 736
736 
Содержание
Чтобы добавить в наш новый курс по Apache Kafka для разработчиков еще больше практических примеров, сегодня мы приготовили для вас кейс немецкой железнодорожной компании Deutsche Bahn AG. Читайте далее, почему приложения Kafka Streams заменили Apache Storm и как крупнейшая транспортная компания Германии построила собственную информационную платформу на базе Apache Kafka, Cassandra и Kubernetes в облачном кластере Amazon Web Services.
Зачем железнодорожникам Big Data: постановка задачи с точки зрения бизнеса
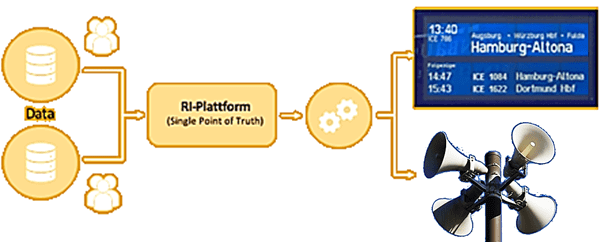
Deutsche Bahn – это основной железнодорожный оператор Германии, акционерное общество со стопроцентным государственным участием [1], которое каждый день обслуживает около 5,7 миллионов пассажиров, управляя 24 тысячами поездов. Почти каждому клиенту требуются сведения о поездке, такие как время отправления и прибытия, платформа, место в очереди при ожидании поезда и прочая важная информация. Необходимо обеспечить полное соответствие данных, отображаемых на дисплеях станции, в мобильном приложении DB Navigator и на веб-сайте. Для этого было решено разработать новую систему, RI-Plattform – информационное приложение для пассажиров, которое будет выступать единым источником истины, обеспечивая все информационные каналы Deutsche Bahn.
С учетом ежедневного количества пассажиров и поездов, система должна быстро и надежно обрабатывать около 180 миллионов событий в сутки. Чтобы обеспечить обработку такого большого объема данных с высокой скоростью, понадобятся технологии Big Data для потоковой обработки событий. Какие из них предпочел Deutsche Bahn и почему, мы рассмотрим далее.
3 плюса Apache Kafka для Deutsche Bahn
Сначала Big Data специалисты Deutsche Bahn попробовали Apache Storm для потоковой обработки событий. Несмотря на то, что этот фреймворк позволяет обрабатывать большие данные в режиме реального времени, на практике сотрудники компании столкнулись с некоторыми сложностями в его развертывании, эксплуатации и создания приложений. Поэтому вместо Storm было принято решение использовать Apache Kafka, в частности ее клиентскую библиотеку Kafka Streams для разработки распределенных приложений. Это значительно упростило реализацию простых сценариев с предметно-ориентированным языком (DSL), а также позволило решать гораздо более сложные задачи с помощью Processor API. Кроме того, данная технология существенно улучшила жизненный цикл разработки и снизило инфраструктурную сложность среды.
Благодаря Kafka Streams на 90% было уменьшено время, необходимое сервису объявлений платформы для обработки ежедневного расписания за счет ее локального выполнения вместо отправки запросов в удаленную базу данных. Теперь этот процесс занимает всего 2 минуты вместо 20, как было ранее. Поскольку Apache Kafka работает по модели «издатель-подписчик», она отлично поддерживает современный микросервисный подход к проектированию и реализации программного обеспечения. Такая архитектура активно внедряется в Deutsche Bahn с помщью Kafka. В частности, в зависимости от бизнес-кейса события попадают в Kafka с необходимым временем хранения. Даже вновь созданный микросервис сразу начинает работать, считывая нужные данные из Kafka, чтобы немедленно обработать новую информацию. Эта архитектура потоковой передачи событий упростила использование дополнительных источников информации. Например, создан микросервис, который использует данные датчиков со станционных платформ для обнаружения прибытия поезда и запускает объявление через громкоговорители станции.
Подчеркнем, что в случае Deutsche Bahn очень важна потоковая передача событий с низкой временной задержкой. Даже совсем небольшое опоздание доставки информации влияют на точность расписания и своевременность объявлений на пассажирской платформе. Во время нормальной работы Apache Kafka обеспечивает минимальную задержку. Однако во время развертывания приложений Kafka Streams перебалансировка вызывает эффект остановки на короткий момент времени. Уменьшить влияние ребалансировки помог новый протокол управления группами статического членства (Static Membership group management protocol), доступный в Apache Kafka версии 2.3.0 [2].
Напомним, статическое членство — это усовершенствование текущего протокола перебалансировки, ориентированное на сокращение времени простоя, вызванного чрезмерными и ненужными перебалансировками для общих клиентских реализаций Apache Kafka. Это относится к потребителям Kafka, Kafka Connect и Kafka Streams. Статическое членство, в отличие от динамического, направлено на сохранение идентичности членов в нескольких поколениях группы, чтобы повторно использовать существующую информацию о подписке и сделать «старых» участников «узнаваемыми» для координатора. Static Membership представляет новую конфигурацию потребителя под названием group.instance.id, которая настраивается пользователями для уникальной идентификации своих экземпляров потребителей. Хотя назначенный координатором идентификатор члена теряется во время перезапуска, координатор все равно распознает этого члена на основе предоставленного идентификатора экземпляра группы в запросе на присоединение. Статическое членство очень удобно для настройки облачных приложений, поскольку современные технологии развертывания, такие как, например, Kubernetes, очень автономны для управления работоспособностью приложений. В частности, Kubernetes может легко отключить экземпляр плохо работающего потребителя и запустить новый, используя тот же идентификатор. При этом продолжается проверка состояния клиентов координатором группы [3].
Кстати, Kubernetes имеет прямое отношение к рассматриваемому кейсу Deutsche Bahn, поскольку именно эта платформа контейнерной виртуализации используется в компании наряду с Apache Kafka и прочими технологиями Big Data, о чем мы поговорим далее.
Результаты тестирования и развертывания в production
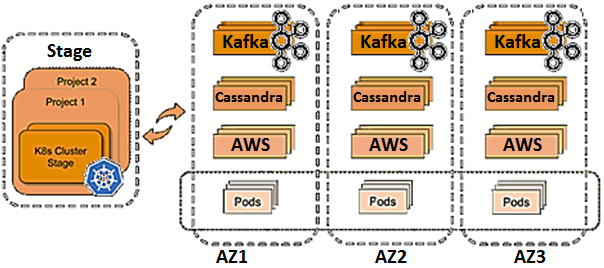
В создании разработке RI-Plattform участвовало 110 человек, объединенных в 13 Scrum-команд. Стек технологий системы включает Apache Kafka, Cassandra и Kubernetes, работающие на Amazon Web Services (AWS) в трех зонах доступности. Было разработано около 100 микросервисов, которые используют Confluent Platform в качестве платформы потоковой передачи событий для связи друг с другом и доступа к 180 миллионам событий, ежедневно генерируемых и обрабатываемых в RI-Plattform.
Также была создана собственная тестовая среда с примерно 3 миллионами случаев, которые используются перед развертыванием в production. Согласно DevOps, в Deutsche Bahn каждый день выполняется развертывание 4-8 раз, соблюдая принципы CI/CD.
В рамках пилотного проекта на 80 станциях по всей Германии RI-Plattform запущена с 2018 года. Apache Kafka и Confluent Platform помогли достичь 99,9% доступности. В первый год было менее семи часов простоя, и это касалось только части системы, а не всего приложения. В декабре 2019 года разработанная Big Data система обслуживала только междугородние поездки, с ожидаемым включением внутригородских маршрутов. После этого добавления нагрузка на Apache Kafka увеличится примерно в 20 раз [2]. Поэтому сотрудники Deutsche Bahn совместно с дата-инженерами компании Confluent прорабатывают возможность перехода в облачный Big Data сервис Kafka — Confluent Cloud, о котором мы частично рассказывали здесь.
Завтра мы продолжим разговор про Apache Kafka с точки зрения инженера данных и рассмотрим, как в эту Big Data платформу в режиме реального времени загрузить данные из множества разных источников с помощью ETL-инструмента Qlik Replicate.
А разобраться со всеми особенности администрирования кластера Apache Kafka и разработки приложений потоковой аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://ru.wikipedia.org/wiki/Deutsche_Bahn
- https://www.confluent.io/blog/deutsche-bahn-kafka-and-confluent-use-case/
- https://www.confluent.io/blog/kafka-rebalance-protocol-static-membership/

