 545
545 
Содержание
В этой статье поговорим про KSQL на примере кейса компании американской компании Pluralsight, которая предлагает различные обучающие видео-курсы для разработчиков ПО, ИТ-администраторов и творческих профессионалов. Читайте далее, как использовать Apache Kafka с Kubernetes для построения надежных систем потоковой аналитики больших данных, а также чем ksqlDB отличается от KSQL.
Apache Kafka как основа всего: потоковая аналитика событий и сущностей
Компания Pluralsight использует Apache Kafka в качестве платформы межкомандного и межсервисного взаимодействия, чтобы обеспечить асинхронную коммуникацию слабосвязанных, но взаимозависимых сервисов. Поскольку веб-службы HTTP синхронны, возникает необходимость в очередях сообщений. Непосредственно для обмена сообщениями между командами Pluralsight применяет RabbitMQ и его протокол AMQP. Однако, это не полностью закрывает потребность в межсервисной коммуникации и, тем более, в потоковой аналитики больших данных. Поэтому в дополнение к RabbitMQ Pluralsight также используют Kafka, которая по архитектуре намного ближе к распределенной файловой системе или базе данных, чем к традиционной очереди сообщений. Подробнее о том, чем Kafka отличается от RabbitMQ, мы разбирали здесь. Дополнительным преимуществом Apache Kafka является возможность выполнения различных операции обработки потоков данных: фильтрация, соединения, агрегация и сопоставления с помощью типового инструментария SQL-запросов в виде KSQL.
Pluralsight использует вариант Kafka от Confluent, а потому для потоковой аналитики больших данных применяет ksqlDB, который раньше назывался KSQL. Основанная на Kafka Streams, ksqlDB предоставляет удобный API-интерфейс, позволяя работать с потоками Big Data аналитикам и Data Scientist’ам, а не только инженерам данных. Кроме того, сотрудники компании Pluralsight посчитали API-интерфейс ksqlDB более понятным для практического использования по сравнению с Apache Spark Streaming и отметили простоту его развертывания в AWS EMR.
Apache Kafka обеспечивает для Pluralsight высокую надежность и горизонтальную масштабируемость, а также синхронизацию множества разных потребителей с заданным источником данных. Для этого все события и сущности для анализа бессрочно хранятся в топиках Kafka. Сущности описывают текущее состояние пользовательского поведения: сколько каналов у этого пользователя, какой контент он просмотрел и пр. А события отвечают за свершившиеся факты, например, пользователь начал новый образовательный курс, изменил свои интересы, искал какой-то контент и т.д. При этом, в отличие от типичной СУБД, можно настроить потребителей непосредственно в топиках Kafka на действия, связанные с сообщениями по мере их использования.
Раньше непосредственно сама аналитика данных в Pluralsight выполнялась через традиционные SQL-инструменты материализации данных, такие как Postgres, куда копировалось большинство данных из топиков Kafka. Дальнейшие аналитические запросы выполнялись именно там. Однако по мере роста топиков и потребностей в аналитике компания перешла на озеро данных (Data Lake) AWS Athena/S3. Оно предоставляет механизм запросов наподобие Apache Presto, без необходимости управлять экземплярами EC2. Даже с учетом того, что AWS S3 не слишком подходит для управления обновлениями записей Kafka, среда S3/Athena отлично работает для топиков с событиями. Кроме того, поскольку Pluralsight использует платформу Kafka от Confluent, это предоставляет преимущества ksqlDB [1], отличия которого от прежнего KSQL мы рассмотрим далее.
Что такое ksqlDB и чем это отличается от KSQL
В ноябре 2019 года компания Confluent, которая продвигает коммерческие решения на основе Apache Kafka, выпустила новый релиз KSQL, настолько важный, что назвала его именем ksqlDB. Как и KSQL, ksqlDB остается в свободном доступе и лицензируется сообществом, скачать его можно абсолютно бесплатно прямо с GitHub. Самими важными обновлениями KSQL в ksqlDB стали две новые функции [2]:
- запросы на вытягивание (Pull queries), которые интегрируют традиционный поиск в базе данных поверх материализованных таблиц с событиями с непрерывного потока данных. Они позволяют извлекать данные в определенный момент времени и/или запрашивать состояние. Например, приложению для совместных поездок необходимо постоянно получать информацию о текущей позиции водителя (push-запрос) и искать текущее значение цены поездки (pull-запрос). ksqlDB позволяет подписываться на местоположение по мере его изменения и постоянно передавать этот поток значений в приложение, объединяя традиционный тип запросов потоковой обработки KSQL с поиском по сохраненным данным, как в традиционной базе данных.
- управление коннекторами (Connector management) в рамках единого интерфейса вместо нескольких разных (Kafka, Connect и KSQL). Это важно, когда данные для аналитической обработки отсутствуют в Kafka, а находятся во внешней системе (одна или несколько традиционных СУБД, API приложений SaaS и пр.). С помощью коннекторов Kafka Connect можно получать нужные потоки данных и отправлять их в топики Kafka. Таким образом, приходилось работать в нескольких системах: Kafka, Connect и KSQL, интерфейсы которых отличаются друг от друга. ksqlDB позволяет напрямую управлять и запускать коннекторы, для работы с Kafka Connect.
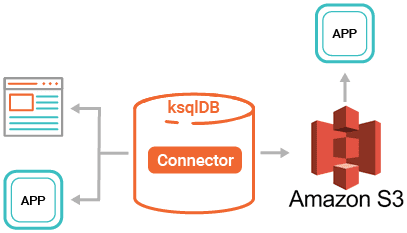
Обе этих новых функции ksqlDB активно используются в Pluralsight для создания топиков Kafka через коннекторы из Postgres через Debezium или из MQTT для IoT-приложений, к примеру, в Arduino-устройствах. В частности, коннектор приемника AWS S3 применяется для передачи данных из Kafka, чтобы обращаться к озеру данных в стиле MapReduce для быстрых запросов. Так можно быстро развернуть Kafka и ksqlDB через Docker и передать данные о геолокации в ksqlDB следующим образом: смартфон -> MQTT -> Kafka -> ksqlDB. Упоминание про Docker не случайно: далее мы рассмотрим, как Pluralsight использует контейнеры для развертывания и тестирования распределенных приложений.
DevOps в потоковой аналитике Big Data: Kubernetes и шаблоны ksqlDB
Самая популярная DevOps-технология, Kubernetes упрощает такое развертывание и упаковку, поэтому в Pluralsight был создан собственный кластер, чтобы предоставить каждой продуктовой команде пространство имен для выделения нужных ресурсов. Для создания шаблонов и развертывания приложений в Kubernetes через манифест yaml используется инструментарий helm или kustomize. Шаблон kustomize для ksqlDB помогает предоставить информацию о требованиях к памяти, деталях Kafka-кластера, а также роли IAM для доступа к корзине приемника AWS S3.
Кроме того, веб-интерфейс Kubernetes предоставляет подробную информацию для проверки или обновления конфигурации, служб и журналов для различных приложений, развертываемых командой, снижая порог входа в технологию. Так, благодаря наличию шаблонизатора и мониторинга пользовательского интерфейса кластер ksqlDB на K8S позволяет создавать коннекторы, выполнять потоковые запросы и фокусироваться на непосредственно аналитики больших данных, не беспокоясь о выделении ресурсов.
Однако, при том, что ksqlDB упрощает потоковую аналитику больших данных с помощью типичного синтаксиса SQL, возможность группировки зависит от размера потока и памяти пода Kubernetes. Это ограничение обусловлено тем, что, в отличие от типичного SQL, с помощью ksqlDB создаются программы, которые непрерывно работают с неограниченными потоками событий и останавливаются только при их явном прекращении.
Наконец, отметим еще один кейс применения Apache Kafka в Pluralsight для OLAP-аналитики больших данных, подобно тому, как мы рассматривали здесь. При моделировании многомерных данных для построения корпоративных хранилищ и BI-витрин часто требуется создавать денормализованные таблицы, чтобы обеспечить легкий доступ к стандартным показателям и измерениям, а также упростить JOIN-соединения. Это можно сделать с помощью производных топиков (derived topic), в которых объединяются стандартные пользовательские атрибуты или метрики из нескольких топиков, чтобы облегчить построение моделей, эксперименты и исследование продуктов. Создать новый топик Kafka из потока так же просто, как установить параметр при его создании [1]. Завтра мы рассмотрим, чем ksqlDB отличается от Kafka Streams и каковы основные ограничения этого перезапуска KSQL.
Как еще использовать Apache Kafka для потоковой аналитики больших данных, разрабатывать быстрые распределенные приложения и эффективно администрировать кластера, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

