 598
598 
Содержание
Инкрементные конвейеры загрузки больших объемов данных в корпоративное хранилище или озеро как самый экономичный способ масштабирования архитектуры данных. Разбираемся, как дата-инженеру эффективно организовать такие ETL-конвейеры.
2 способа организации конвейеров инкрементной загрузки данных
Инкрементный ETL (Extract, Transform and Load) для классического DWH стал обычным явлением с источниками CDC (сбор данных об изменениях). Но для озера данных инкрементный ETL сложен из-за невозможности обновления данных и выявления измененных данных в больших таблицах. На высоком уровне инкрементный ETL означает перемещение новых или измененных данных между источником и местом назначения. Инкрементный ETL можно либо запланировать как задание, либо запустить непрерывно для доступа к новым данным с малой задержкой. Данные могут перемещаться и преобразовываться в нескольких таблицах, каждая из которых может использоваться для разных целей. Уточним, что термин «инкремент» здесь означает не единицу поставки бизнес-ценности, как в продуктовом подходе и Agile, что мы разбираем в новой статье, а изменение относительно предыдущего состояния.
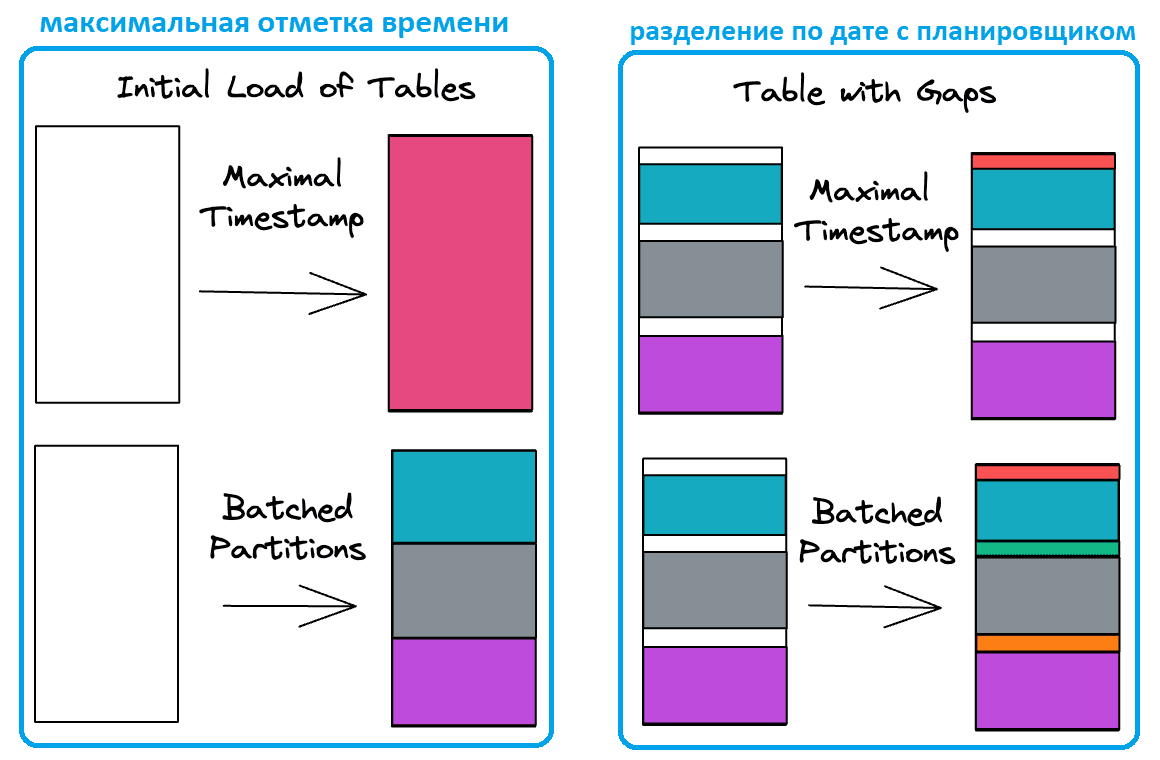
Однако, организация конвейеров инкрементных загрузки больших таблиц фактов/событий в корпоративное озеро является достаточно сложной задачей. Существует два основных способа инкрементного чтения данных: максимальная отметка времени, что популяризируется инструментом dbt, а также разделение по дате, что часто используется с AirFlow и Hive. Примеры других паттернов извлечения данных из реляционных баз мы разбираем в новой статье.
Чтение данных путем нахождения максимальной временной метки состоит из 2-х этапов:
- если таблицы не существует, вся ее история вычисляется за один раз;
- если таблица существует, к ней отправляется запрос, чтобы найти последнюю обработанную метку времени, а затем использовать ее для фильтрации исходных данных восходящего потока.
В качестве примера возьмем данные о событиях пользовательского поведения. Сам SQL-запрос при этом может выглядеть так:
SELECT *
FROM raw.sessions
{% if is_incremental() %}
WHERE ts > (SELECT MAX(ts) FROM {{ this }})
{% endif %}
Основным преимуществом этого подхода является то, что он не требует дополнительного состояния, кроме того, что хранится в таблице. Однако, он имеет следующие недостатки, особенно заметные при работе с большими объемами данных:
- загрузка всей таблицы должна выполняться за один раз, но в больших масштабах для обработки объемных таблиц фактов может потребоваться пакетная обработка, например, фрагменты по 1 месяцу;
- SQL-запрос сложнее писать и поддерживать, поскольку существует два режима работы (для начальной загрузки и для добавочной), что следует учитывать при тестировании и отладке;
- сложно обнаружить и устранить проблемы, которые могут возникнуть из-за пользовательских сценариев или добавления исторических данных.
При написании конвейеров с использованием разделов и планировщика типа AirFlow, задается дату запуска, на которой основан запрос. Для таких случаев в Apache AirFlow есть специальная команда backfill, которая повторно запускает все экземпляры dag_id для всех интервалов в пределах указанных дат начала и окончания. Подробнее о том, что это такое и как работает, мы писали здесь. SQL-запрос в этом случае может выглядеть так:
SELECT *
FROM raw.sessions
WHERE ts BETWEEN {{ start }} AND {{ end }}
Основной недостаток этого подхода заключается в необходимости хранить дополнительное состояние о том, какие интервалы уже были обработаны. Впрочем, обычно эти сведения сохраняются и управляются пакетным планировщиком. В частности, Apache AirFlow предоставляет эту возможность. Таким образом, этот подход имеет больше преимуществ по сравнению с максимальными отметками времени:
- SQL-запросы стали проще благодаря лишь одному режиму работы (без инкрементной или полной загрузки);
- Загрузка данных за прошлые даты с помощью backfill-функции более масштабируема и надежна, поскольку ее можно группировать в управляемые фрагменты;
- можно вычислить данные только за один день или вручную исправить проблемы, переопределив начало и конец интервала.
Кроме выбора способа инкрементного чтения данных, также следует сделать конвейер идемпотентным. Как это организовать, рассмотрим далее.
Идемпотентность конвейера инкрементной загрузки данных
Прежде всего, поясним, почему для инкрементной загрузки больших объемов данных в корпоративное озеро или хранилище важна идемпотентность – свойство, которое означает, что функция возвращает всегда одинаковый результат при одних и тех же входных параметрах. В случае загрузки больших объемов данных идемпотентность инкрементного конвейера позволяет избежать дублирования данных. В частности, загрузка данных с помощью стратегии добавления – это пример неидемпотентного конвейера, случайный запуск которого для одних и тех же данных приведет к дубликатам.
Есть два основных способа сделать конвейер инкрементной загрузки данных идемпотентным даже при позднем поступлении данных: слияние и вставка с перезаписью. Слияние (Merge) обеспечивает сопоставление строк между источником и назначением по ключу с обновлением или вставкой. SQL-запрос выглядит так:
MERGE processed.sessions t USING raw.sessions s ON t.uuid = s.uuid WHEN MATCHED THEN UPDATE SET … WHEN NOT MATCHED THEN INSERT …
При наличии первичного ключа или набор ключей соединения, слияние — отличный способ обеспечить согласованность данных и предотвратить дублирование строк. Дата-инженер может задать свою логику для вставки данных, когда они не существуют, и обновления их, если данные уже есть в хранилище.
Также можно использовать перезапись с вставкой (Insert overwrite). Этот метод на основе разделов используется в Apache Hive и перенесен в Databricks. В этих системах используются разделы – папки, содержащие группы данных. В инкрементных системах обычно бывает одна папка в день. Insert overwrite атомарно удалит папку перед записью в нее содержимого, обеспечивая идемпотентность. SQL-запрос выглядит так:
INSERT OVERWRITE TABLE processed.sessions PARTITION(ds=...) SELECT …
Этот подход требует полного представления данных для каждого записываемого раздела.
Слияние может быть неэффективным, если в предикат не передается сокращение разделов (partition pruning). Это связано с тем, что для обеспечения отсутствия дубликатов механизм должен соединить все существующие записи со всеми новыми записями, чтобы обеспечить уникальность. Однако, слияние эффективно, когда необходимо обновить только несколько записей, например, удалить некоторые персональные данные согласно требованиям ФЗ-152 или GDPR, поскольку оно сводит к минимуму необходимость перезаписи файлов. Но при обработке данных, поступающих с опозданием, обычно требуется обновить много записей, поэтому в таком случае следует применять Insert overwrite. И наоборот, вставка с перезаписью неэффективна при изменении нескольких строк, поскольку требует полной перезаписи всех файлов раздела.
Обработка запоздавших данных
На практике события могут появиться в хранилище намного позже, чем они на самом деле произошли. Но обработать данные, поступающие с опозданием, не так-то просто. Чтобы зафиксировать запоздалые данные, можно просто вычесть нужное окно времени.
В случае применения метода максимальной отметки времени SQL-запрос будет выглядеть так:
SELECT *
FROM raw.sessions
{% if is_incremental() %}
WHERE ts > (SELECT MAX(ts) FROM {{ this }}) - 14
{% endif %}
А с использованием разделов SQL-запрос может быть таким:
SELECT *
FROM raw.sessions
WHERE ts BETWEEN {{ start - 14}} AND {{ end }}
В случае инкрементного конвейера подобная обработка прошлых периодов приводит к обработке данных, которые уже были просмотрены. Чтобы избежать дублирования, конвейеры должны определять ожидаемый диапазон выходных данных. Можно отфильтровать полученный набор данных только для диапазона, который надо записать.
При использовании слияния надо уменьшить этот ожидаемый диапазон до слияния, чтобы не выполнять полное сканирование всех исторических записей. А при перезаписи со вставкой необходимо прочитать все предыдущие строки в ожидаемом диапазоне, чтобы не потерять исторические записи.
Таким образом, инкрементная загрузка данных с помощью идемпотентных конвейеров может стать одним из самых экономичных и эффективных способов масштабирования корпоративного хранилища или озера данных. Реализовать такие ETL-конвейеры можно, используя следующие технологии:
- ACID-транзакции в Delta Lake, которые делают возможным обновление на уровне строк, а также идентификацию изменений на уровне строк в исходных и промежуточных таблицах этого уровня хранения. А поддержка операции MERGE делает вставки и обновления (upsert) на уровне строк очень простыми и эффективными. Подробнее об этом мы писали здесь и здесь.
- Контрольные точки в потоковой передаче событий, например, с помощью Spark Structured Streaming или Flink DataStream API позволяют надежно управлять состоянием ETL-задания;
- Еще одной полезной функцией структурированной потоковой передачи Spark, является Trigger.Once, которая превращает непрерывные чтения из потоковых источников, например, Apache Kafka, в запланированное задание. Это позволяет снизить частоту запланированных заданий и перейти к варианту непрерывного использования без изменения архитектуры данных.
Узнайте больше подробностей по проектированию и поддержке современных дата-архитектур в проектах аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

