 939
939 
Содержание
Продолжая вчерашний разговор про оптимизацию Spark-приложений в облачном кластере Amazon Web Services, сегодня рассмотрим типовую последовательность действий по конфигурированию заданий и настройке узлов для снижения затрат на аналитику больших данных. А также разберем, какие проблемы с памятью исполнителей могут при этом возникнуть, и как инженеру Big Data их решить.
Еще раз об эффективной утилизации ресурсов кластера: ядра ЦП для исполнителей Spark-заданий в облаке AWS
Расходы на облако AWS определяются числом узлов в кластере, которое зависит от того, насколько эффективно каждый узел, где развернут исполнитель Spark-приложения, использует ресурсы (ЦП и память). Когда в доступной памяти узла не помещается новый исполнитель, для него добавляется новый узел в кластер, увеличивая расходы на облако AWS, о чем мы рассказывали вчера. Поэтому для комплексного улучшения Spark-заданий и снижения расходов на облачный кластер стоит нужно выполнить целую последовательность шагов [1]:
- определить и задать оптимальное соотношение количества ядер ЦП исполнителя к числу вычислительных ядер Apache Spark (Core Spark);
- определить и задать оптимальный размер памяти исполнителя для каждого узла;
- если Spark-задание запускается со 100%-ным потреблением ЦП и памяти, целесообразно запускать его на узле с большим объемом ресурсов, чтобы сократить время выполнения. Подробнее об этом мы рассказываем в новой статье.
Рассмотрим несколько примеров настройки конфигурации исполнителей для задания оптимального количества ресурсов. Например, в кластере с 32 ядрами и 256 ГБ памяти имеет смысл оставить 2 ядра для YARN и системной обработки, оставив 30 ядер ЦП для непосредственной обработки больших данных. Таким образом, 5-ядерный исполнитель с 34 ГБ памяти также будет работать на таком узле. А в кластере с 8 или менее ядрами на узле, можно использовать только 8 основных (или меньше) узлов, если Spark-задания выполняются только на одном узле. Однако, когда задания занимают два 8-ядерных узла или четыре 4-ядерных, лучше выполнять их на 16-ядерном узле по следующим причинам [1]:
- единственная конфигурация, которая использует все доступные процессоры на 8-ядерном узле — 7-ядерный исполнитель. Однако, 7 core-исполнителей Spark снизит общую производительность задания, поэтому стоит выбрать 5 ядер.
- Два 8-ядерных узла будут иметь только 14 ЦП, доступных для использования, в отличие от 15 ЦП на одном 16-ядерном узле.
- Два 8-ядерных узла будут стоить столько же, сколько один 16-ядерный узел в том же семействе экземпляров. Поэтому при использовании 16 core-узлов получится максимальная производительность исполнителей Spark-заданий и один дополнительный ЦП по той же цене, что и два 8-ядерных узла.
Далее рассмотрим, какие проблемы с памятью могут возникнуть у исполнителя во время выполнения Spark-задания и как их решить.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
1 июня, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Что-то с памятью моей стало: 2 главных проблемы ОЗУ у исполнителей Spark-заданий и способы их решения
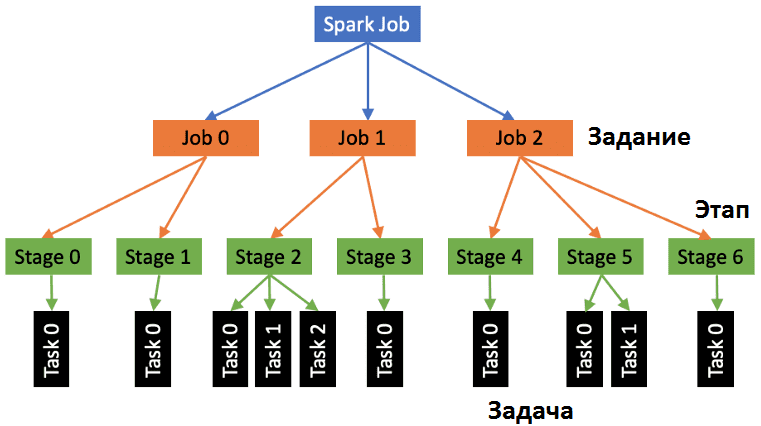
Прежде всего напомним про иерархическую организацию Spark-приложения, которое делится на задания (job), далее разбивается на этапы (stage) и, наконец, на задачи (task). Оценить успешность и ошибки их выполнения можно в веб-интерфейсе Apache Spark, переходя от Этапов к Задачам.
Обычно сбои из-за проблем с памятью исполнителя случаются по следующим причинам [2]:
- Ошибка служебной памяти (Overhead memory error), которая выглядит так
ExecutorLostFailure (executor X exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 34.4 GB of 34.3 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Следуя рекомендации увеличить накладные расходы на память, потребуется уменьшить память исполнителя на ту же величину, чтобы гарантировать, что контейнер-исполнитель потребляет такой же объем памяти узла, как и раньше. Такое изменение не приведет к нехватке памяти внутри самого исполнителя. Узнать точный объем служебной памяти, используемой в Spark-задании можно через поиск в веб-GUI на вкладке «Среды» (Environments). Если снова возникнет сообщение об ошибке, нужно продолжать увеличивать накладные расходы памяти, уменьшая память исполнителя на тот же объем.
- Ошибка перемешивания памяти (Shuffle memory errors), которая выглядит так
ExecutorLostFailure (executor X exited caused by one of the running tasks) Reason: Container marked as failed: container_1541210250016_0002_01_003278 on host: 10.120.8.88. Exit status: -100. Diagnostics: Container released on an *unhealthy or unreachable* node
Для определения этой ошибки нужно проверить, есть ли данные в столбце «Случайное чтение» (Shuffle Read) для этого этапа. Если есть, то следует убедиться в наличии 200 задач на этапе (значение по умолчанию для shuffle-разделов). В случае задания другого числа разделов, нужно также подтвердить это. Устранить ошибку можно, увеличив количество разделов перемешивания для конкретного этапа, чтобы данные, считываемые исполнителем, были разделены на меньшие размеры. Для этого следует задать новое число перемешиваемых разделов. Рекомендуется установить количество shuffle-разделов в два раза больше ядер исполнителей Spark, задействованных в задании.
При использовании датафреймов в Spark-задании, также следует изменить параллелизм на то же число X:
—conf spark.sql.shuffle.partitions = X
—conf spark.default.parallelism = X
Количество shuffle-разделов увеличится в пользовательском интерфейсе Spark во время следующего запуска, чтобы соответствовать заданному значению. Если проблема не исчезнет, стоит удвоить количество shuffle-разделов. А если это не помогло, то имеет смысл уменьшить количество ядер для исполнителей на 1. Это увеличит соотношение памяти к ядру для исполнителей. Однако, такое изменение следует делать только в крайнем случае, поскольку это уменьшит количество ядер Spark, работающих на узле, и, следовательно, снизит его эффективность [2]. Примерный расчет оптимального количества ресурсов на исполнителя смотрите в нашей новой статье.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
1 июня, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Узнайте больше о практических приемах эффективного администрирования Hadoop-кластеров и оптимизации распределенных приложений аналитики больших данных с Apache Spark на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

