
В рамках обучения администраторов Apache Hadoop и инженеров Big Data, сегодня поговорим про стоимость аналитики больших данных с помощью Spark-приложений в облачном кластере Amazon Web Services и способы снижения этих затрат за счет конфигурирования заданий и настройки узлов. Читайте в этой статье, как число процессорных ядер в исполнителях Spark-заданий формирует расходы на облако AWS и каким образом можно повысить эффективность использования ресурсов, в т.ч. с экономической точки зрения.
От чего зависят расходы на Spark-кластер в облаке AWS: краткий ликбез по экономике Big Data
Чтобы снизить стоимость выполнения Spark-заданий в облаке AWS, рассмотрим, из чего складываются эти затраты. Итак, каждый раз, когда дата-инженер отправляет на исполнение Spark-задание, он задает 4 основных параметра, которые и определяют эффективность его выполнения [1]:
- —num-executors – число исполнителей для обработки данных;
- —executor-cores — количество ядер Spark для каждого исполнителя, которые выполняют всю работу по обработке данных. Например, 12 исполнителей с 5 ядрами Spark в каждом соответствуют 60 ядрам Spark, обрабатывающим данные.
- —executor-memory – пул памяти для ядер Spark;
- —driver-memory – пул памяти для драйвера, который координирует обработку данных всех исполнителей.
Исполнители назначаются отдельным экземплярам AWS EC2 – узлам кластера до тех пор, пока не будет использована физическая память на этом узле. Когда новый исполнитель не помещается в доступной памяти узла, разворачивается новый узел и добавляется в кластер для размещения этого исполнителя. Каждый узел имеет фиксированное количество процессоров, доступных для обработки данных ядрами Spark. Хотя исполнители не могут превышать доступную физическую память узла, у них может быть больше ядер Spark, чем доступных процессоров на этом узле.
Когда количество ядер Spark всех исполнителей на узле больше количества доступных ЦП, происходит дискретизация по времени, поскольку каждое ядро Spark ожидает своей очереди на обработку перегруженными ЦП. Такое разделение весьма неэффективно из-за переключения контекста и его следует избегать. И наоборот, если количество ядер Spark всех исполнителей на узле меньше числа доступных ЦП, то ресурсы узла будут также использоваться неэффективно. Поэтому оптимальным вариантом будет совпадение количества ядер Spark для всех исполнителей на узле с числом доступных CPU.
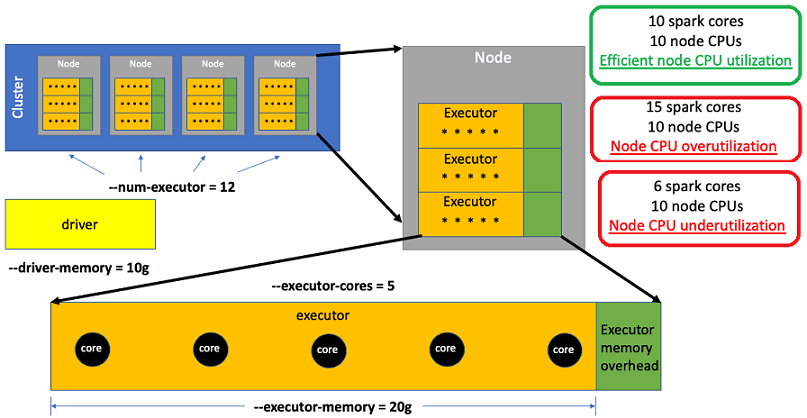
Итак, AWS берет посекундную оплату за каждый узел кластера, на котором выполняется задание Apache Spark. Поэтому, чтобы сократить расходы на облако AWS при выполнении Spark-заданий, нужно убедиться, что исполнители настроены эффективно используют все доступные ресурсы (ЦП узла) без разделения по времени. Таким образом, экономия достигается за счет сокращения числа используемых узлов. Например, практический опыт дата-инженеров американской туристической компании Expedia Group показывает, что тщательная настройка (конфигурирование) Spark-заданий позволяет сократить расходы на облако AWS на 60%. Специалисты Big Data отмечают, что проблема с размещением нужного количества ядер Spark на узле заключается в зависимости конфигурационных настроек памяти исполнителя от числа ядер Спарк на узле. При этом иногда максимальное увеличение количества ядер Spark на узле может фактически замедлить выполнение заданий, однако все же сократит стоимость расходов на облачный кластер AWS [1].
Что настраивать будем: приоритизация заданий и конфигурирование ресурсов
При настройке Spark-приложений с целью повышения их эффективности, в т.ч. экономической, о чем мы говорили здесь, необходимо помнить про приоритизацию отдельных заданий в составе всего конвейера аналитической обработки Big Data. Чтобы понять, какие задания следует настраивать в первую очередь, в качестве критерия выбора можно взять минуты, занимаемые вычислительным ядром фреймворка. Этот показатель равен произведению количества исполнителей на число ядер на исполнителе и время работы в минутах. Таким образом, имеет смысл оптимизировать задания с одним или парой ядер на исполнителе, а также те задания, у которых ядро Spark работает 3000 или более минут.
Поэтому при оптимизации стоимости Spark-кластера в AWS нужно изменять количество исполнителей при изменении количества их ядер, чтобы обеспечить такую же вычислительную мощность ядра Spark с новой конфигурацией. Примечательно, что при переходе на более дешевую, но более медленную конфигурацию невозможно добиться резкого улучшения времени выполнения. Поэтому, чтобы достигнуть компромисса между затратами и качеством, следует пересмотреть SLA и понять, приемлемо ли более длительное время выполнения для сокращения расходов на облачные вычисления [2].
Также стоит помнить про возможность динамического распределения ресурсов (dynamic allocation), встроенную в Apache Spark. Этот механизм позволяет автоматически выделять ресурсы приложениям на основе загрузки кластера: задание может высвободить занятые, но не используемые в данный момент, ресурсы. А при необходимости приложение также может запросить ресурсы у кластера. Это особенно полезно, когда несколько приложений делят ресурсы Спарк-кластера. Однако, dynamic allocation будет вести себя по-разному в зависимости от мощности исполнителя. Чтобы понять это, следует провести пару тестов, включив и отключив настройку spark.dynamicAllocation.enabled, а также поэкспериментировать с другими свойствами этой конфигурации [3].
Интересно, что иногда чрезмерное использование ЦП узла фактически улучшает производительность. Это характерно для заданий с большим временем ожидания ЦП. Например, при загрузке данных в NoSQL-СУБД Cassandra или Elasticsearch Спарк-задание будет много ожиданий ввода-вывода. Поэтому оптимизация возможна за счет повышенной загрузки CPU узла и увеличения ядер Spark в исполнителе. Также здесь можно сократить объем памяти, чтобы на узле поместился дополнительный исполнитель. На практике имеет смысл увеличивать количество ядер до 5, а затем уменьшать объем памяти до количества, позволяющего установить дополнительный исполнитель на узле.
Изменение облачного кластера
Иногда целесообразно переключиться на более крупный тип инстанса AWS EC2. В частности, в некоторых Spark-заданиях жестко заданное соотношение между памятью и процессорами на узле кластера снижает производительность и стоимость. Например, большинство узлов в Expedia Group используют 8 ГБ ЦП на узел (128 ГБ / 16 ЦП или 64 ГБ / 8 ЦП). Однако некоторые команды используют узлы только по 4 ГБ на процессор узла (64 ГБ / 16 процессоров или 32 ГБ / 8 процессоров), что вполне достаточно для ряда задач. Тем не менее, хотя узлы с жесткими соотношениями могут быть на 25% дешевле, эта экономия затрат будет потрачена впустую, если используются все доступные ЦП на узлах. В этом случае стоит подумать о кластере с более низким соотношением памяти и ЦП. Кроме того, если использование ЦП и памяти составляет 100%, память обычно становится узким местом, поэтому переключение на более свободный узел повысит скорость и снизит стоимость выполнения заданий.
Проверить эффективность работы конфигурирования можно через графический веб-интерфейс, оценив время используемые ресурсы и успешность выполнения Спарк-задач, о чем мы поговорим завтра.

Освоить эти и другие приемы администрирования Hadoop-кластеров и оптимизации распределенных приложений аналитики больших данных с Apache Spark вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники
-
- https://medium.com/expedia-group-tech/part-1-cloud-spending-efficiency-guide-for-apache-spark-on-ec2-instances-79ee8814de4e
- https://medium.com/expedia-group-tech/part-4-how-to-migrate-existing-apache-spark-jobs-to-cost-efficient-executor-configurations-a7d4909eae34
- https://spark.apache.org/docs/latest/configuration.html

