 1002
1002 
Содержание
Как реализовать гибридную архитектуру данных Lakehouse на новой платформе Chango с движком обработки распределенных запросов Trino без дополнительного развертывания кластера Kafka и разработки Spark-приложений потоковой передачи событий.
Что такое Trino: принципы работы распределенного SQL-движка
О том, что представляет собой новая гибридная архитектура данных под названием Lakehouse, мы подробно писали здесь, здесь и здесь. Этот архитектурный подход стремится объединить достоинства классических хранилищ (DWH) с гибкостью озер данных (Data Lake), а также унифицировать потоковую и пакетную обработку данных в одной кодовой базе. Это стало возможным благодаря распределенным механизмам обработки и полуструктурированным форматам хранения данных. Данные в LakeHouse можно эффективно запрашивать с помощью схемы при чтении за счет хранения метаданных поверх файлов в хранилище данных. Эти метаданные в основном содержат прошлые вставки и обновления файлов, а также некоторую форму схемы, которая позволяет механизмам обработки обрабатывать файлы как виртуальные таблицы с помощью стандартных SQL-запросов, как обычные таблицы в DWH.
Сегодня самой популярной, но далеко не единственной реализацией архитектуры Lakehouse считается Delta Lake от Databricks. Однако, появляются новые сервисы, тоже заслуживающие внимания. Например, одним из них является Chango — SQL-платформа Lakehouse, основанная на популярном механизме запросов Trino. Chango представляет концепцию шлюза Trino, который динамически направляет запросы Trino на восходящие серверы в кластерах Trino.
Trino — это механизм распределенных запросов, который обрабатывает данные параллельно на нескольких серверах. Кластер Trino состоит из координатора и множества рабочих узлов. Пользователи подключаются к координатору с помощью любого клиента SQL-запросов. Координатор по REST API взаимодействует с рабочими узлами, которые получают доступ к подключенным источникам данных. Координатор отслеживает активность каждого рабочего узла и координирует выполнение SQL-запроса, создавая его логическую модель из набора этапов, которые преобразуются в ряд связанных задач, выполняемых в кластере рабочих узлов Trino. Именно координатор отвечает за синтаксический анализ SQL-операторов, планирование запросов и управление рабочими узлами Trino.
Обработка каждого SQL-запроса представляет собой stateful-операцию. Рабочая нагрузка управляется координатором и распределяется параллельно по всем рабочим процессам в кластере. Каждый узел запускает Trino в одном экземпляре JVM, а обработка дополнительно распараллеливается с использованием потоков.
Рабочий узел Trino отвечает за выполнение задач и обработку данных. Рабочие узлы извлекают данные из источников с помощью коннекторов и обмениваются промежуточными результатами друг с другом по REST API. Коннектор подключает Trino к источнику данных подобно драйверу. Это реализация SPI Trino, которая позволяет Trino взаимодействовать с ресурсом с помощью стандартного API. Координатор отвечает за получение результатов от рабочих узлов и возврат окончательных результатов клиенту.
Trino содержит несколько встроенных коннекторов: коннектор для JMX, системный коннектор, обеспечивающий доступ к встроенным системным таблицам, коннектор Hive и TPCH-коннектор для тестирования производительности. Многие вендоры реляционных СУБД и NoSQL-хранилищ предоставляют коннекторы для Trino.
Один и тот же коннектор может использоваться несколькими каталогами для доступа к двум разным экземплярам одной и той же базы данных. Например, если есть два кластера Hive, можно настроить два каталога в одном кластере Trino, оба из которых используют коннектор Hive, чтобы запрашивать данные из обоих кластеров Hive в рамках одного SQL-запроса.
Каталог Trino содержит схемы данных и ссылается на их источник через коннектор. Можно настроить каталог JMX для обеспечения доступа к информации JMX через коннектор JMX. При обращении к таблице Trino ее полное имя всегда находится в каталоге, которые определяются в файлах свойств конфигурации Trino. Каталог и схема данных определяют набор таблиц, к которым можно обращаться с помощью SQL-запросов. Правила сопоставления исходных данных с таблицами Trino определяется коннектором.
Trino выполняет операторы ANSI SQL, превращая их в запросы, которые выполняются в распределенном кластере. При этом Trino создает также план выполнения запроса, который затем распределяется по ряду рабочих узлов кластера. Оператор можно рассматривать как текст SQL, который передается в Trino, а запрос относится к конфигурации и компонентам, созданным для выполнения этого оператора. Запрос включает в себя этапы, задачи, разбиения, коннекторы и другие компоненты и источники данных, необходимые для получения результата.
Иерархия этапов, составляющих запрос Trino, напоминает дерево: каждый запрос имеет корневую стадию, которая отвечает за агрегирование выходных данных с других этапов. Этапы использует координатор для моделирования плана распределенного запроса, но они сами выполняются не на рабочих узлах Trino, а в источниках данных. Этап состоит из задач, которые выполняется параллельно набором драйверов, имеют свои входы выходы. Задачи работают с разделами большего набора данных. Когда Trino планирует запрос, координатор запрашивает у коннектора список всех разделений, доступных для таблицы, и отслеживает, на каких машинах выполняются какие задачи.
Задачи содержат один или несколько параллельных драйверов. Драйверы воздействуют на данные и комбинируют операторы для создания выходных данных, которые затем агрегируются задачей, а затем доставляются другой задаче на другом этапе. Драйвер — это последовательность экземпляров операторов, физический набор операторов в памяти. Это самый низкий уровень параллелизма в архитектуре Trino, который имеет один вход и один выход.
Оператор потребляет, преобразует и производит данные. Например, сканирование таблицы извлекает данные из коннектора и создает данные, которые могут быть использованы другими операторами, а оператор фильтра потребляет данные и создает подмножество, применяя предикат к входным данным. Обмены передают данные между узлами Trino для разных этапов запроса. Задачи создают данные в выходной буфер и потребляют данные из других задач с помощью клиента обмена. Разобравшись с Trino, далее рассмотрим архитектуру платформы Chango.
Lakehouse на Chango: архитектура кластера платформы данных
Кластер Chango включает шлюз Trino, API данных и операторы на узлах Kubernetes, которые можно удалять и создавать динамически. Стоимость использования Chango представляет собой сумму стоимости всех его узлов компонентов и стоимости узлов Trino. Стоимость вычислительного экземпляра рассчитывается ежечасно, а стоимость хранилища объектов и балансировщика нагрузки – ежемесячно.
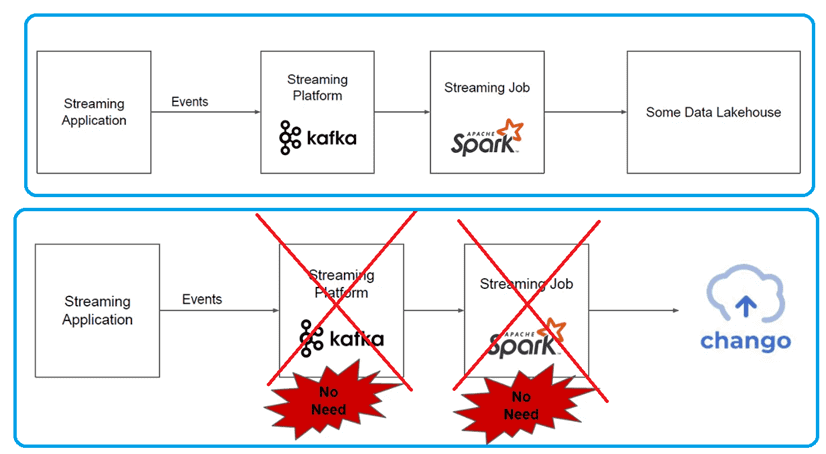
В большинстве Lakehouse-платформ для вставки потоковых событий в хранилища данных используется Kafka и дополнительные задания Spark Structured Streaming. В Chango, состоящим из уровня приема данных и слоя запросов, это также поддерживается. Внешние данные, например из файлов CSV и XLS, JSON-документов и пр., будут вставлены для изменения через API данных, с использованием Kafka и заданий Spark Structured Streaming на уровне приема данных. Все данные, сохраненные в виде таблиц Iceberg в Chango, будут запрашиваться через кластеры Trino, на которые запросы Trino будут направляться шлюзом Trino на слое запросов.
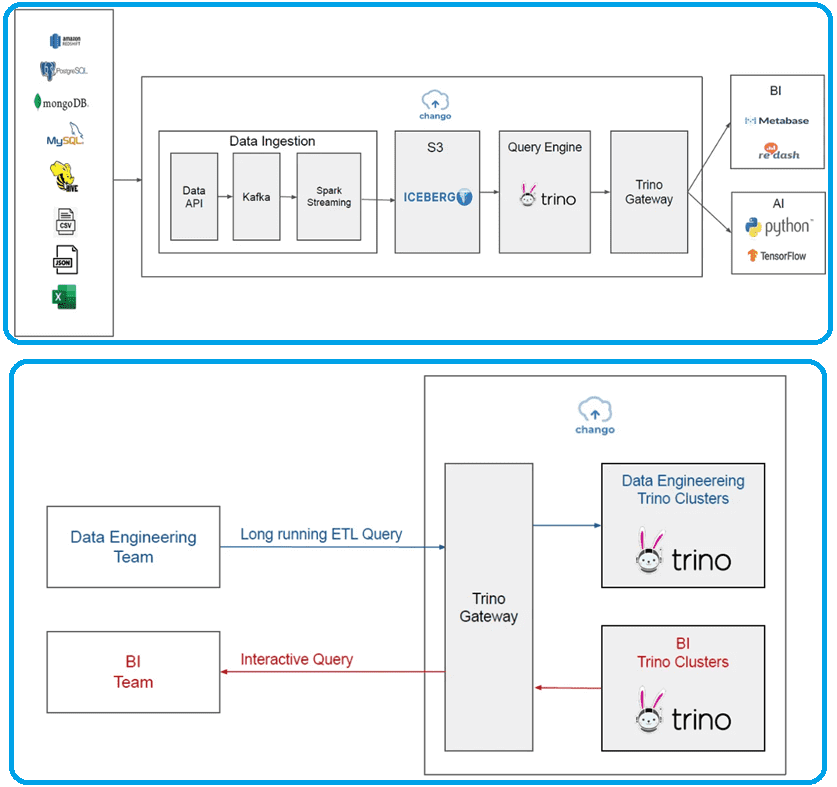
Однако, благодаря наличию API данных, нет необходимости в дополнительном развертывании кластера Kafka и заданий Spark Structured Streaming – в Chango они присутствуют по умолчанию на уровне приема данных для сбора входящих событий потоковой передачи и сохранения их в Lakehouse. Разработчику потоковых приложений просто нужно вызвать метод класса Java библиотеки Сhango, чтобы вставить потоковые события в Lakehouse.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
12 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Узнайте больше подробностей по проектированию и поддержке современных дата-архитектур в проектах аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

