 991
991 
Содержание
Сегодня продолжим разбираться с реализацией CDC-подхода в современных Big Data решениях и погрузимся в Databricks Delta Lake – облачный уровень хранения и аналитики больших данных с поддержкой ACID-транзакций. Читайте далее про переход от ночных ETL-пакетов с Informatica к быстрому обновлению данных в Amazon S3 на конвейере Spark и Kafka.
Возможности и ограничения CDC-конвейера для Databricks Delta Lake
Современные SaaS/IaaS-провайдеры предоставляют множество готовых решений и инструментов для пакетной и потоковой аналитики больших данных. Одной из таких облачных платформ является Delta Lake от Databricks – быстрое облачное хранилище на Apache Spark, которое располагается поверх корпоративной системы хранения данных, позволяя работать с ACID-транзакциями в Hadoop HDFS, BLOB-объектах Azure и Amazon S3. Подробнее о том, что такое Delta Lake от Databricks, мы писали здесь. При некоторых ограничениях этого решения, на практике оно весьма популярно, что подтверждает следующий кейс, который мы рассмотрим далее.
Типичный сценарий практического использования CDC-подхода с Databricks Delta Lake – это сбор и загрузка измененных данных из одного или нескольких источников в набор дельта-таблиц. Источниками данных могут быть локальные или облачные транзакционные СУБД или корпоративные хранилища данных, которые генерируют наборы изменений следующим образом [1]:
- с помощью ETL-инструмента, например, Oracle GoldenGate или Informatica PowerExchange;
- из таблиц изменений, предоставляемых вендором, к примеру, Oracle Change Data Capture;
- обслуживаемые пользователем таблицы базы данных, которые фиксируют наборы изменений с помощью триггеров вставки/обновления/удаления
Обычно CDC-процесс сбора изменений в наборе источников данных и их объединения в набор целевых таблиц является периодическим и запускается, к примеру, каждый час или чаще. Набор измененных записей для каждой таблицы в течение периода обновления называется набором изменений. Согласованность данных между источником и приемником обеспечивается за счет ссылок и ключей [1].
Существуют готовые CDC-решения и инструменты реализации собственных вариантов, в т.ч. для заданий на добавочный импорт или в реальном времени, однако в случае с облачным ACID-хранилищем Databricks Delta Lake они имеют ряд ограничений [2]:
- Apache Sqoop позволяет передавать данные между Hadoop и реляционной СУБД с помощью запланированных заданий инкрементного импорта. Но Databricks Delta Lake не поддерживает Sqoop. Кроме того, Sqoop работает в пакетном, а не потоковом режиме. Также, Sqoop increments требует наличия timestamp-столбца последнего изменения в исходной таблице и не поддерживает автоматическое удаление ненужных строк из Hive-таблицы при изменении схемы исходной таблицы. Напомним, т.к. SQL-представление данных в Hadoop реализуется через Apache Hive, то при переходе к Delta Lake информация должна быть в виде Hive-таблиц.
- Бинарный журнала или лог СУБД базы данных, бинлог — это набор последовательных лог-файлов с операциями записи, вставки, обновления или удаления. В этом случае потоковый CDC-конвейер позволяет использовать некоторый исходный код, например, JSON для синхронизации бинлога с Kafka, когда приложения Spark Streaming считывают данные из топика. Однако, если требуется воспроизвести бинлог в Hive-таблице, логика слияния данных усложняется.
С учетом этих ограничений и того факта, что Databricks Delta Lake основана на Apache Spark для построения CDC-конвейера к этому облачному ACID-хранилищу Big Data целесообразно использовать возможности Spark Streaming и SQL, о чем мы и поговорим далее.
От ночных пакетов Informatica к потоковому обновлению Big Data в AWS S3 с Kafka и Spark
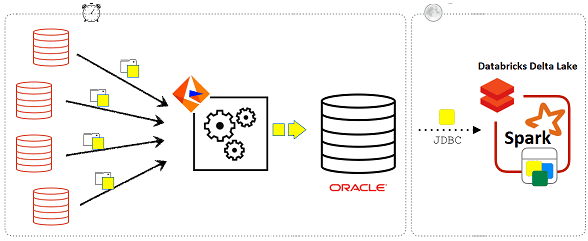
Рассмотрим пример отправки данных в Databricks Delta Lake до внедрения CDC-подхода. В качестве ETL-инструмента используется Informatica, которая отправляет наборы изменений из 30 различных источников и объединяет их в хранилище данных Oracle. Раз в день Spark-задания Databricks получают эти наборы изменений из Oracle через JDBC и обновляют таблицы в Delta Lake. Такая схема имеет два основных недостатка [1]:
- увеличение нагрузки на экземпляр Oracle, что ограничивает способ и периодичность выполнения ETL-заданий;
- оптимальная частота обновления возможна лишь ночью из-за ограничений параллелизма в обычных таблицах Parquet.
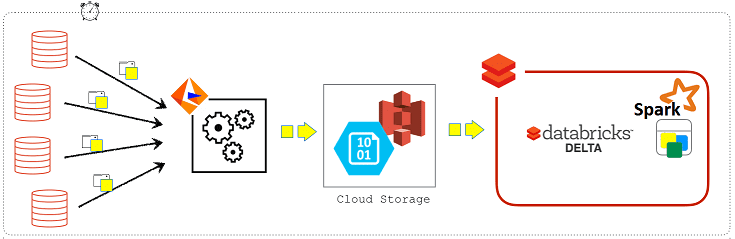
Благодаря Databricks Delta Lake CDC-конвейер теперь может обновляться чаще, передавая данные по следующему сценарию:
- Informatica записывает наборы изменений в формате Parquet непосредственно в AWS S3;
- Spark-задания Databricks запускаются с нужной частотой обновления, например, каждые 15 минут, для чтения наборов изменений и обновления целевых таблиц Databricks Delta Lake.
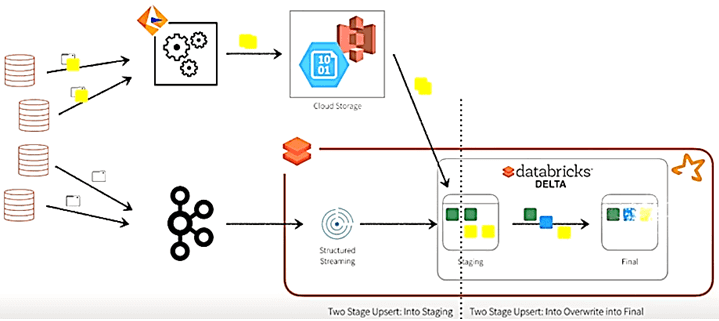
Такой конвейер можно также использовать для чтения CDC-записей из Kafka, чтобы передавать потоковые изменения данных в Delta Lake с помощью Spark-заданий. Основная идея такого подхода в наличии промежуточной таблицы (T_STAGING), где накапливаются все обновления для отдельного набора записей, и итоговой таблицы (T_FINAL) с текущим обновленным snapshot’ом, который пользователи могут запрашивать. Для каждого периода обновления Spark-задание запускает два оператора INSERT:
- первый раз, чтобы прочитать наборы изменений из S3 или Kafka в этот период обновления и вставить (Insert) эти изменения в промежуточную таблицу;
- вставка с перезаписью (Insert Overwrite), чтобы получить текущую версию каждого набора записей из промежуточной таблицы и перезаписать их в итоговой таблице.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Поскольку в облачных хранилищах данных и HDFS записи хранятся в файлах, единицей обновления является файл. В случае Databricks Delta это файлы Parquet-формата. Когда требуется обновить запись, Spark-заданию необходимо прочитать и перезаписать весь файл. Чтобы сократить объем обрабатываемых данных и повысить вычислений, важно локализовать обновления в как можно меньшем количестве файлов. Для этого промежуточная и итоговая таблицы разделяются столбцом, который минимизирует количество строк, затронутых CDC. Далее этот разделяющий столбец предоставляется в спецификации PARTITION (Azure или AWS), чтобы позволить Databricks Delta вставлять записи в правильные разделы промежуточной таблицы T_STAGING.
Еще более оптимизировать такой конвейер помогут следующие способы:
- Сокращение разделов (Partition Pruning) при вставке с перезаписью оптимизатор запросов в Databricks Delta просматривает спецификацию PARTITION и список IN в условии WHERE, чтобы читать и перезаписывать только те разделы, которые следует обновить. Благодаря этому можно почти вдвое сократить затронутую часть таблицы, локализуя обновления как для итоговой таблицы T_FINAL, так и для запроса SELECT к промежуточной таблице T_STAGING.
- Пропуск данных (Data Skipping) с индексами ZORDER при запросе итоговой таблицы T_FINAL с условием WHERE. Пользовательская команда оптимизации такого запроса по 2-м столбцам (COL1, COL2) выглядит так: OPTIMIZE T_FINAL ZORDER BY (COL1, COL2). В отличие от составных индексов в СУБД, Z-индекс не смещается в сторону запросов с фильтрами по префиксам из списка индексированных столбцов. А если в запросе также есть фильтр по столбцу раздела, то можно использовать также и способ Partition Pruning, чтобы сократить количество файлов, к которым выполняется обращение.
Как реализовать эти способы в Apache Spark SQL, подробно описано в источниках [1, 2]. А на практике понять, как самостоятельно строить эффективные конвейеры аналитики больших данных с Apache Kafka и Spark, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для разработчиков
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
[elementor-template id=»13619″]
Источники
- https://databricks.com/blog/2018/10/29/simplifying-change-data-capture-with-databricks-delta/
- https://databricks.com/session_na20/simplify-cdc-pipeline-with-spark-streaming-sql-and-delta-lake

