 964
964 
Содержание
Сегодня поговорим про особенности транзакций в Apache Spark, что такое фиксация заданий в этом Big Data фреймворке, как она связано с протоколами экосистемы Hadoop и чем это ограничивает переход в облако с локального кластера. Читайте далее, как найти компромисс между безопасностью и высокой производительностью, а также чем облачные хранилища отличаются от локальных файловых систем и каким образом это влияет на Spark-приложения.
Зачем нужны протоколы фиксации заданий или что не так с облачными Spark-приложениями
С учетом стремительной тенденции перехода от локальных решений к облачным, в. т.ч в области Big Data, cloud-хранилища становятся все более востребованными. Например, очень часто локальное озеро данных (Data Lake) на Apache Hadoop HDFS заменяется на Amazon S3 или Delta Lake от Databricks. Подробнее о том, что такое Delta Lake, чем это высокоскоростное облачное хранилище отличается от привычного озера данных на базе Hadoop HDFS и как оно связано с Apache Spark, мы писали здесь. При этом пользователям требуется быстрая и корректная с точки зрения транзакций запись в облачные системы хранения. При том, что Apache Spark обеспечивает отказоустойчивость, разбивая работу для выполнения задания на повторяющиеся задачи, сбои все же иногда случаются. Поэтому Spark должен гарантировать, что видимыми становятся только результаты успешных задач и заданий. Это достигается с помощью протокола фиксации (commit protocol), который определяет, как результаты должны быть записаны в конце задания.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
6 апреля, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Фаза фиксации задания в Spark гарантирует, что читателям видны только результаты успешных заданий. Однако, при использовании Apache Spark в облачной среде фиксация задания становится источником проблем с производительностью и корректностью, например, в случае записи непосредственно в службы хранения, такие как Amazon S3 [1].
Поскольку Spark-приложения работают в распределенном режиме, невозможно атомарно записать результат работы. Например, когда вы пишете Dataframe, результатом операции будет каталог с несколькими файлами в нем, по одному на раздел Dataframe, например, part-00001 -…). Эти файлы разделов записываются несколькими исполнителями в результате их частичного вычисления. Для предотвращения такой ситуации в Spark есть концепция протокола фиксации – механизма, который обеспечивает корректную запись частичных результатов в случае неудачи всей задачи [2]. Рассмотрим пару примеров, которые иллюстрируют, что происходит в случае сбоя, если Spark не использует commit-протокол [1]:
- данные записаны в облачное хранилище частично. Планировщик Spark повторно попытается выполнить задачу, что может привести к дублированию ее результатов.
- в случае сбоя всего задания в облачном хранилище могут остаться частичные результаты выполнения отдельных задач.
Любой из этих сценариев может нанести серьезный ущерб бизнесу и, чтобы избежать этого, Spark использует классы протокола фиксации из экосистемы Hadoop, которые выводят задачу первого этапа во временные хранилища, окончательно перемещая данные только после завершения задачи или задания. Однако, изначально эти протоколы Apache Hadoop не были предназначены для настройки облачных вычислений, что вынуждает пользователя выбирать между скоростью их выполнения и корректностью [1].
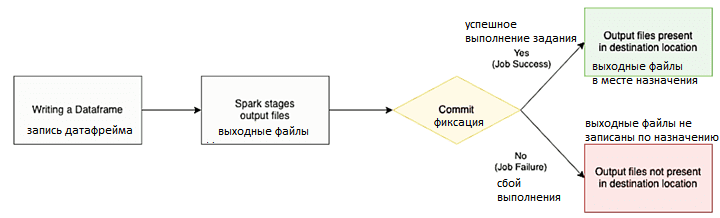
Безопасность vs производительность: 2 версии commit-протоколов Apache Hadoop
По умолчанию Apache Spark поставляется с двумя стандартными алгоритмами фиксации Hadoop [2]:
- версия 1, которая перемещает выходные файлы задачи в их окончательные местоположения в конце задания. Spark создает временный каталог и записывает туда все файлы промежуточного вывода. Когда все задачи будут выполнены, драйвер Spark перемещает эти файлы из временного каталога в конечный пункт назначения, удаляет временный каталог и создает файл _SUCCESS, отмечая операцию как успешную. Проблема в том, что для многих выходных файлов драйвер может занять много времени на последнем этапе.
- версия 2, которая перемещает файлы по мере выполнения отдельных задач задания. Версия 2 решает эту проблему долгой работы Spark-драйвера на последнем этапе, записывая файлы результатов задачи напрямую в конечный пункт назначения. Это ускоряет процесс фиксации, но в случае сбоя задания в конечном пункте назначения останутся файлы с частичными результатами, что может привести к некорректным данным.
Сам протокол фиксации транзакционной записи в Spark можно настроить с помощью конфигурации spark.sql.sources.commitProtocolClass, которая по умолчанию указывает на класс реализации SQLHadoopMapReduceCommitProtocol, подкласс HadoopMapReduceCommitProtocol. Задать версию commit-алгоритма можно в параметре spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version. Начиная с релиза 2.2.0 Apache Spark поддерживает конфигурацию версии протокола фиксации. Также стоит отметить зависимость значения по умолчанию от рабочей среды, т.е. версия экосистемы Hadoop [2].
Таким образом, протокол фиксации версии 1 обеспечивает безопасность, а версии 2 — производительность. Однако, версия 1 не подходит для нативных настроек облака, например, для записи в Amazon S3, из-за отличий хранилищ облачных объектов от реальных файловых систем, о которых мы поговорим далее.
Чем локальные файловые системы отличаются от облачных хранилищ и как это влияет на Apache Spark
Обычно облачные провайдеры предлагают постоянное хранение данных в объектных хранилищах. Это не классические файловые системы POSIX. Чтобы хранить сотни петабайт данных без единой точки отказа, объектные хранилища заменяют классическое дерево каталогов файловой системы более простой моделью object-name=>data. Для включения удаленного доступа операции с объектами обычно предлагаются операции HTTP REST, которые считаются довольно медленными.
Apache Spark может читать и записывать данные в хранилища объектов через коннекторы файловой системы, реализованные в Hadoop или предоставляемые cloud-провайдером. Благодаря этим коннекторам хранилища объектов выглядят почти как файловые системы с каталогами и файлами, а также с классическими операциями над ними, такими как показать список, удалить и переименовать. Однако, облачные хранилища объектов не являются настоящими файловыми системами: обычно их нельзя использовать в качестве прямой замены файловой системы кластера, такой как HDFS. Это обусловлено следующими ключевыми отличиями облачного объектного хранилища от локальной файловой системы [3]:
- изменения в сохраненных объектах могут быть не сразу видны как в списках каталогов, так и при фактическом доступе к данным;
- средства эмуляции каталогов могут замедлить работу с ними;
- операции переименования могут быть очень медленными и в случае сбоя оставить хранилище в неизвестном состоянии;
- поиск в файле может потребовать новых HTTP-вызовов, что снизит производительность.
Таким образом, в случае работы Spark-приложений с облачными объектными хранилищами, чтение и запись данных могут быть сильно медленнее, чем работа с обычной файловой системой. Также, некоторые структуры каталогов могут быть очень неэффективными для сканирования во время вычисления разделения запроса, а результат работы может быть не сразу виден для последующего запроса. Кроме того, алгоритм на основе переименования, с помощью которого Spark обычно фиксирует работу при сохранении своих основных структур данных (RDD, DataFrame или Dataset), потенциально медленный и ненадежный.
Поэтому не всегда безопасно использовать хранилище объектов в качестве прямого назначения запросов или в качестве промежуточного хранилища в цепочке запросов. В частности, без какого-либо уровня согласованности Amazon S3 нельзя безопасно использовать в качестве прямого назначения для работы с обычным коммиттером на основе переименования [3].
Таким образом, особенности облачных хранилищ данных усугубляют проблему выбора безопасность или производительность, которую ставят Hadoop-протоколы фиксации заданий Apache Spark. Чтобы решить проблему оставления частичных результатов при сбоях заданий и снижения производительности, Databricks реализовала собственный протокол транзакционной записи под названием DBIO Transactional Commit, о котором мы поговорим в следующий раз.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Еще больше тонкостей по разработке распределенных приложений и потоковой аналитике больших данных с помощью Apache Spark вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
Источники
- https://databricks.com/blog/2017/05/31/transactional-writes-cloud-storage/
- https://medium.com/tblx-insider/transactional-writes-in-spark-2d7cb916f2fc
- https://github.com/apache/spark/blob/32a0451376ab775fdd4ac364388e46179d9ee550/docs/cloud-integration.md

