
Чтобы показать, насколько разной бывает аналитика больших данных, сегодня рассмотрим кейс международной компании Spidertracks, которая с помощью технологий Big Data создает ИТ-решения для отслеживания, связи и управления безопасностью воздушных судов. Читайте далее, почему для потоковой обработки событий был выбран Kinesis Analytics for SQL, а не конвейер из Apache Kafka и Spark Streaming, а также способны ли типовые инструменты и готовые облачные сервисы избавить от необходимости разрабатывать уникальные приложения.
Требования к механизму потоковой генерации событий: постановка задачи с точки зрения бизнеса и технологий
Сегодня Spidertracks из стартапа, основанного в 2007 году, стала одним из ведущих поставщиков ИТ-решений для авиационной безопасности. Продукты компании помогают отслеживать местоположение тысячи самолетов по всему миру в реальном времени, а также извлекать из полетных данных ценные для бизнеса сведения. В частности, определить типичный полет в условиях непредвиденных обстоятельств, которые инициируют так называемые события безопасности и должны быть оперативно обработаны, чтобы предупредить авиакатастрофу [1]. В этой статье мы рассмотрим технические аспекты механизма генерации событий: требования, выбор технологии потоковой обработки, а также проблемы и ограничения.
Основными компонентами Big Data системы полетного трекинга являются следующие [2]:
- источник данных о важных показателях полета, как ориентация и местоположение самолета, захватывается с воздушного судна во время полета и передается в Amazon Web Services (AWS);
- конфигурации клиента, например, допустимое значение тангажа при заданной высоте во время полета, хранятся в базе данных NoSQL;
- механизм генерации событий объединяет конфигурации клиента с метриками входящих полетов, чтобы решить, нужно ли генерировать событие безопасности;
- место назначения, куда сгенерированные события помещаются для использования.
Таким образом, основными требованиями к механизму генерации событий были следующие [2]:
- потоковая обработка, максимально близкая к режиму real time, т.е. низкая временная задержка (latency) между получением данных в AWS и событиями, доступными для использования;
- движок должен обеспечивать сохранение состояний (stateful), чтобы генерировать события только, если текущая входящая строка соответствует критериям конфигурации, а предыдущая – нет. Это гарантирует, что события не будут генерироваться, когда пороговые значения уже достигнуты. Кроме того, во время полета воздушное судно не будет находиться в зоне полного покрытия, поэтому данные могут поступать в разреженном виде. Однако, конвейер их обработки должен вести себя так, будто данные всегда доступны в реальном времени;
- поддержка AWS;
- возможность быстро разрабатывать и проверять гипотезы;
- низкие эксплуатационные расходы;
- надежность.
Выбор Big Data технологии: Kinesis Analytics for SQL vs Spark Streaming и Kafka Streams
Вышеотмеченным критериям соответствовали несколько вариантов:
- Spark Streaming, который можно запустить в Amazon Web Services через AWS Glue (без сервера) или AWS EMR (управляемый кластер);
- Apache Flink, который позволяет обрабатывать данные в действительно реальном времени, в отличие от микро-пакетного подхода Spark Streaming. Apache Flink также работает на AWS EMR (управляемый кластер), а без сервера на AWS Kinesis Analytics.
- Kafka Streams является отличным решением, когда весь конвейер организован через Kafka. Однако, в случае Spidertracks это было не так.
- Kinesis Analytics for SQL – облачный AWS-сервис для анализа потоковых данных в реальном времени с помощью SQL. В отличие от других кандидатов, Kinesis Analytics for SQL – это не фреймворк, а облачная служба, где потоковая обработка выполняется через SQL-запросы, а разработку программного кода.
Инженеры Spidertracks решили использовать Kinesis Analytics for SQL, аргументировав свой выбор [2]:
- приложения Apache Flink в основном разрабатываются на Java, а исходный стек компании построен на Python. Это ограничение не устраняет даже библиотека Pyflink, которая позволяет разрабатывать Flink-приложения на Python, т.к. она недоступна через бессерверную службу на AWS;
- разработка собственных приложений Spark Streaming и их работа в облаке AWS через AWS Glue менее рентабельны, чем запуск потоковых приложений через Kinesis Analytics;
- бессерверный (serverless) подход Kinesis Analytics for SQL позволяет ускорить цикл выпуска продукта на рынок (TTM, Time To Market), предоставляя возможность фокусироваться на логике генерации событий, а не поддержке платформы;
- автоматическое масштабирование Kinesis Analytics в зависимости от объема и пропускной способности обрабатываемых данных.
Блеск и нищета конвейера потоковой аналитики больших данных на AWS Kinesis
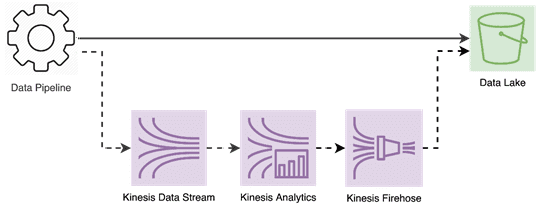
Изначально источник данных Spidertracks представлял собой корпоративное озеро данных (Data Lake) на AWS S3, где сохранялись для анализа собранные с воздушного судна показатели полета. Было решено изменить этот конвейер, добавив параллельно шаг для отправки исходных данных в Data Lake, а также в Kinesis Analytics для генерации событий. Kinesis Analytics может считывать данные из двух потоковых источников: Kinesis Data Streams и Kinesis Data Firehose. Поэтому пришлось расширить конвейер данных, чтобы передать их в Kinesis Data Streams, а затем автоматически в Kinesis Analytics. Kinesis Data Streams предлагает меньшую задержку, чем Kinesis Data Firehose, и позволяет более оптимально балансировать рабочую нагрузку. В свою очередь, Kinesis Data Firehose отлично подключается к AWS S3, позволяя буферизовать данные перед их загрузкой в Data Lake. Таким образом можно контролировать размер файла и объем передаваемых данных. А за этап преобразование отвечает Kinesis Analytics, где организована логика создания настраиваемых событий.
Одно или несколько приложений Kinesis Analytics сопоставляют входящие данные с потоком внутри приложения. Объект input_stream извлекает данные из Kinesis Data Streams через механизм SQL-запросов. Затем выполняется проверка, должно ли событие быть сгенерировано, путем чтения конфигураций клиентов, и запись вывод в поток output_stream. Объект output_stream сопоставляется с потоком доставки Kinesis Firehose, который отвечает за запись в озеро данных.
Основными проблемами вышеописанного конвейера были следующие [3]:
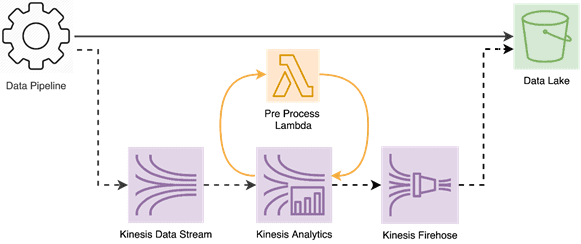
- увеличение нагрузки из-за особенностей масштабирования Kinesis Data Stream путем добавления разделов (шардов, shard), каждый из которых хранится на отдельном экземпляре сервера базы данных для распределения нагрузки. В Kinesis Data Stream шард может считывать до 2 МБ/с и записывать 1 МБ/с. Увеличение числа шардов повышает стоимость услуги в целом. Решить эту проблему можно с помощью сжатия, но Kinesis Data Analytics не может считывать сжатые данные. Поэтому потребовался промежуточный этап между ним и Kinesis Data Streams. Для этого была использована встроенная возможность Kinesis Data Analytics для вызова лямбда-функции предварительной обработки, т.е. распаковки сжатых данных.
- чтение конфигураций клиентов в Kinesis Data Analytics и их объединение с входящими потоковыми данными, чтобы решить, генерировать событие или нет. Сохранение конфигураций клиентов в файле S3 не подойдет, т.к. эти данные постоянно обновляются из внешнего интерфейса. Непрерывное обновление файла S3 повлечет проблемы с обработкой параллелизма и конечной согласованности. Помимо того, что поток становится недоступным во время обновления, он также нарушает отслеживание состояния приложения. Это означает, что в случае оконных операций, приложение теряет отслеживание предыдущих записей и может повести себя непредсказуемо.
Нагрузочное тестирование этого конвейера данных показало, что несколько шардов Kinesis Data Stream могут отлично работать с одним приложением Kinesis Analytics. В свою очередь, несколько приложений Kinesis Analytics также без проблем с параллелизмом считывают данные из одного сегмента Kinesis Data Stream. Тем не менее, Big Data инженеры Spidertracks в будущем планируют все-таки заменить Kinesis Data Analytics for SQL для расширения клиентских возможностей конфигурирования событий. Предоставить клиентам полный контроль над конфигурацией событий невозможно только с помощью чистого SQL, поэтому придется использовать для этого Spark Streaming или Apache Flink. Кроме того, бессерверная облачная служба хороша с точки зрения минимальных затрат на обслуживание, но требует более высоких расходов по сравнению с оптимизацией, которую можно получить, запустив собственный кластер [3].
Таким образом, рассмотренный кейс компании Spidertracks в очередной раз показал преимущество разработки собственных решений для нетривиальной аналитики Big Data даже при наличии готовых облачных сервисов и типовых инструментов. О другом интересном примере аналитики больших данных с помощью Apache Spark читайте в нашей новой статье.
Как спроектировать и реализовать эффективные конвейеры аналитики больших данных с Apache Kafka, Spark и Hadoop, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для разработчиков
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Построение конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
Источники
- https://www.spidertracks.com/company/about-us
- https://towardsdatascience.com/real-time-analytics-in-the-aviation-industry-part-1-f90418cd7dc3
- https://towardsdatascience.com/real-time-analytics-in-the-aviation-industry-part-2-leveraging-kinesis-analytics-for-sql-64ae7240cfe

