 1319
1319 
Содержание
Как на самом деле работает приложение-продюсер Apache Kafka: разбираемся с конфигурациями и составляем UML-диаграмму последовательности системных вызовов при публикации сообщений в топик.
Как работает продюсер Kafka
Когда разработчик пишет приложение-продюсер, которое публикует сообщение в топик Apache Kafka, он использует методы специальных библиотек, таких как kafka-python и пр. Достаточно только создать экземпляры нужных классов. Пример такого скрипта смотрите в нашей новой статье. Например, в следующем участке кода, который можно запустить в нескольких ячейках Google Colab, устанавливаются необходимые библиотеки и импортируются модули:
####################ячейка в Google Colab №1 - установка и импорт библиотек############################ #установка библиотек !pip install kafka-python #импорт модулей from kafka import KafkaProducer
Далее создадим экземпляр класса продюсера, задав параметры подключения к инстансу Kafka, развернутого в облачной платформе Upstash. О том, как создать свой инстанс в Upstash, а также написать свой Python-продюсер и потребитель, я подробно рассказывала в статье блога нашей Школы прикладного бизнес-анализа.
##################ячейка в Google Colab №2 - публикация сообщений в Kafka##################
# объявление продюсера Kafka
producer = KafkaProducer(
bootstrap_servers=['........здесь взять название своего сервера.upstash.io:9092'],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username='.........здесь имя пользователя, взятое из upstash',
sasl_plain_password='..........здесь пароль для этого пользователя',
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
После задания ключа партиционирования (key) и определения полезной нагрузки (data) для отправки сообщения в топик под названием InputsTopic с 3-мя разделами вызывается метод send(), который есть у класса продюсер:
#публикуем данные в Kafka
future = producer.send('InputsTopic', value=data, key=mes_key)
record_metadata = future.get(timeout=60)
print(f' [x] Sent {record_metadata}')
Продюсер является потокобезопасным, и совместное использование одного экземпляра продюсера между потоками быстрее, чем наличие нескольких экземпляров. Продюсер состоит из пула буферного пространства, содержащего записи, которые еще не были переданы на сервер, а также фонового потока ввода-вывода (Producer Network Thread), который отвечает за преобразование этих записей в запросы и их передачу в кластер Kafka. Как выполняется этот процесс, смотрите здесь и здесь.
Метод send() является асинхронным: при вызове он добавляет запись в буфер ожидающих отправки записей и сразу же возвращается, позволяя продюсеру группировать отдельные записи для повышения эффективности. О том, как Kafka обеспечивает транзакционную атомарнонсть публикации сообщений, читайте в нашей новой статье.
Под капотом этих методов библиотеки kafka-python происходит следующее:
- Экземпляр класса Producer получает вызов метода send(), в параметрах которого указан топик, данные сообщения и другие параметры, например, ключ партиционирования (key). В вышеприведенном примере ключ партиционирования задан параметром key метода send(). Сообщения с одним и тем же ключом помещаются в один и тот же раздел. Это удобно для группировки сообщений. Например, чтобы события поведения одного и того же пользователя. Если ключ партиционирования не задан, сообщения будут записываться в существующие разделы топика по принципу циклического перебора.
- Как только раздел определен, продюсер передает данные в сетевой поток Producer Network Thread, который отвечает за преобразование этих записей в запросы и их передачу в кластер Kafka.
- Сетевой поток Producer Network Thread ищет лидера раздела, чтобы отправить ему сообщение, т.к. именно лидер раздела позволяет записывать в Kafka новые данные, а подписчики реплицируют их. Для этого Producer Network Thread получает метаданные от списка брокеров Kafka, заданных в конфигурации bootstrap_servers, где задан набор сокетов узлов кластера, т.е. их IP-адреса с номерами портов, обычно равных 9092. При развертывании облачного инстанса в Upstash список серверов Kafka задается в виде виртуального адреса хоста, например, merry-perry-kafka.upstash.io:9092. По сути, bootstrap.servers — это первые серверы Kafka, с которыми продюсер должен связаться для получения конфигурации кластера. Подробнее о том, как клиенты Kafka общаются с серверами, мы писали здесь.
- Получив информацию о лидере раздела, продюсер добавляет сообщение в локальную очередь.
- Когда размер этой очереди превысит значение конфигурации batch.size или истечет тайм-аута задержки отправки, заданный в конфигурации ms, пакет сообщений из локальной очереди отправляется лидеру раздела, расположенного на брокере — одном из узлов кластера. В рассмотренном примере параметр linger_ms в методе producer.send() не задан.
- Если продюсер ожидает подтверждения о репликации сообщения с лидера раздела по всем подписчикам, информация о подтверждении принимается от синхронизированных реплик (ISR), и ответ возвращается в сетевой поток продюсера. В нашем рассмотренном примере конфигурация acks при объявлении продюсера не задана, а потому равна значению по умолчанию 1. Это означает, что продюсер ожидает, только когда лидер раздела запишет запись только в свой локальный журнал, не дожидаясь подтверждения от всех подписчиков. В этом случае, если лидер выйдет из строя сразу после подтверждения записи, но до того, как подписчики реплицируют ее, данные будут потеряны. Поэтому для повышения надежности можно задать конфигурации acks значение all, чтобы продюсер ждал, пока все подписчики реплицируют отправленные лидеру данные и подтвердят это. Это самая надежная гарантия доступности: запись не будет потеряна, пока хотя бы одна синхронизированная реплика остается активной на любом брокере. Однако, такая настройка снижает общее быстродействие системы из-за необходимости ожидания подтверждений.
- Сетевой поток продюсера выполняет обратный вызов (callback), выводя информацию о метаданных, что задано в строке print(f’ [x] Sent {record_metadata}’).
Визуализируем это в виде UML-диаграммы последовательности:
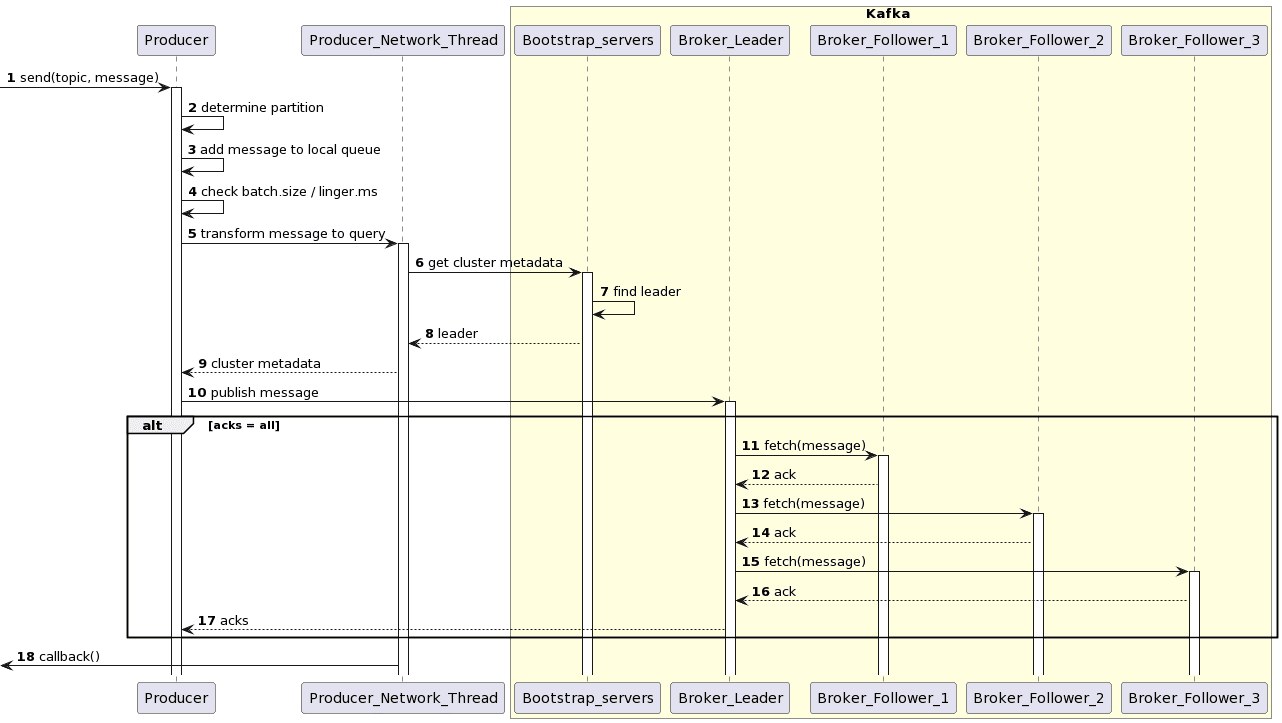
Эта UML-диаграмма последовательности была создана в PlantUML с помощью следующего скрипта:
@startuml skinparam packageStyle rectangle participant Producer participant Producer_Network_Thread autonumber box Kafka #LightYellow participant Bootstrap_servers participant Broker_Leader participant Broker_Follower_1 participant Broker_Follower_2 participant Broker_Follower_3 -> Producer : send(topic, message) activate Producer Producer -> Producer : determine partition Producer -> Producer: add message to local queue Producer -> Producer: check batch.size / linger.ms Producer -> Producer_Network_Thread : transform message to query activate Producer_Network_Thread Producer_Network_Thread -> Bootstrap_servers: get cluster metadata activate Bootstrap_servers Bootstrap_servers -> Bootstrap_servers : find leader Bootstrap_servers --> Producer_Network_Thread : leader Producer_Network_Thread --> Producer : cluster metadata Producer -> Broker_Leader : publish message activate Broker_Leader alt acks = all Broker_Leader -> Broker_Follower_1 : fetch(message) activate Broker_Follower_1 Broker_Follower_1 --> Broker_Leader : ack Broker_Leader -> Broker_Follower_2 : fetch(message) activate Broker_Follower_2 Broker_Follower_2 --> Broker_Leader : ack Broker_Leader -> Broker_Follower_3 : fetch(message) activate Broker_Follower_3 Broker_Follower_3 --> Broker_Leader : ack Broker_Leader --> Producer : acks end <- Producer_Network_Thread : callback() end box @enduml
В следующий раз мы заглянем под капот потребителя, разобрав системные вызовы и конфигурации класса Consumer в клиентской библиотеке kafka-python, а также составим подобную UML-диаграмму последовательности. А как Kafka справляется со сбоями приложений-продюсера, которые приводят к проблеме разделенного мозга в распределенной системе, читайте здесь.
Больше деталей про администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Администрирование кластера Kafka
- Apache Kafka для инженеров данных
- Администрирование Arenadata Streaming Kafka
Источники

