помощью Athena. Также можно проверить результаты с помощью Spark SQL в PySpark или экспортировать в Microsoft Excel.
Таким образом, используя собственный инструмент согласования данных Pythagoras для масштабной автоматизации и тестирования проверки качества данных с Amazon EMR и Athena, компания Direct Energy смогла добиться следующих результатов:
- повышение производительности ETL-процессов и качества приема данных из источников. Например, удалось повысить точность процессов обработки данных для двух биллинговых систем на 15% и 48%.
- устранение ручного тестирования и автоматизацию рандомизированной проверки.
- обнаружена ключевая причина проблемы целостности данных в ETL-конвейере — несоответствие значений в источнике и приемнике;
- упрощение перехода от локальной Big Data инфраструктуры к облачной с выводом из эксплуатации широко используемые платформ данных без потери их качества и целостности.
Примеры программного кода Pythagoras на PySpark и результаты сравнения согласованных данных можно детально посмотреть в источнике [2]. А практически разобраться с особенностями инженерии больших данных и разработки распределенных Spark-приложений вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Core Spark – Основы Apache Spark для разработчиков
- Построение конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
- Hadoop для инженеров данных
Источники

