
Чтобы дополнить наши курсы по Spark для разработчиков распределенных приложений и инженеров данных практическими примерами, сегодня рассмотрим кейс американской ИТ-компании ThousandEyes, которая разрабатывает программное обеспечение для анализа производительности локальных и глобальных сетей. Читайте далее, как создать надежный конвейер и устойчивое озеро данных (Data Lake) для быстрой аналитики Big Data в...

Продолжая вчерашний разговор про оптимизацию Spark-приложений в облачном кластере Amazon Web Services, сегодня рассмотрим типовую последовательность действий по конфигурированию заданий и настройке узлов для снижения затрат на аналитику больших данных. А также разберем, какие проблемы с памятью исполнителей могут при этом возникнуть, и как инженеру Big Data их решить. Еще...

В рамках обучения администраторов Apache Hadoop и инженеров Big Data, сегодня поговорим про стоимость аналитики больших данных с помощью Spark-приложений в облачном кластере Amazon Web Services и способы снижения этих затрат за счет конфигурирования заданий и настройки узлов. Читайте в этой статье, как число процессорных ядер в исполнителях Spark-заданий формирует...
В этой статье поговорим про KSQL на примере кейса компании американской компании Pluralsight, которая предлагает различные обучающие видео-курсы для разработчиков ПО, ИТ-администраторов и творческих профессионалов. Читайте далее, как использовать Apache Kafka с Kubernetes для построения надежных систем потоковой аналитики больших данных, а также чем ksqlDB отличается от KSQL. Apache Kafka...

Хорошие курсы инженеров данных – это не просто обучение отдельной Big Data технологии, такой как Apache Hadoop, Spark или Kafka, а жизненные примеры их практического использования в реальном бизнесе. Поэтому сегодня мы приготовили для вас кейс оптимизации стоимости и скорости OLAP-аналитики больших данных в облачном Delta Lake на Amazon Web...

Чтобы показать, насколько разной бывает аналитика больших данных, сегодня рассмотрим кейс международной компании Spidertracks, которая с помощью технологий Big Data создает ИТ-решения для отслеживания, связи и управления безопасностью воздушных судов. Читайте далее, почему для потоковой обработки событий был выбран Kinesis Analytics for SQL, а не конвейер из Apache Kafka и...
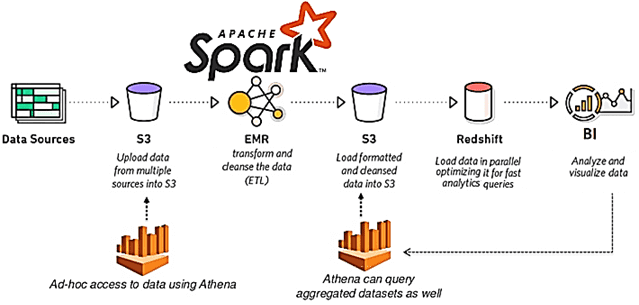
Мы уже рассказывали, почему качество данных является важнейшим аспектом разработки и эксплуатации Big Data систем. Приемлемое для эффективного использования качество массивов информации достигается не только с помощью процессов подготовки датасета к машинному обучению и профилирования данных, но и за счет их согласования. Читайте далее, что такое Data reconciliation, зачем это...

Сегодня поговорим про особенности транзакций в Apache Spark, что такое фиксация заданий в этом Big Data фреймворке, как она связано с протоколами экосистемы Hadoop и чем это ограничивает переход в облако с локального кластера. Читайте далее, как найти компромисс между безопасностью и высокой производительностью, а также чем облачные хранилища отличаются...

Чтобы добавить в наш новый курс по Apache Kafka для разработчиков еще больше практических примеров, сегодня мы приготовили для вас кейс немецкой железнодорожной компании Deutsche Bahn AG. Читайте далее, почему приложения Kafka Streams заменили Apache Storm и как крупнейшая транспортная компания Германии построила собственную информационную платформу на базе Apache Kafka,...

Интерактивная аналитика больших данных - одно из самых востребованных и коммерциализированных приложений для технологий Big Data. В этой статье мы рассмотрим, как крупный британский ритейлер запустил цифровую трансформацию своей ИТ-архитектуры, уходя от традиционного DWH с пакетной обработкой к событийно-стриминговой облачной платформе на базе Apache Kafka и Snowflake. Зачем модному ритейлеру...