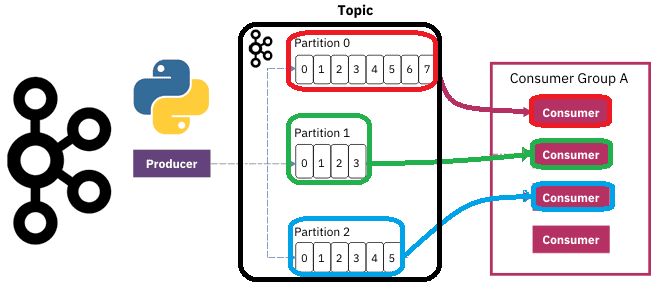
Чтобы разобраться, как на самом деле работают разделы и потребители Apache Kafka, сегодня рассмотрим небольшой демонстрационный пример, иллюстрирующий потребление сообщений. Пишем Python-скрипты публикации и потребления сообщений из разных разделов топика Kafka с занесением данных в несколько вкладок Google-таблицы.
Как сообщения распределяются по разделам топика Kafka
Напомним, в Apache Kafka раздел топика является единицей параллелизма. На 1 раздел может быть лишь 1 активный потребитель в группе. Например, если в топике 3 раздела и 5 приложений-потребителей в одной группе, 3 потребителя будут распределены по имеющимся разделам, а 2 оставшихся будут простаивать. Хронологический порядок сообщений в Kafka гарантируется только в рамках раздела. Поэтому в топике с одним разделом проще обеспечить упорядочивание, чем с несколькими. Но один раздел не дает параллелизма и балансировки нагрузки. Чтобы найти компромисс между этими противоречивыми требованиями, в Apache Kafka есть несколько стратегий (принципов) партиционирования, т.е. распределения входящих сообщений по разделам топика. Наиболее наглядно различия этих принципов распределения сообщений по разделам показывает простая таблица сравнения их по достоинствам, недостаткам и вариантам использования.
|
Принцип распределения сообщений по разделам |
Плюсы |
Минусы |
Варианты использования |
|
Круговой перебор (Robin Round) |
параллелизм и балансировка нагрузки, упорядоченность сообщений внутри раздела |
не сохраняется общий хронологический порядок сообщений (вне раздела) |
Используется по умолчанию. Сообщения отправляются всем разделам по кругу, обеспечивая сбалансированную нагрузку на узлы кластера |
|
Задание ключа сообщению для отправки в раздел по хэш-функции от ключа |
можно поддерживать порядок сообщений в пределах ключа |
неравномерное распределение данных по разделам (несбалансированная нагрузка) |
Сообщения с одним и тем же значением ключа попадут к одному и тому же потребителю |
|
Пользовательский разделитель |
упорядоченость сообщений согласно бизнес-логике, балансировка нагрузки и параллелизм |
Усложнение программного кода приложения-продюсера, где задается раздел |
Используется в случаях, когда нужно обеспечить упорядочивание сообщений, параллелизм и балансировку нагрузки |
Пользовательский разделитель, а также задание ключа сообщению позволяют реализовать бизнес-логику маршрутизации потока данных подобно обменникам в RabbitMQ. Рассмотрим это на примере приема потока обращений в интернет-магазин. Обращения могут представлять собой заявки от частных лиц и корпоративных клиентов на покупку товаров, а также вопросы по работе магазина, доставке или оплате. Все входящие обращения будут публиковаться в топик Kafka, который состоит из 3-х разделов. В раздел с номером 0 будут попадать все вопросы, в раздел с номером 1 – все корпоративные заявки, а в раздел 2- частные. Как реализовать такое разделение в коде, рассмотрим далее.
Пример продюсера и потребителей на Python
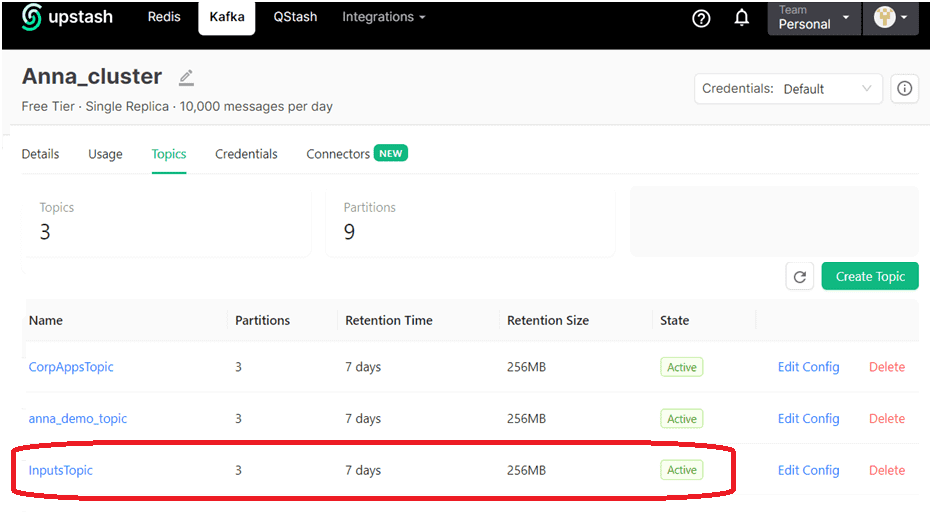
Чтобы реализовать вышеописанную логику распределения сообщений по разделам, я создала топик Kafka на инстансе, развернутом в облачной serverless-платформе Upstash. Топик называется InputsTopic и имеет 3 раздела.
Код продюсера, отправляющего клиентские обращения, написан на Python с использованием библиотеки kafka-python:
#############ячейка в Google Colab №1 - установка и импорт библиотек################
#установка библиотек
!pip install kafka-python
#импорт модулей
import json
import random
from datetime import datetime
import time
from time import sleep
from kafka import KafkaProducer
#########ячейка в Google Colab №2 - публикация сообщений в Kafka#####################
# объявление продюсера Kafka
producer = KafkaProducer(
bootstrap_servers=['........здесь взять название своего сервера.upstash.io:9092'],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username='.........здесь имя пользователя, взятое из upstash',
sasl_plain_password='..........здесь пароль для этого пользователя',
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
#бесконечный цикл публикации данных
#списки полей в заявке
names_fiz = ['Anna', 'Lisa', 'Ivan', 'Petr', 'Kira', 'Dima', 'Oleg', 'Zina', 'Vlad', 'Nick']
names_corp = ['ZAO SVAP', 'OOO Rim', 'ZAO Kisa', 'IP Lisana', 'OOO Zavod', 'OAO Tips', 'IP VAA']
products = ['bred', 'garlic', 'oil', 'apples', 'water', 'soup', 'dress', 'tea', 'cacao', 'coffee', 'bananas', 'butter', 'eggs', 'oatmeal']
questions = ['payment', 'delivery', 'discount', 'vip', 'staff']
while True:
#подготовка данных для публикации в JSON-формате
now=datetime.now()
id=now.strftime("%m/%d/%Y %H:%M:%S")
content = ''
theme = ''
corp = 0
part = 0
#подготовка списка возможных ключей маршрутизации (routing keys)
corp = random.choice([1,0])
if corp==1 :
name = random.choice(names_fiz)
routing_keys = ['app' + '.company.' + name, 'question']
else:
name = random.choice(names_corp)
routing_keys = ['app', 'question']
#случайный выбор одного из ключей маршрутизации (из routing keys)
subject=random.choice(routing_keys)
#добавление дополнительных данных для заголовка и тела сообщения в зависимости от темы заявки
if subject=='question':
theme = random.choice(questions)
content = 'Hello, I have a question about ' + theme
part=0 #все вопросы записывать в раздел 0
else :
theme ='app'
if corp==1 :
part=1 #все корпоративные заявки записывать в раздел 1
else:
part=2 #заявки от частных лиц записывать в раздел 2
content = random.choice(products) + ' ' + str(random.randint(0,100))
#задаем ключ сообщения для Kafka
mes_key = str.encode(subject+name)
#создаем полезную нагрузку в JSON
data = {'id': id, 'name': name, 'subject': subject, 'content': content}
#публикуем данные в Kafka
future = producer.send('InputsTopic', value=data, partition=part, key=mes_key) #здесь вместо InputsTopic должно быть название вашего топика
record_metadata = future.get(timeout=60)
#вывод отладочной информации
print(f' [x] Sent {record_metadata}')
print(f' [x] Corp = {corp}')
print(f' [x] Payload {data}')
#повтор через 3 секунды
time.sleep(3)
#####################ячейка в Google Colab №3 - закрытие соединения###################
#Закрываем соединения
producer.close()
В этом коде сообщения формируются случайно и публикуются в топик каждые 3 секунды. В методе продюсера send() явно заданы и ключ партиционирования для сообщения, и раздел, в который следует его опубликовать. При явном указании раздела именно он является указателем для распределения сообщений в топике, а ключ сообщения при распределении не учитывается.
Как обычно, запускаю код в интерактивной среде Google Colab:
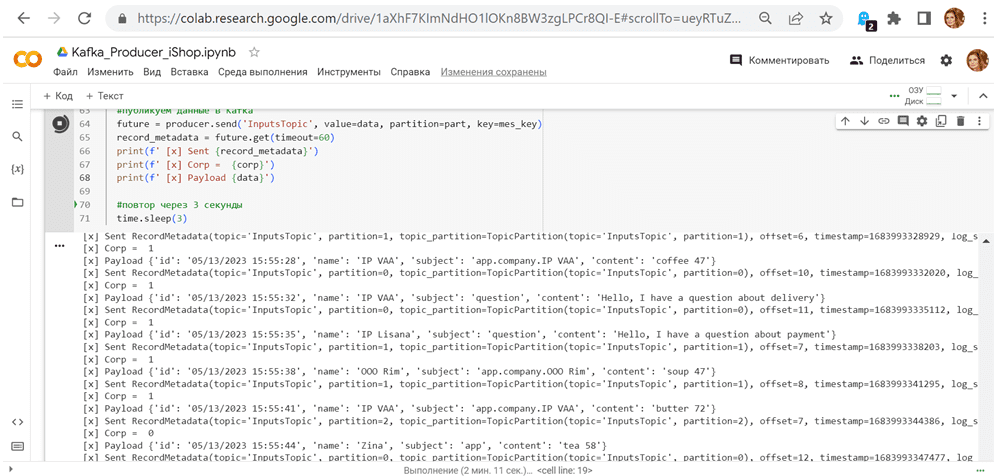
Для наглядной демонстрации распределения потока сообщений по разделам я написала 3 почти одинаковых приложения-потребителя, каждый из которых считывает сообщения из своего раздела, и публикует их в соответствующей вкладке Google-таблицы. Код выглядит следующим образом:
####################################ячейка в Google Colab №1 - установка и импорт библиотек###########################################
#установка библиотек
!pip install kafka-python
#импорт модулей
from google.colab import auth
auth.authenticate_user()
import gspread
from google.auth import default
creds, _ = default()
import json
import random
from kafka import KafkaConsumer
from json import loads
from kafka.structs import TopicPartition
####################################ячейка в Google Colab №2 - потребление из Kafka###########################################
#объявление потребителя Kafka
consumer = KafkaConsumer(
bootstrap_servers=['........здесь взять название своего сервера.upstash.io:9092'],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username='.........здесь имя пользователя, взятое из upstash',
sasl_plain_password='..........здесь пароль для этого пользователя',
group_id='1',
auto_offset_reset='earliest',
enable_auto_commit=True
)
#consumer.unsubscribe()
#consumer.unsubscribe()
#Google Sheets Autentificate
gc = gspread.authorize(creds)
# подписка потребителя на определенный раздел topic partition
#все вопросы лежат в разделе 0
#все корпоративные заявки лежат в разделе 1
#заявки от частных лиц лежат в разделе 2
part=1 #задание раздела
topic_partition = TopicPartition('InputsTopic', part) # указываем имя топика и номер раздела
consumer.assign([topic_partition])
#Открытие заранее созданного файла Гугл-таблицы по идентификатору (взять из его URL, например, у меня это https://docs.google.com/spreadsheets/d/1ZQuotMVhaOuOtnZ56mvd1zX-5JOhsXc1WTG6GTBjzzM)
sh = gc.open_by_key('1ZQuotMVhaOuOtnZ56mvd1zX-5JOhsXc1WTG6GTBjzzM')
wks = sh.worksheet("Partition_1") #в какой лист гугл-таблиц будем записывать
#начальный номер строки для записи данных
x=1
#считывание из топика Kafka
for message in consumer:
payload=message.value.decode("utf-8")
data=json.loads(payload)
#вывод исходных данных в консоль Goggle Colab
print(data)
#парсинг JSON-сообщения полезной нагрузки
id=data['id']
name=data['name']
subject = data['subject']
content = data['content']
#вывод распарсенных данных в консоль Google Colab
print('Заявка № ', id, ', клиент ', name, ', тема: ", subject, ', 'содержимое: ', content)
#обновление данных в в Гугл-таблице
global x
#переход на следующую строку в гугл-таблицах
x = x + 1
#запись данных в ячейки гугл-таблицы
wks.update_cell(x,1,id)
wks.update_cell(x,2,name)
wks.update_cell(x,3,content)
###################################ячейка в Google Colab №3 - закрытие соединения###########################################
#отписываем потребителя и закрываем соединение
consumer.unsubscribe()
consumer.close()
Посмотрим, что получилось в Google-таблице. Как и ожидалось, все сообщения распределены по разделам топика согласно заданной бизнес-логике. Из этого топика их считывали 3 приложения-потребителя в одной группе, т.е. с одинаковым значением group.id, заданным при объявлении потребителя.
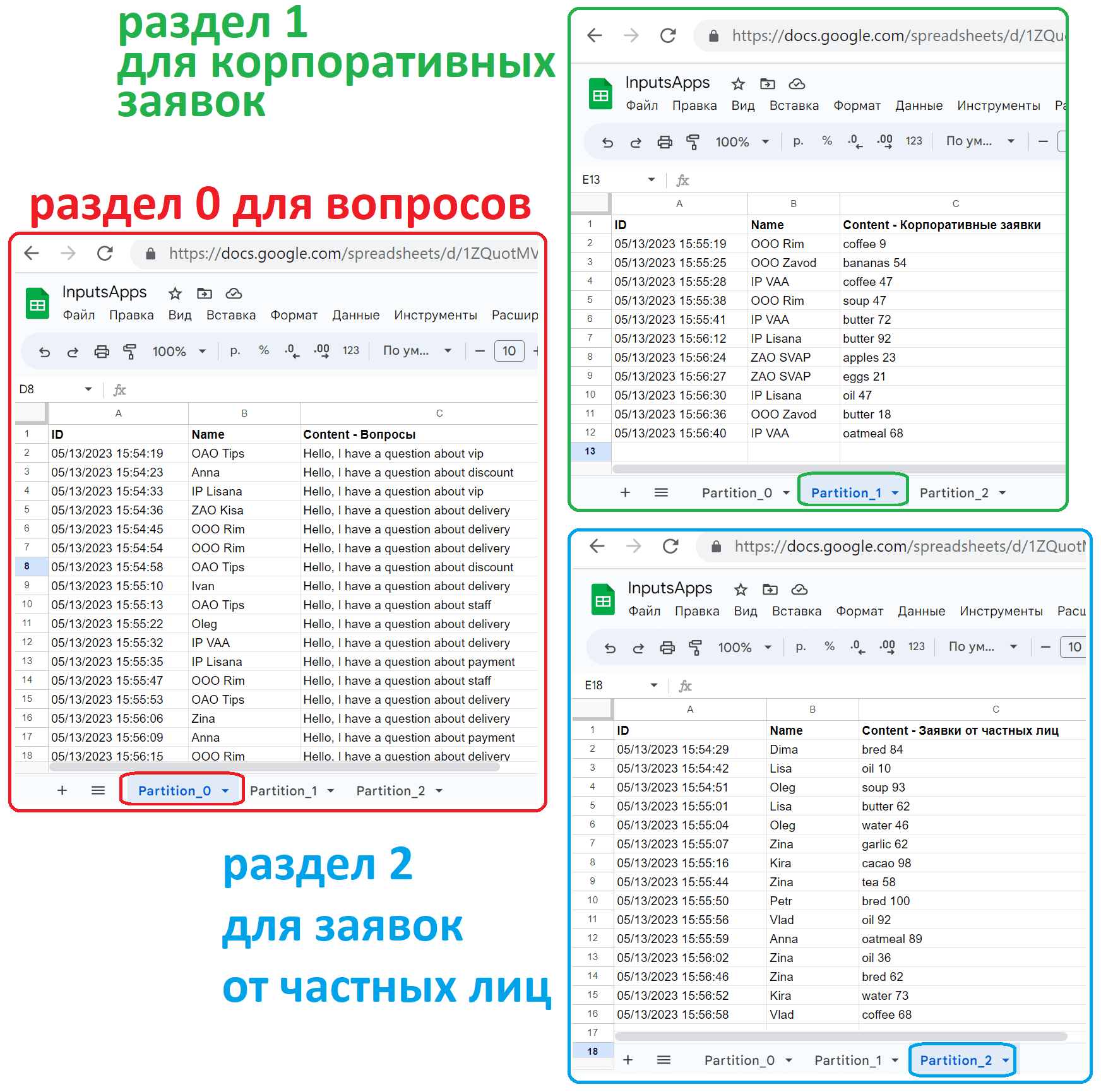
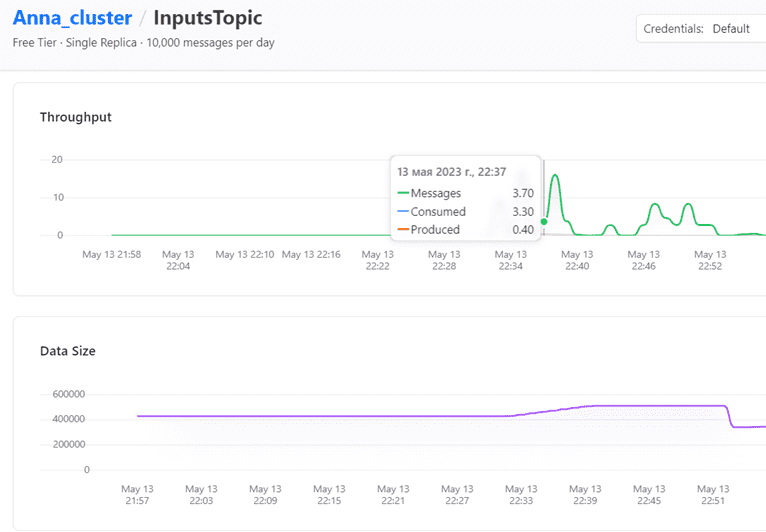
В заключение рассмотрим график публикации и потребления сообщений в GUI платформы Upstash.
Как считать данные из Kafka повторно и/или с определенного момента времени, читайте в нашей новой статье.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Администрирование кластера Kafka
- Apache Kafka для инженеров данных
- Администрирование Arenadata Streaming Kafka
Источники