 1335
1335 
Содержание
Сегодня рассмотрим принципы работы компонента экосистемы Apache Kafka под названием Connect и разберемся, как он устроен. Программная архитектура коннекторов и способы избежать дубликатов при зависании внешней системы-приемника.
Архитектура и принципы работы Kafka Connect
Apache Kafka не зря считается платформой потоковой передачи, а не просто брокером сообщений. Вокруг нее выстроена целая экосистема, одним из компонентов которой является инструмент Kafka Connect, позволяющий копировать данные из внешних систем-источников (source) в Kafka и распространять сообщения из Kafka во внешние системы-приемники (sink). Это перемещение данных реализуется с помощью процессов-исполнителей (worker). Kafka Connect можно развернуть в распределенном режиме (distributed mode) с несколькими процессами-исполнителями или локально с одним процессом-исполнителем (standalone mode). Само перемещение данных выполняется с помощью коннекторов, которые запускаются в отдельных потоках процесса-исполнителя. В зависимости от типа внешней системы (источник или приемник), коннекторы соответственно называются source connector или sink connector.
Впрочем, это не совсем перемещение — Kafka Connect только копирует данные. Поэтому этот инструмент нельзя использовать для самостоятельной потоковой обработки. Чтобы выполнять операции с содержимым топика Kafka, нужны KSQL, приложения Kafka Streams или приложения-потребители и продюсеры, которые читают сообщения из одного потока, преобразуют значения и записывают вывод в другой поток. А имеющаяся в Kafka Connect функция преобразования данных нужна лишь для преобразования форматов сообщений.
Фактически, Kafka Connect реализует потребление данных из внешнего источника с помощью API продюсера и запись данных в систему-приемник с помощью API потребителя. Однако, Kafka Connect гарантирует доставку по крайней мере один раз (at least once). Это означает, что есть риск дублирования данных: можно несколько раз считать одно и то же сообщение из системы-источника или записать одни и те же данные в систему-приемник. Как с этим бороться, мы рассмотрим в другой раз, а пока заглянем под капот Kafka Connect и познакомимся с ее API.
Хотя существует множество готовых коннекторов к различным системам-приемникам и источникам, иногда разработчику приходится писать собственный код SinkConnector или SourceConnector, а также реализацию SinkTask или SourceTask.
Коннектор определяет конфигурацию задачи (имя класса реализации задачи и его параметры). Коннектор возвращают набор параметров конфигурации задач и могут уведомлять Kafka Connect, когда эти задачи нуждаются в реконфигурации. Для этой перенастройки задач следует использовать метод requestTaskReconfiguration() объекта ConnectorContext, который передается в качестве параметра метода инициализации коннектора.
Kafka Connect управляет задачами, и разработчику не нужно беспокоиться о создании экземпляров задач, достаточно указать только методы, которые читают/пишут сообщения и отслеживают их смещение (offset). Если Kafka Connect работает в распределенном режиме, задачи выполняются на разных узлах кластера, поэтому их экземпляры должны быть независимыми и не иметь общего состояния. Поэтому рекомендуется иметь один коннектор, отвечающий за копирование данных из всей базы данных, чем настраивать отдельные коннекторы для каждой таблицы. Хотя пользовательская реализация SinkConnector или SourceConnector может разделить работу между несколькими экземплярами задачи, этот вариант решения более сложен. Как именно устроена работа коннекторов на программном уровне, рассмотрим далее.
Структура классов
Для внесения изменений в кластер Kafka Connect используется интерфейс Herder, на котором основаны и REST API, и CLI. В исходном коде есть 2 реализации интерфейса Herder: для локального режима с одним узлом и распределенного кластера. В дополнение к методам start() и stop(), которые запускают или завершают работу всего кластера, реализация Herder содержит методы, которые обновляют или удаляют конфигурацию коннектора, а также запускают и останавливают их: putConnectorConfig() и deleteConnectorConfig().
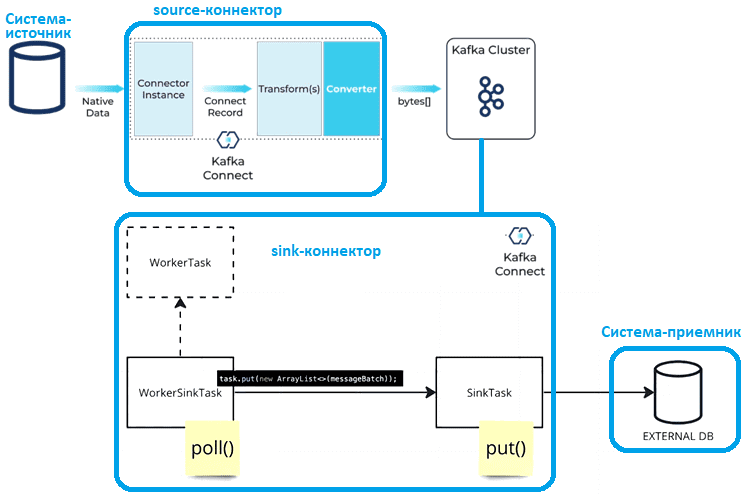
Класс Worker представляет собой контейнер потоков, выполняющих задачи. При запуске нового коннектора Worker передает конфигурацию классу Connector для его инициализации и меняет свое состояние на STARTED. Изменение состояния запускает слушателя и запускает новые рабочие задачи (WorkerTask). WorkerTask является реализацией интерфейса Runnable, и его метод запуска использует перезаписываемый метод выполнения для выполнения своей работы в потоке.
WorkerTask состоит из преобразователей, которые превращают сериализуют ключи сообщений, значения и заголовки, чтобы отправить их в Kafka. WorkerTask получает экземпляр TransformationChain, который инкапсулирует все преобразователи сообщений, определенные как параметры конфигурации источника или приемника. Также передаются классы, предоставляющие доступ к метрикам, конфигурации, текущему времени, политике повторов и пр.
При создании WorkerSourceTask класс Worker передает классы, используемые для отслеживания смещения данных (CloseableOffsetStorageReader и OffsetStorageWriter), и KafkaProducer. А экземпляр WorkerSourceTask получает SourceTask, реализующий доступ к источнику данных, содержимое которого следует скопировать в Kafka.
При этом метод execute() экземпляра WorkerSourceTask проверяет статус задачи, чтобы определить, следует ли приостановить/возобновить/остановить ее выполнение, вызывает метод опроса poll() экземпляра SourceTask для чтения сообщений из источника, и вызывает внутренний метод sendRecords() для отправки данных в Kafka. Внутри метода sendRecords() применяется цепочка преобразований TransformationChain для преобразования данных в структуру, которую надо отправить в Kafka. После преобразования данных создается новая запись продюсера ProducerRecord и записывает раздел и смещение источника в OffsetStorageWriter. Далее записи отправляются в Kafka, а смещения сбрасываются. Сброс смещений вызывает как сброс данных, записанных OffsetStorageWriter, так и вызов метода фиксации commit() экземпляра SourceTask, который должен подтверждать обработку сообщений в источнике, если это необходимо. SourceTask не только извлекает сообщения из источника данных, но также может передавать фиксацию обратно в источник. Это пригодиться в работе с очередями сообщений, когда надо явно сообщить сервису, что смещение обработано. Делать это в методе опроса poll() не рекомендуется, потому что в случае сбоя подтвержденные сообщения будут потеряны.
Поскольку методы опроса и фиксации не получают никаких параметров, реализация SourceTask должна самостоятельно отслеживать обработанные сообщения. Единственная функция отслеживания прогресса, предоставляемая Kafka Connect, — это передача SourceTaskContext в SinkTask, которая обеспечивает доступ к OffsetStorageReader и позволяет получать смещения уже обработанных сообщений.
В случае WorkerSinkTask реализация передает преобразователи, цепочку преобразований TransformationChain, KafkaConsumer и реализацию SinkTask, которая записывает сообщения из Kafka во внешнюю систему-приемник. Копирование содержимого топика Kafka во внешнюю систему реализуется классом WorkerSinkTask в его методе итерации. Он получает сообщения от Kafka с помощью метода pollConsumer(), преобразует сообщение в SinkRecord и передает его через TransformationChain, чтобы получить данные в формате, совместимом с выводом.
Затем вызывается метод deliveryMessages() для записи метрик, сохранения смещений сообщений в коллекции и использования метода put() класса SinkTask для записи данных во внешнюю систему. Вызов функции preCommit() экземпляра SinkTask, которая сбрасывает данные и фиксация смещений обработанных сообщений происходит в начале следующего вызова метода итерации.
В заключение следует отметить наличие класса OffsetBackingStore для отслеживания смещений сообщений, статуса рабочего процесса и параметров конфигурации. Он записывает эти данные в сжатый топик Kafka, чтобы обеспечить доступ к последней версии параметров и автоматически обрабатывать распространение данных по всем рабочим процессам, если Kafka Connect работает в распределенном режиме.
Практический пример и обработка повторов
Чтобы понять, как работает вышеописанная программная архитектура классов, рассмотрим пример, когда обработчик Kafka Connect получает записи и передает их реализации задаче приемника с помощью метода put(), чтобы далее отправить их во внешнюю базу данных.
Однако, на стороне системы-приемника, т.е. внешней базы данных, при потоке высокой интенсивности может быть превышен предел WCU (единицы емкости записи). Во время вызова метода put() возникнет исключение ProvisionedThroughputExceededException. Если добавить задержку, в журналах задач могут появиться сообщения об исключении org.apache.kafka.clients.consumer.CommitFailedException. Это означает, что фиксация смещения не может быть завершена, поскольку экземпляр потребителя workerSinkTask не является частью активной группы для автоматического назначения разделов и время ожидания опроса потребителя истекло. Время между последующими вызовами poll() было больше, чем настроенное значение max.poll.interval.ms, т.е. цикл опроса тратит слишком много времени на обработку сообщений. Можно увеличить max.poll.interval.ms, либо уменьшить максимальный размер пакетов, возвращаемых в poll(), с помощью max.poll.records.
Kafka использует два взаимодополняющих метода для обнаружения неактивных потребителей в группе потребителей, чтобы назначить раздел топика другим потребителям:
- периодическая отправка контрольных сигналов, тактовых импульсов (heartbeat);
- тайм-аут на основе прогресса работы.
Таким образом, необходимо вызвать метод poll(), чтобы показать активность приложения-потребителя. В рассматриваемом примере с отправкой данных во внешнюю базу это может случиться даже при успешной отправке heartbeat-импульсов. При этом могут начаться дубликаты данных, т.к. из-за перебалансировки потребителей раздел стал назначен другому потребителю, который будет отправлять в систему-приемник те же записи. Чтобы решить эту проблему, следует задать тайм-аут для WorkerSinkTask и повторить попытку отправить записи, переданные методу put().
WorkersinkTask использует WorkerSinkTaskContext, который расширяет SinkTaskContext и разделяет его с экземпляром задачи системы-приемника SinkTask во время ее создания. Установить таймаут поможет метод context.timeout(TIMETOWAIT), который обновляет параметр, используемый во время вызова потребителя poll(). Далее можно сгенерировать исключение RetriableException, который сообщит процессу-исполнителю Connect пауза потребителя и прервет вызов deliveryMessages, предотвратив его фиксацию любого прогресса, как будто ничего не отправлялось во внешнюю систему.
Таким образом, процесс-исполнитель потребителя Kafka перестанет пытаться получить новые записи для коннектора, находясь в состоянии паузы, но сможет выполнять свою работу по управлению членством во время вызовов poll(). Также во время этого вызова poll() он будет указывать параметр, связанный с тайм-аутом. В результате этого пользовательский коннектор сможет обрабатывать повторные попытки отправки данных, когда этого требует внешняя система-приемник.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Администрирование кластера Kafka
- Apache Kafka для инженеров данных
- Администрирование Arenadata Streaming Kafka
[elementor-template id=»13619″]
Источники

