
Мы уже рассказывали, как машинное обучение (Machine Learning) и большие данные (Big Data) помогают бизнесу сделать свои маркетинговые кампании персональными и оптимизировать рекламный бюджет. В этой статье рассмотрим, как метеоусловия влияют на маркетинг и каким образом бизнес может заработать на использовании данных об этих внешних условиях. Как погода влияет на...
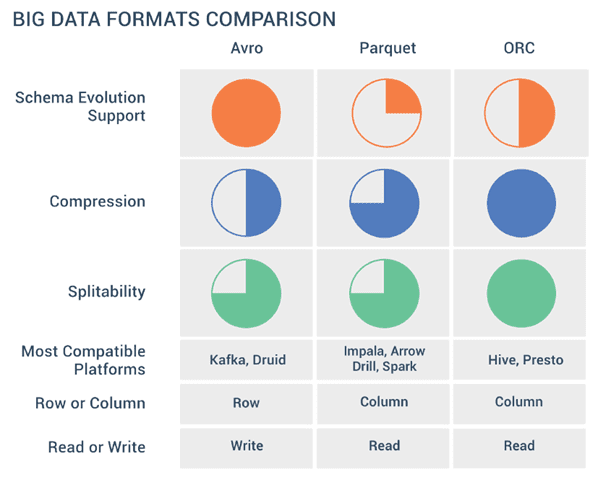
Продолжая разговор про форматы Big Data файлов, сегодня мы рассмотрим разницу между линейными и колоночными типами, а также расскажем о том, как выбирать между AVRO, Sequence, Parquet, ORC и RCFile при работе с Apache Hadoop, Kafka, Spark, Flume, Hive, Drill, Druid и других средствах работы с большими данными. Итак, форматы...

Мы уже упоминали формат Parquet в статье про Apache Avro, одну из наиболее распространенных схем данных Big Data, часто используемую в Kafka, Spark и Hadoop. Сегодня рассмотрим более подробно, чем именно хорошо Apache Parquet и как он отличается от других форматов Big Data. Что такое Apache Parquet и как он...
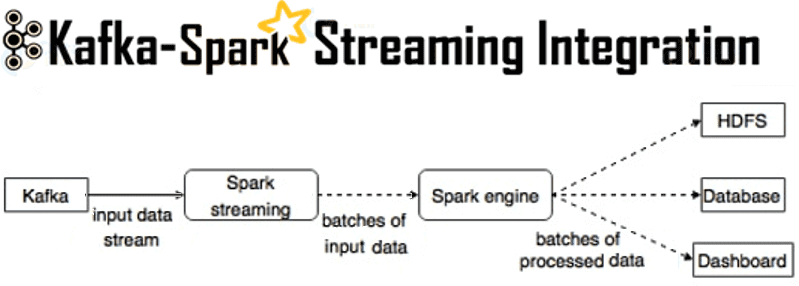
Мы уже рассказывали, зачем нужна интеграция Apache Kafka и Spark Streaming. Сегодня рассмотрим, как технически организовать такой Big Data конвейер по непрерывной обработке потоковых данных в режиме реального времени. Способы интеграции Наладить двустороннюю связь между Apache Kafka и Spark Streaming возможны следующими 2-мя способами: получение сообщений через службу синхронизации Zookeeper...
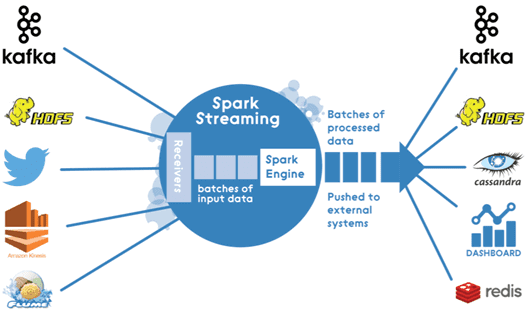
В этой статье мы рассмотрим архитектуру Big Data конвейера по непрерывной обработке потоковых данных в режиме реального времени на примере интеграции Apache Kafka и Spark Streaming. Что такое Spark Streaming и для чего он нужен Spark Streaming – это надстройка фреймворка с открытым исходным кодом Apache Spark для обработки потоковых...
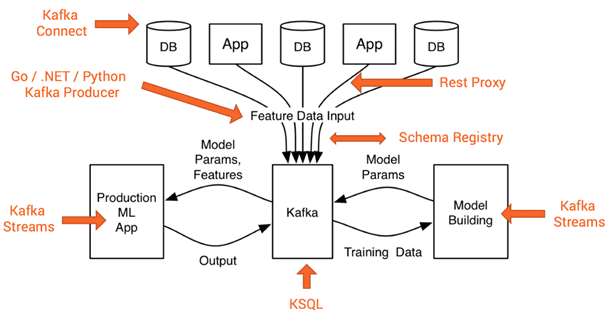
Рассмотрев основы Apache Kafka, сегодня мы расскажем о месте этого распределённого брокера сообщений в архитектуре Big Data систем. Читайте в нашей статье, какие компоненты Кафка обеспечивают ее использование в программных продуктах машинного обучения (Machine Learning, ML), интернете вещей (Internet Of Things, IoT), системах бизнес-аналитики (Business Intelligence, BI), а также других...
В прошлом месяце Apache Spark выпустили свою последнюю новую версию Apache Spark 2.4.0. Это пятая версия в серии 2.x. В новой версии Apache Spark появляется метод Барьерной синхронизации для лучшей интеграции с системами глубокого обучения. Apache Spark 2.4.0 содержит более 30 встроенных функций и функций более высокого порядка для работы...