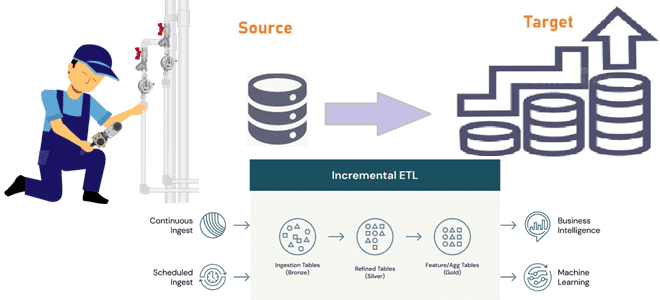
Инкрементные конвейеры загрузки больших объемов данных в корпоративное хранилище или озеро как самый экономичный способ масштабирования архитектуры данных. Разбираемся, как дата-инженеру эффективно организовать такие ETL-конвейеры. 2 способа организации конвейеров инкрементной загрузки данных Инкрементный ETL (Extract, Transform and Load) для классического DWH стал обычным явлением с источниками CDC (сбор данных об...
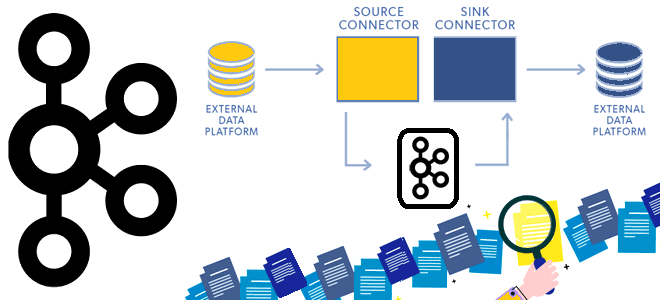
Сегодня рассмотрим принципы работы компонента экосистемы Apache Kafka под названием Connect и разберемся, как он устроен. Программная архитектура коннекторов и способы избежать дубликатов при зависании внешней системы-приемника. Архитектура и принципы работы Kafka Connect Apache Kafka не зря считается платформой потоковой передачи, а не просто брокером сообщений. Вокруг нее выстроена целая...
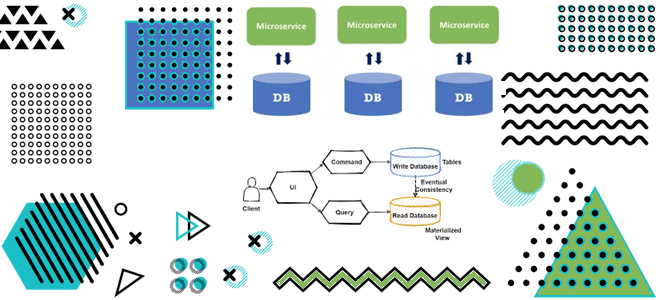
Как материализованные представления в потоковой базе данных с CDC-подходом и шаблоном CQRS позволяют реализовать масштабируемую и высокопроизводительную систему с микросервисной архитектурой для транзакций и аналитики данных в реальном времени. Разбираемся с паттернами проектирования микросервисов на примере интернет-магазина. Что не так с шаблоном композиция API и другие проблемы микросервисной архитектуры в...
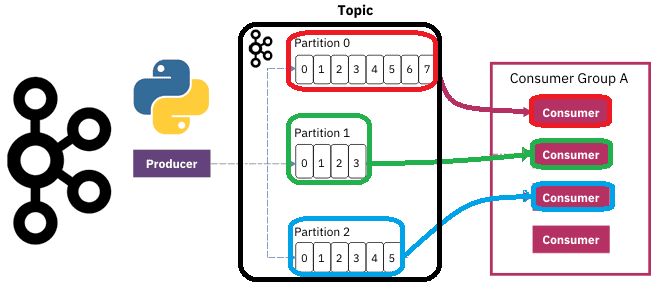
Чтобы разобраться, как на самом деле работают разделы и потребители Apache Kafka, сегодня рассмотрим небольшой демонстрационный пример, иллюстрирующий потребление сообщений. Пишем Python-скрипты публикации и потребления сообщений из разных разделов топика Kafka с занесением данных в несколько вкладок Google-таблицы. Как сообщения распределяются по разделам топика Kafka Напомним, в Apache Kafka раздел...
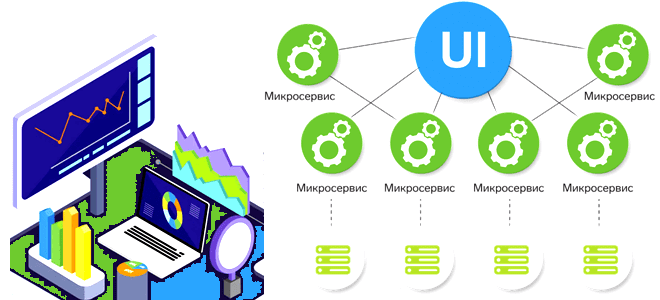
Сегодня разберем проблемы микросервисной архитектуры для платформ данных и способы их решения, а также вспомним 5 популярных шаблонов развертывания, которые могут смягчить риски от внедрения новых версий многокомпонентной системы. Проблемы микросервисной архитектуры для платформы данных и способы их решения При всех плюсах микросервисной архитектуры (автономность, гибкость, масштабируемость, простота развертывания, технологическая...
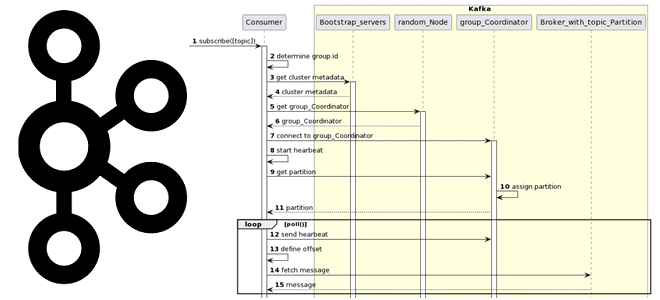
Вчера мы разбирали работу приложения-продюсера и строили UML-диаграмму последовательности. Сегодня рассмотрим, какие системные вызовы происходят при потреблении сообщений из Apache Kafka, при чем здесь группы потребителей и фиксация смещений. Как работает потребитель Kafka Аналогично разработке приложения-продюсера, при написании кода потребителя, который считывает данные из топика Apache Kafka, используются методы специальных...
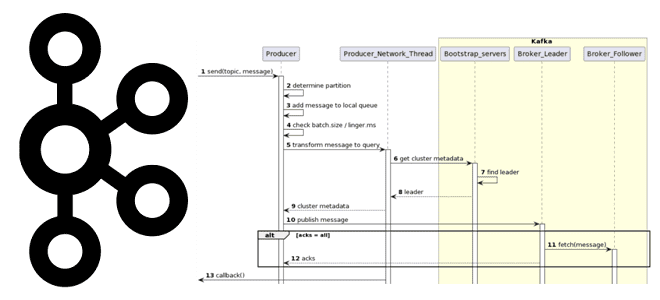
Как на самом деле работает приложение-продюсер Apache Kafka: разбираемся с конфигурациями и составляем UML-диаграмму последовательности системных вызовов при публикации сообщений в топик. Как работает продюсер Kafka Когда разработчик пишет приложение-продюсер, которое публикует сообщение в топик Apache Kafka, он использует методы специальных библиотек, таких как kafka-python и пр. Достаточно только создать...
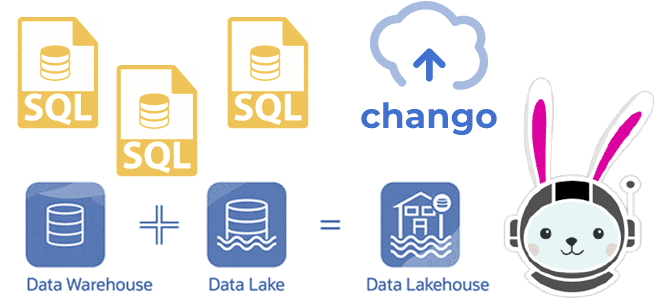
Как реализовать гибридную архитектуру данных Lakehouse на новой платформе Chango с движком обработки распределенных запросов Trino без дополнительного развертывания кластера Kafka и разработки Spark-приложений потоковой передачи событий. Что такое Trino: принципы работы распределенного SQL-движка О том, что представляет собой новая гибридная архитектура данных под названием Lakehouse, мы подробно писали здесь,...
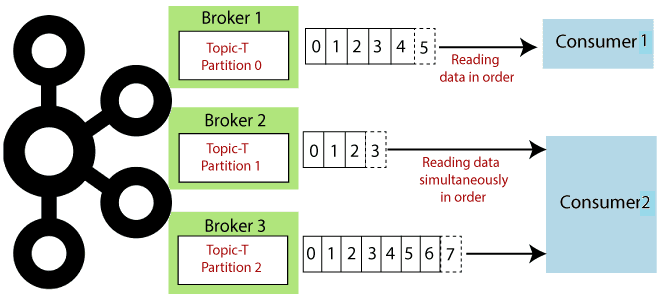
Что общего у Kafka Streams и Consumer API, чем они отличаются и что выбирать для практического использования: краткое руководство для разработчика приложений потоковой обработки событий. Возможности и ограничения Kafka Streams и Consumer API Поскольку Apache Kafka как огромная экосистема со множеством компонентов для потоковой передачи событий, обилие и разнообразие этих...

Что такое потоковая аналитика больших данных, какие бывают СУБД потоковой передачи, когда и зачем их использовать, а также что влияет на выбор этих инструментов хранения и аналитической обработки Big Data. Что такое потоковые базы данных и как они работают Мы уже упоминали, что аналитика данных в реальном времени может быть...